说明
本文的目标是:在windows下,使用idea编写spark任务,并可直接右键运行提交至远程Linux Spark集群上,不需要打包后再拷贝至远程Linux服务器上,再使用命令运行。
准备工作
- 软件
- win10
- jdk1.7(windows版本:1.7.0_79)
- scala2.11.8(windows版本:scala-2.11.8.zip)
- idea 2016.3.2(windows版本:ideaIU-2016.3.2.exe)
- hadoop2.7.3(linux版本:hadoop-2.7.3.tar.gz)
- spark2.0.2(linux版本:spark-2.0.2-bin-hadoop2.7.tgz)
- idea scala插件(scala-intellij-bin-2016.3.4.zip,https://plugins.jetbrains.com/idea/plugin/1347-scala)
- winutil.exe等(winutil下载地址)
- maven3.3.9(windows版本:apache-maven-3.3.9-bin.zip)
- 搭建Spark集群
分布式Spark集群搭建 - 配置windows环境变量
- jdk(windows版本) JAVA_HOME
- scala(windows版本) SCALA_HOME
- hadoop(linux版本) HADOOP_HOME
- maven(windows版本) MAVEN_HOME
注意:以上环境变量均在windows下配置,括号中强调了软件包的平台版本。
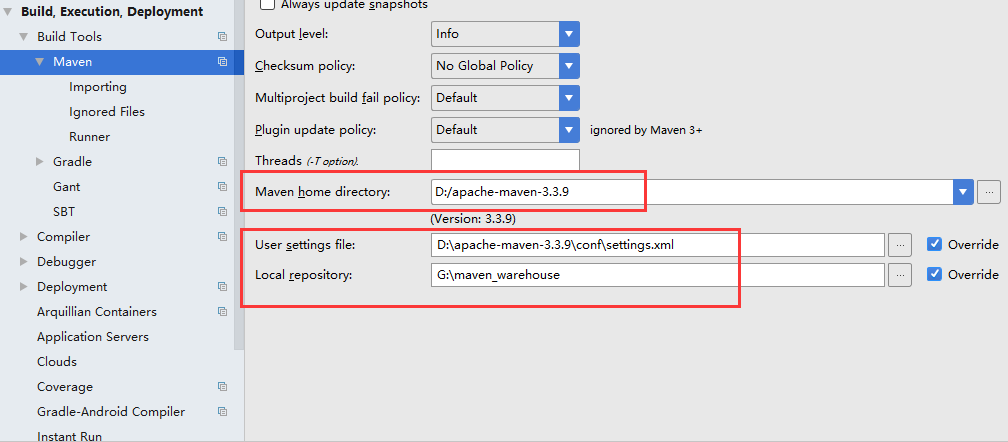
配置idea
maven配置:
修改setting.xml
修改%MAVEN_HOME%下的conf/setting.xml为阿里云镜像1
2
3
4
5
6
7在mirrors节点添加:
<mirror>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
<mirrorOf>central</mirrorOf>
</mirror>修改idea的maven配置
主要是为了加快建立maven项目时的速度
scala pluin配置
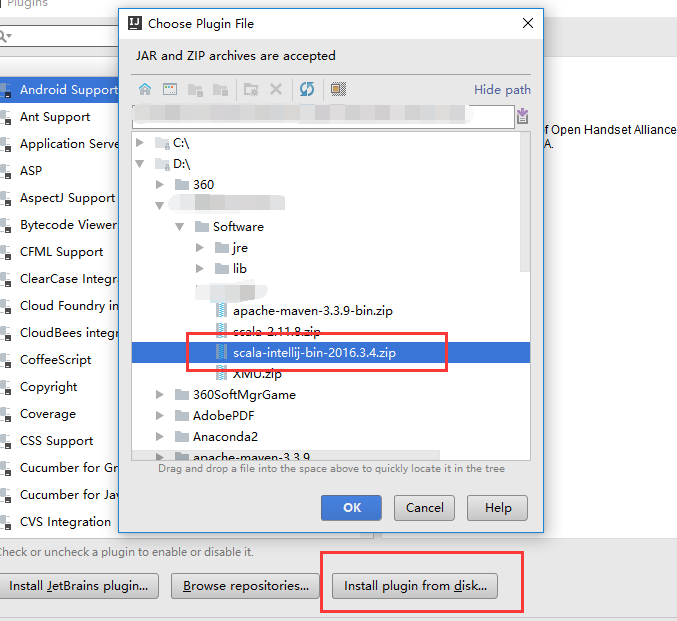
开发流程
- 新建MAVEN+SCALA项目
