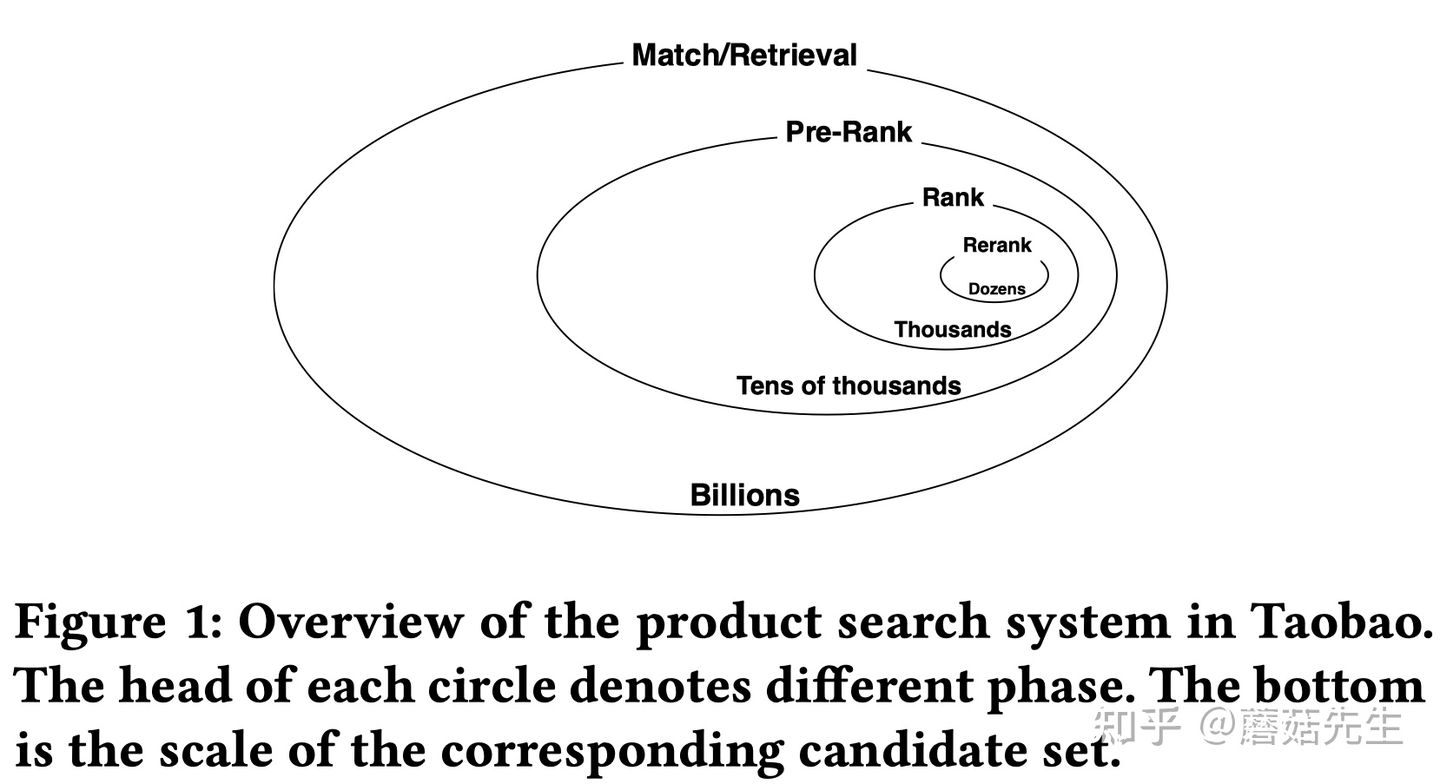
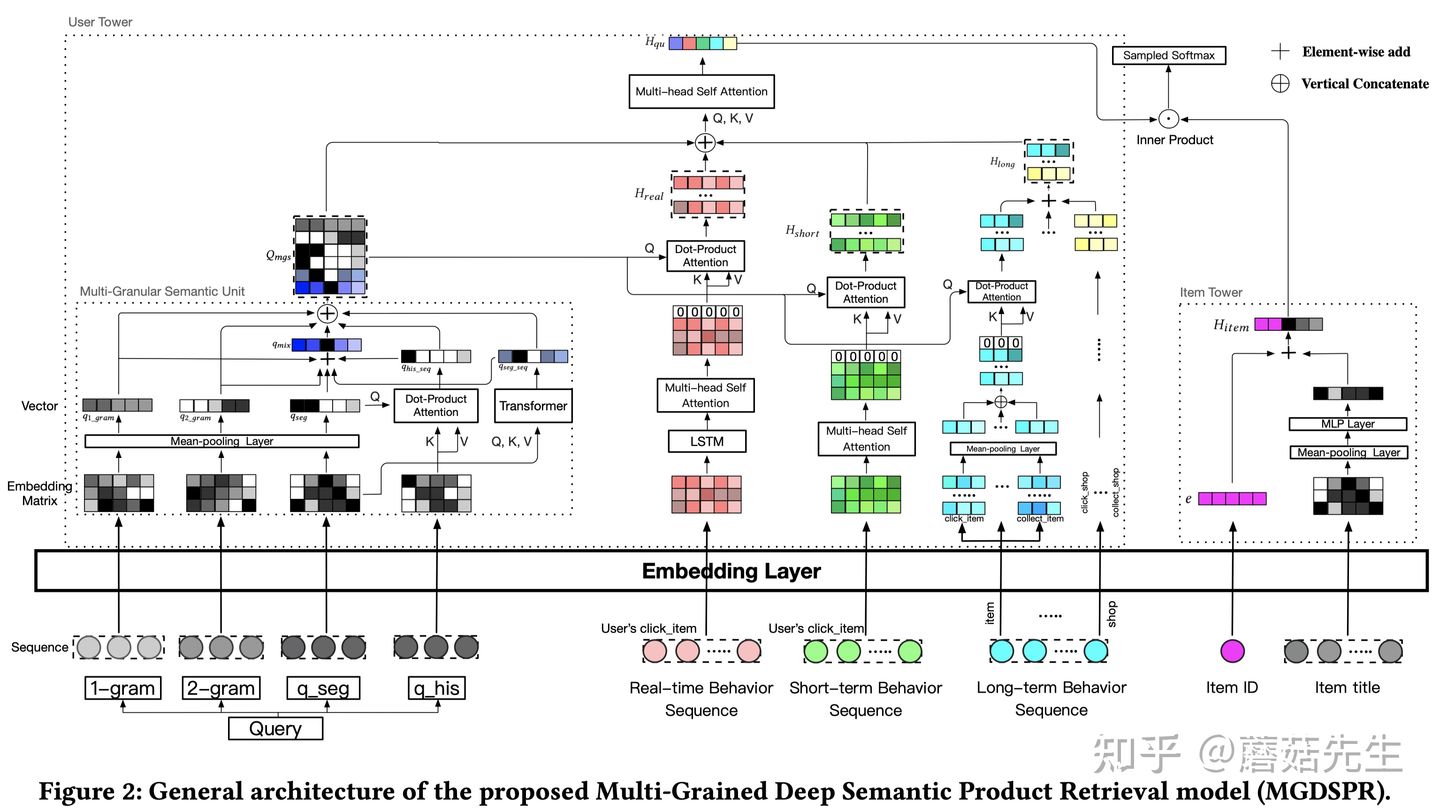