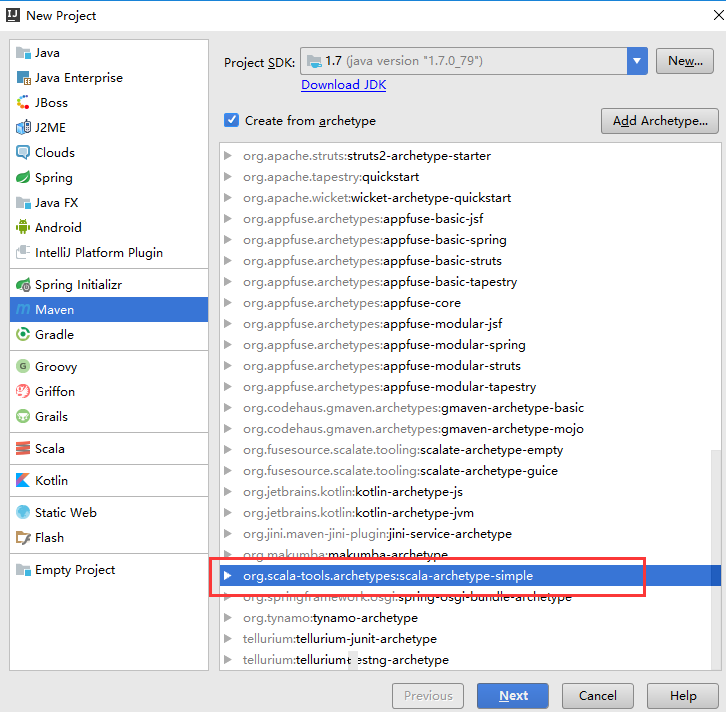
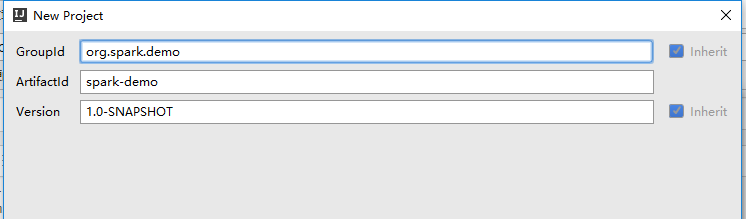
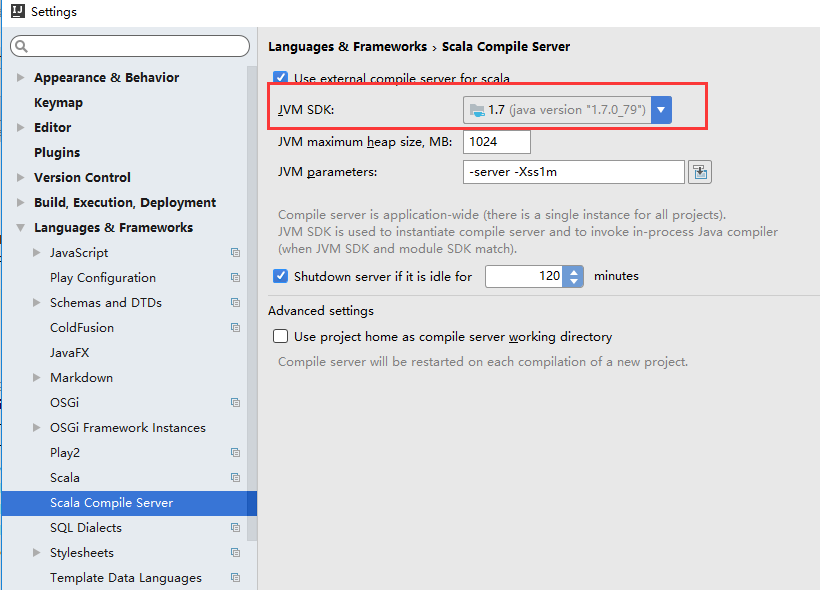
配置JDK、SCALA
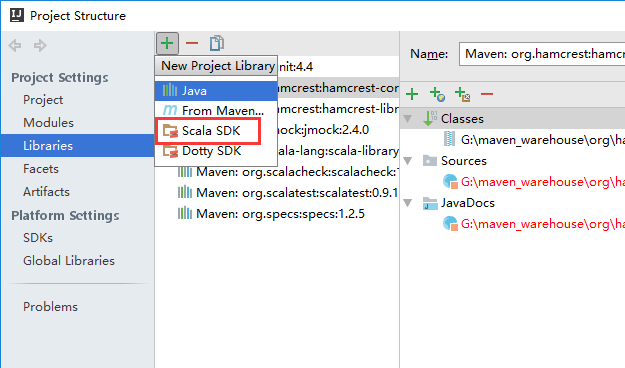
添加POM依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14<properties>
<spark.version>2.0.2</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>编写代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import org.apache.spark.{SparkConf, SparkContext}
import scala.math.random
object SparkPi {
def main(args:Array[String]):Unit = {
val conf = new SparkConf().setAppName("Spark Pi").setMaster("spark://172.16.21.121:7077")
.setJars(List("E:\\idea-workspace\\spark-practice\\out\\artifacts\\spark_practice_jar\\spark-practice.jar"));
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}其中setMaster为:spark主节点的地址。setjars为下面步骤生成的jar包在window路径下的目录
添加输出sparkdemo.jar
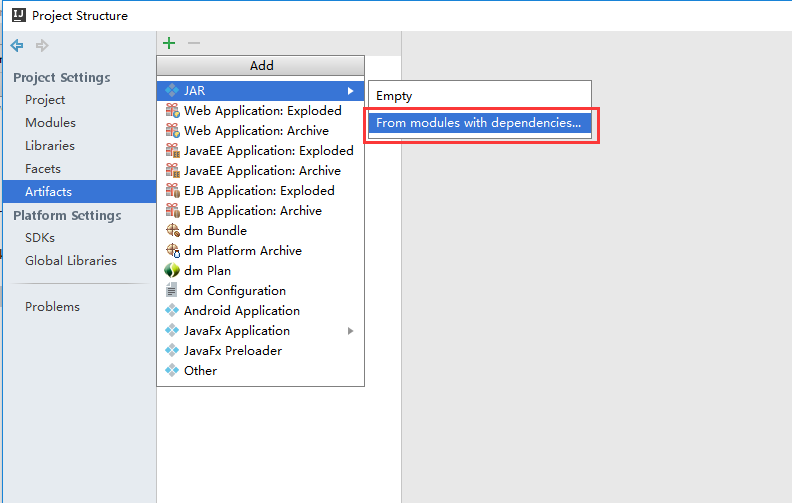
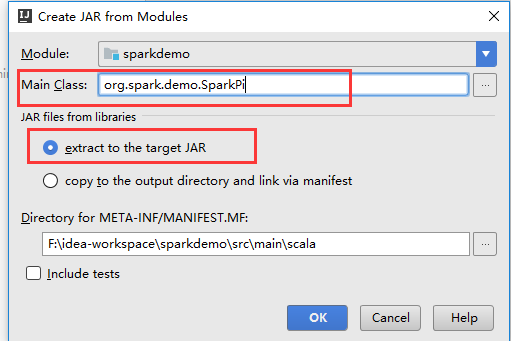
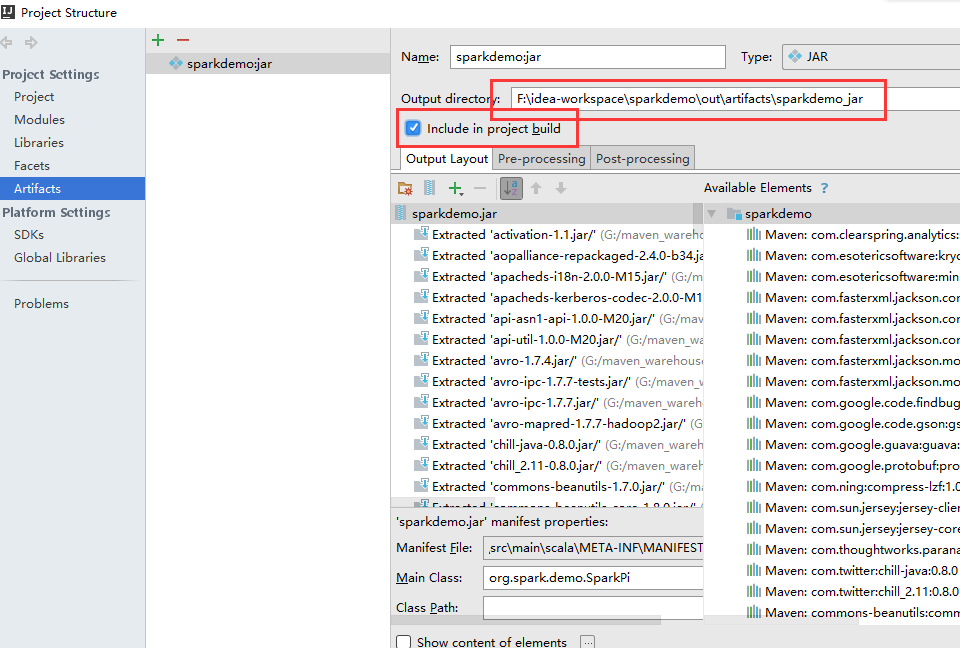
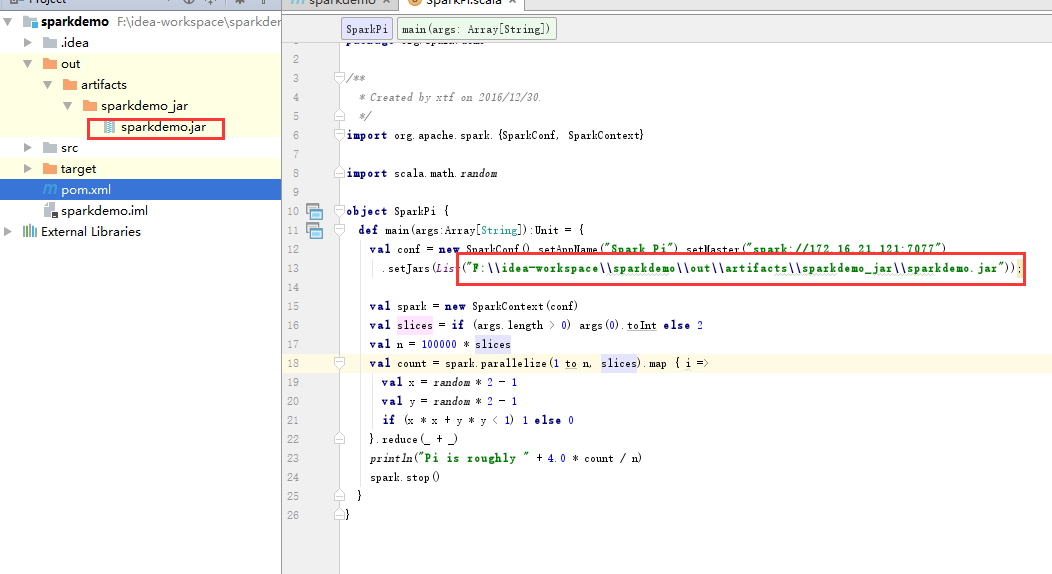
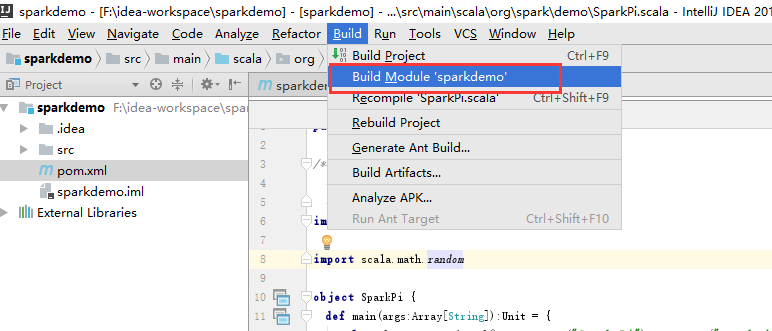
编译代码
删除输出的sparkdemo.jar中META-INF中多余文件