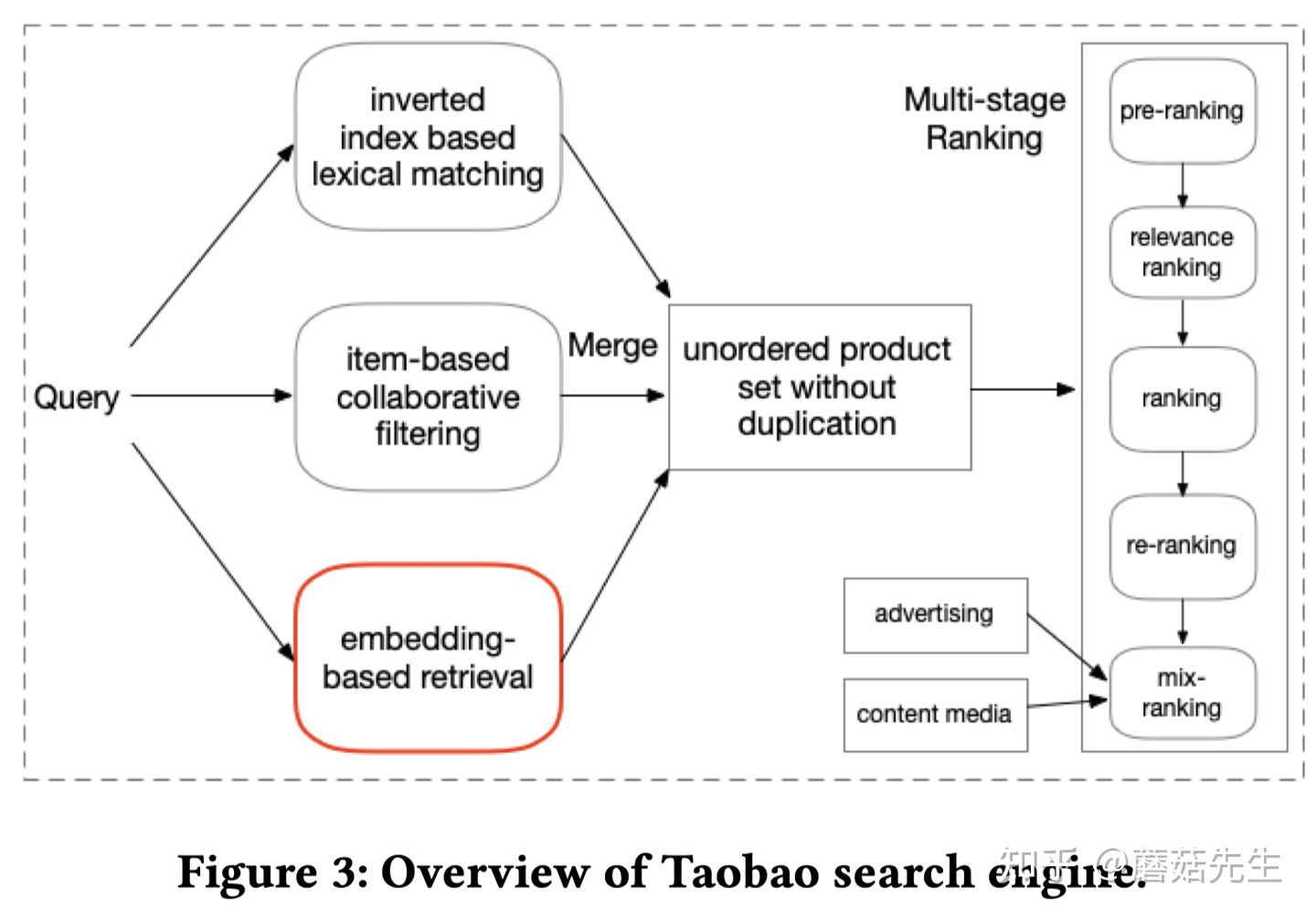