只保留MANIFEST.MF和MAVEN文件夹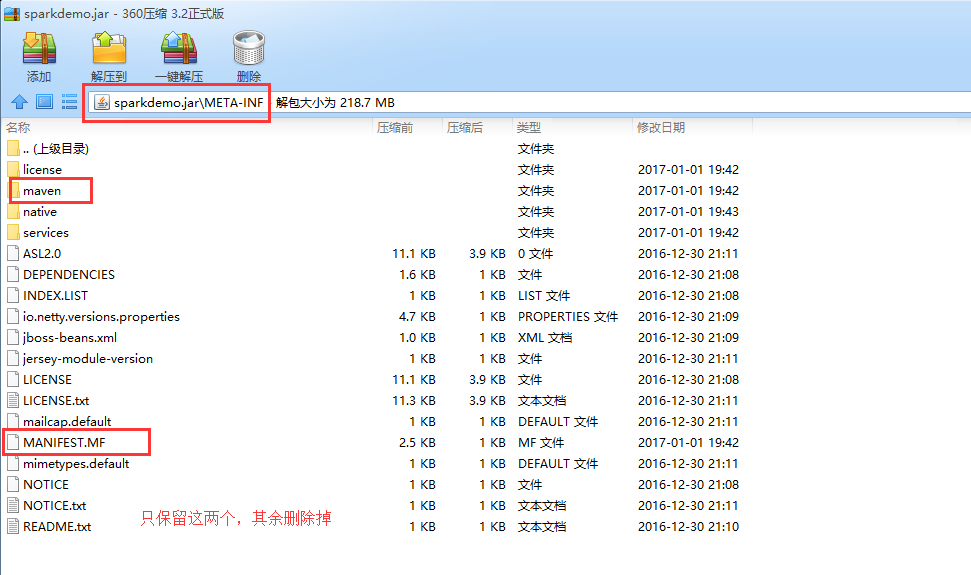
include in build勾掉
防止右键运行的时候,重新输出,导致mete-inf又恢复了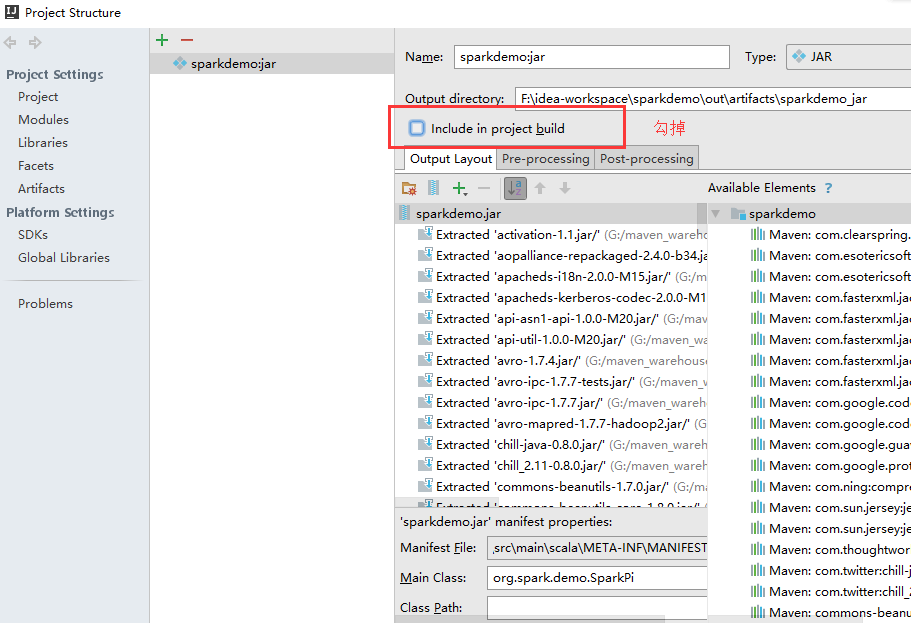
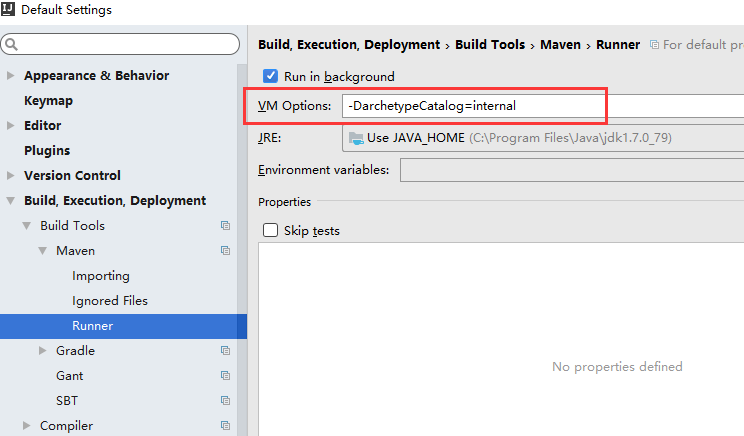
设置VM参数
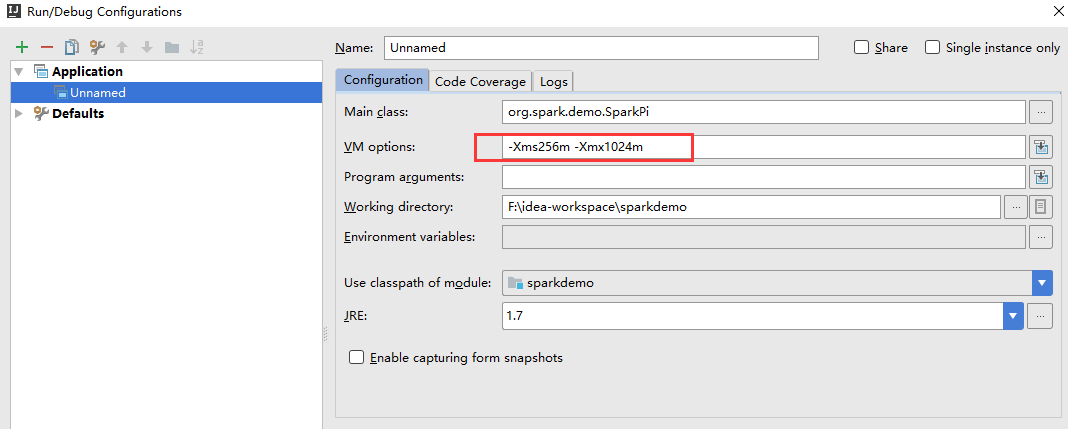
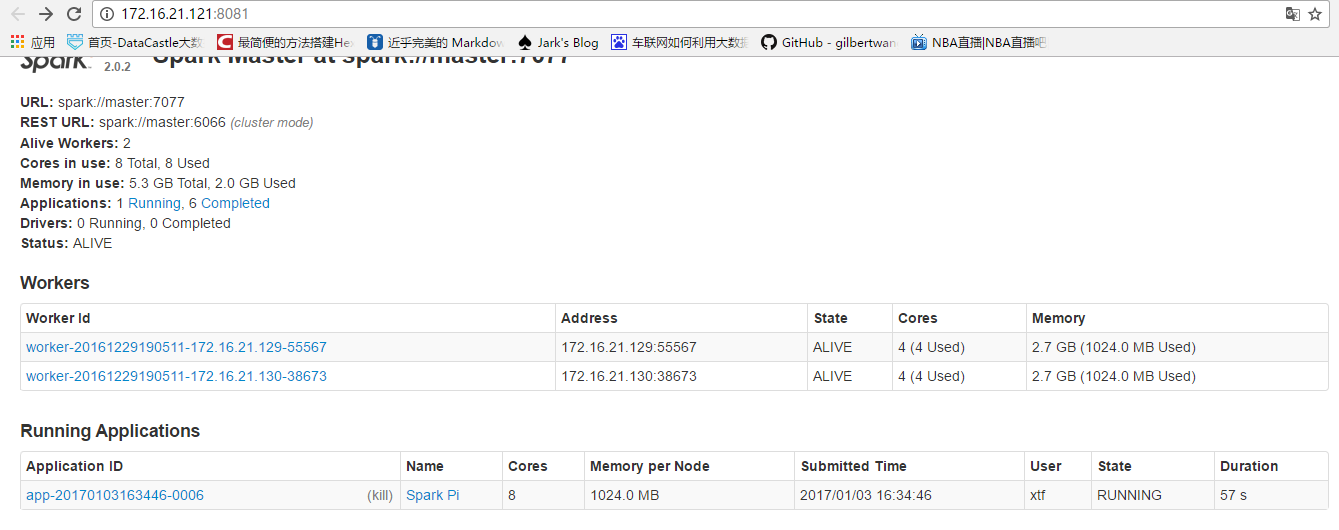
- 右键运行
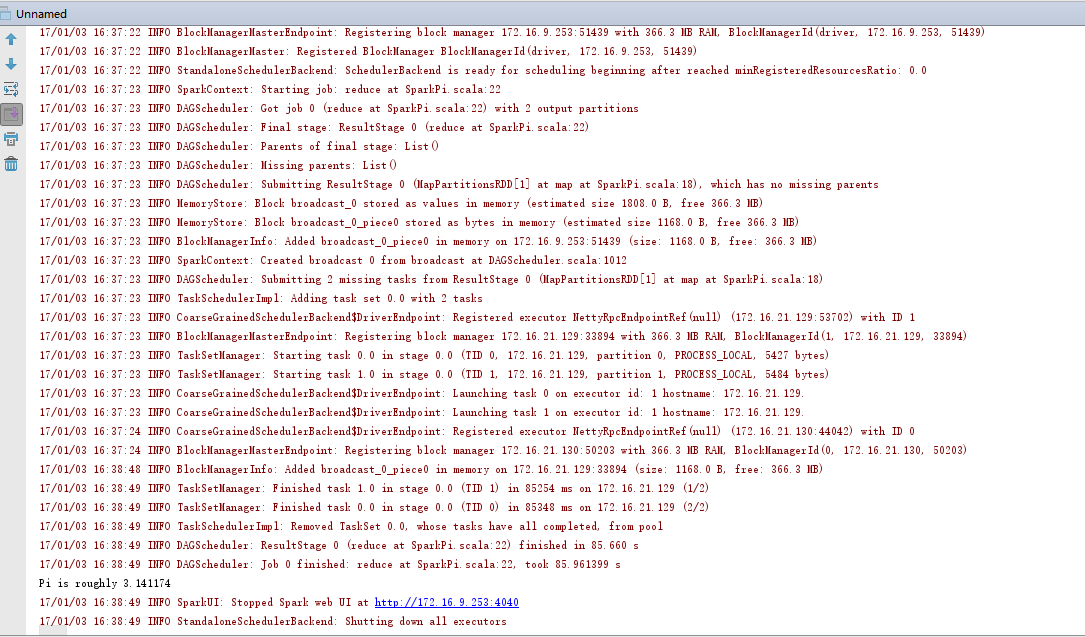
- 运行时可查看web控制台