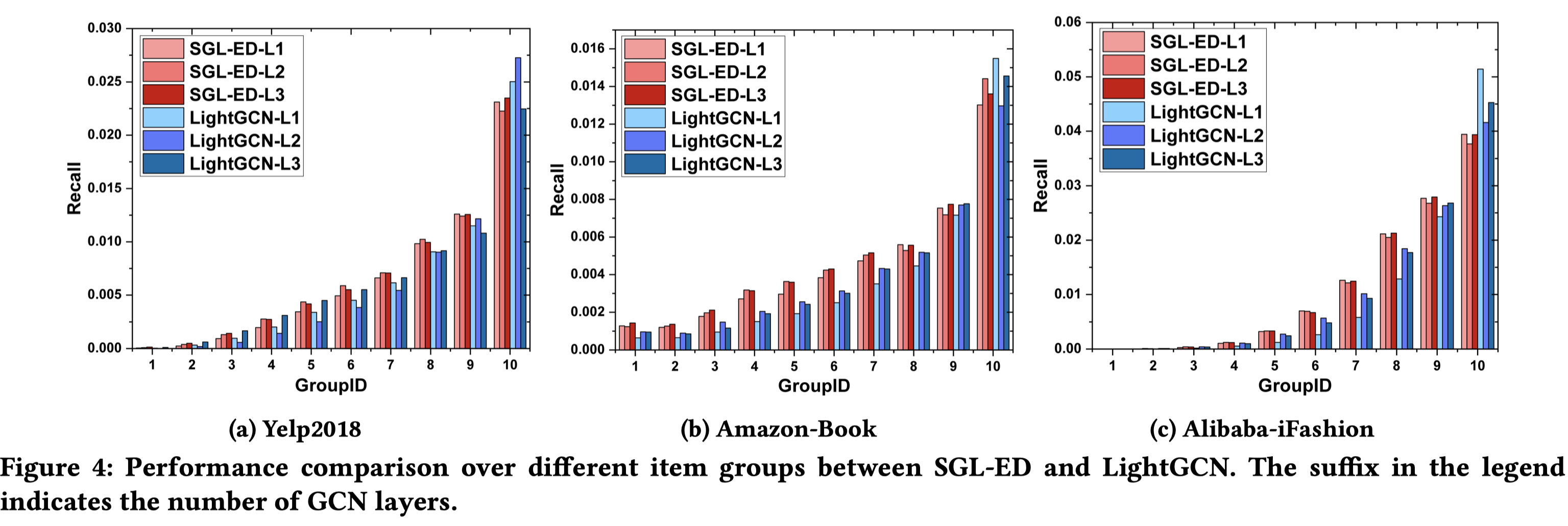
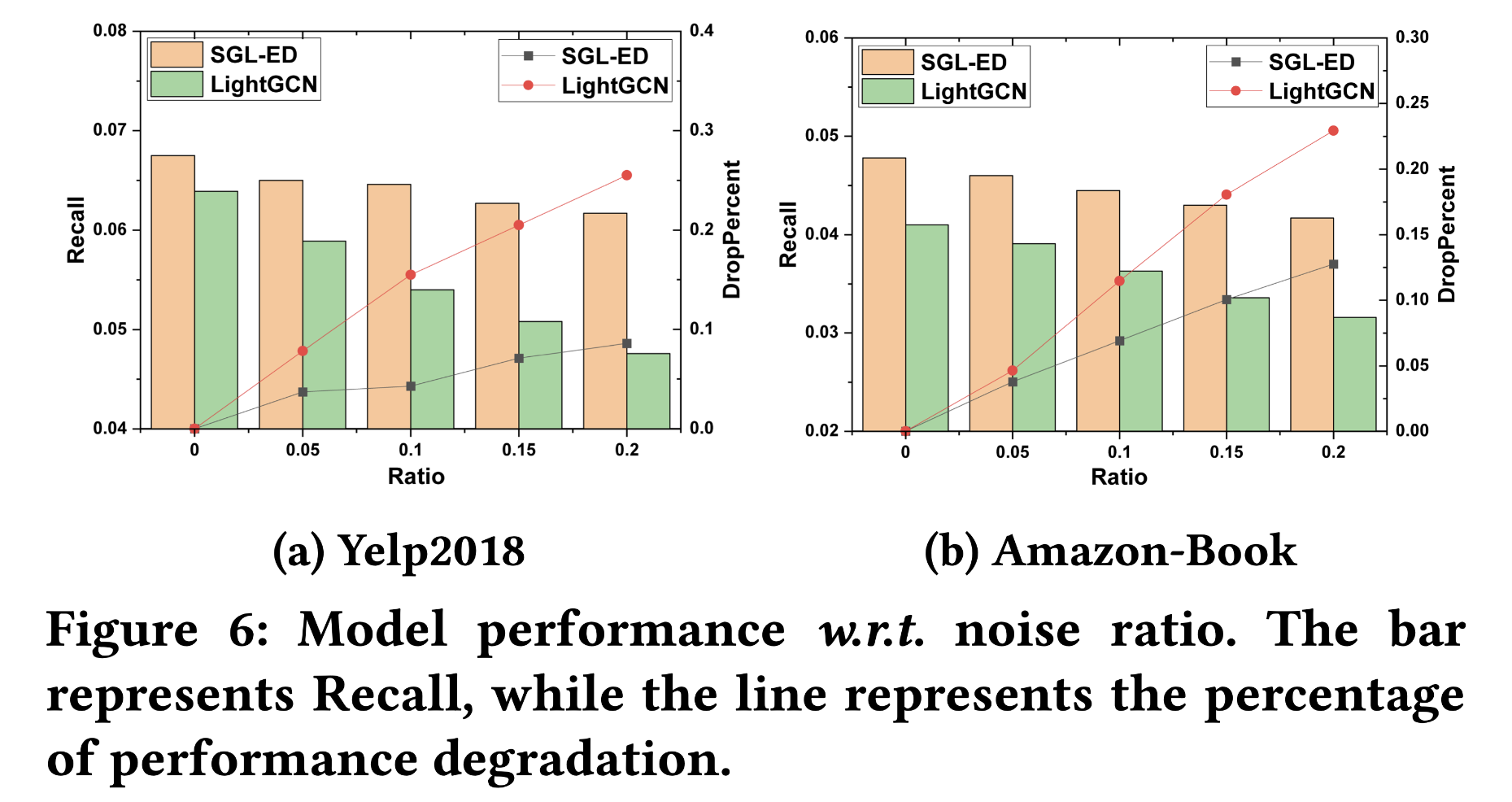
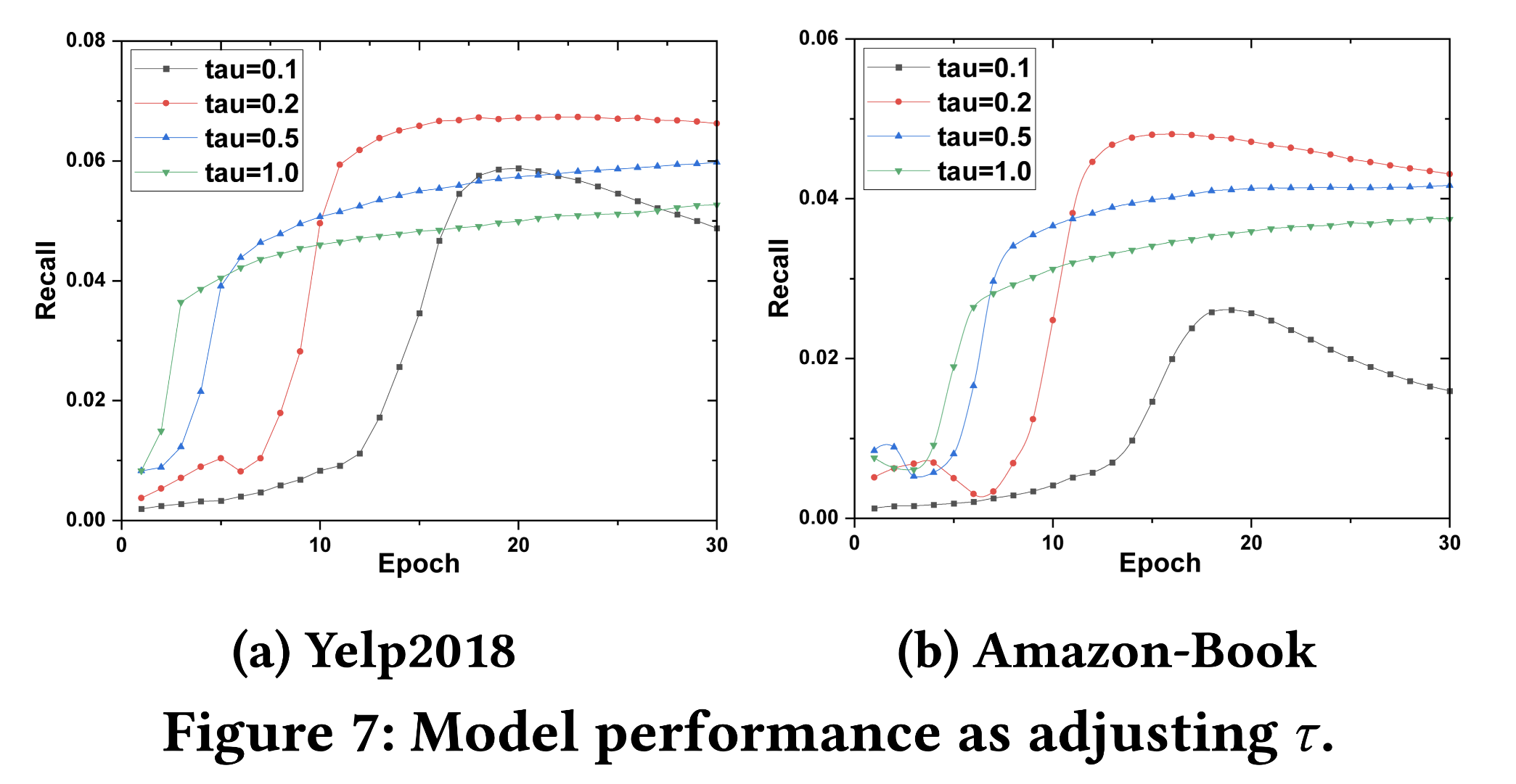
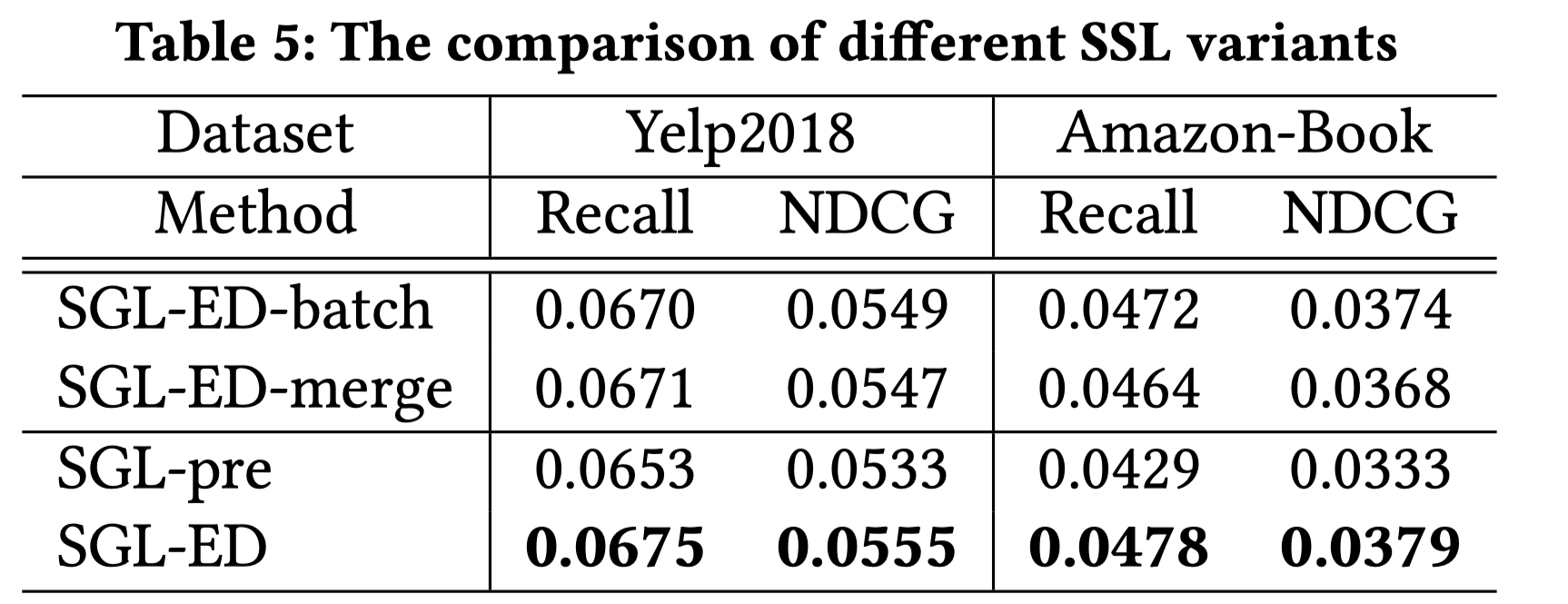
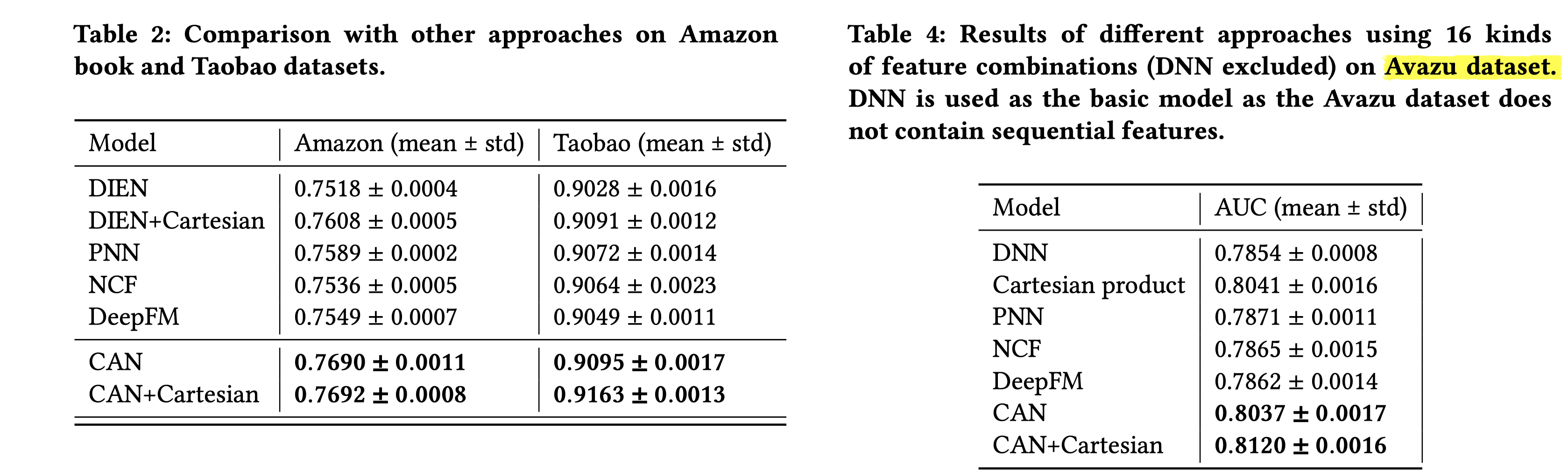
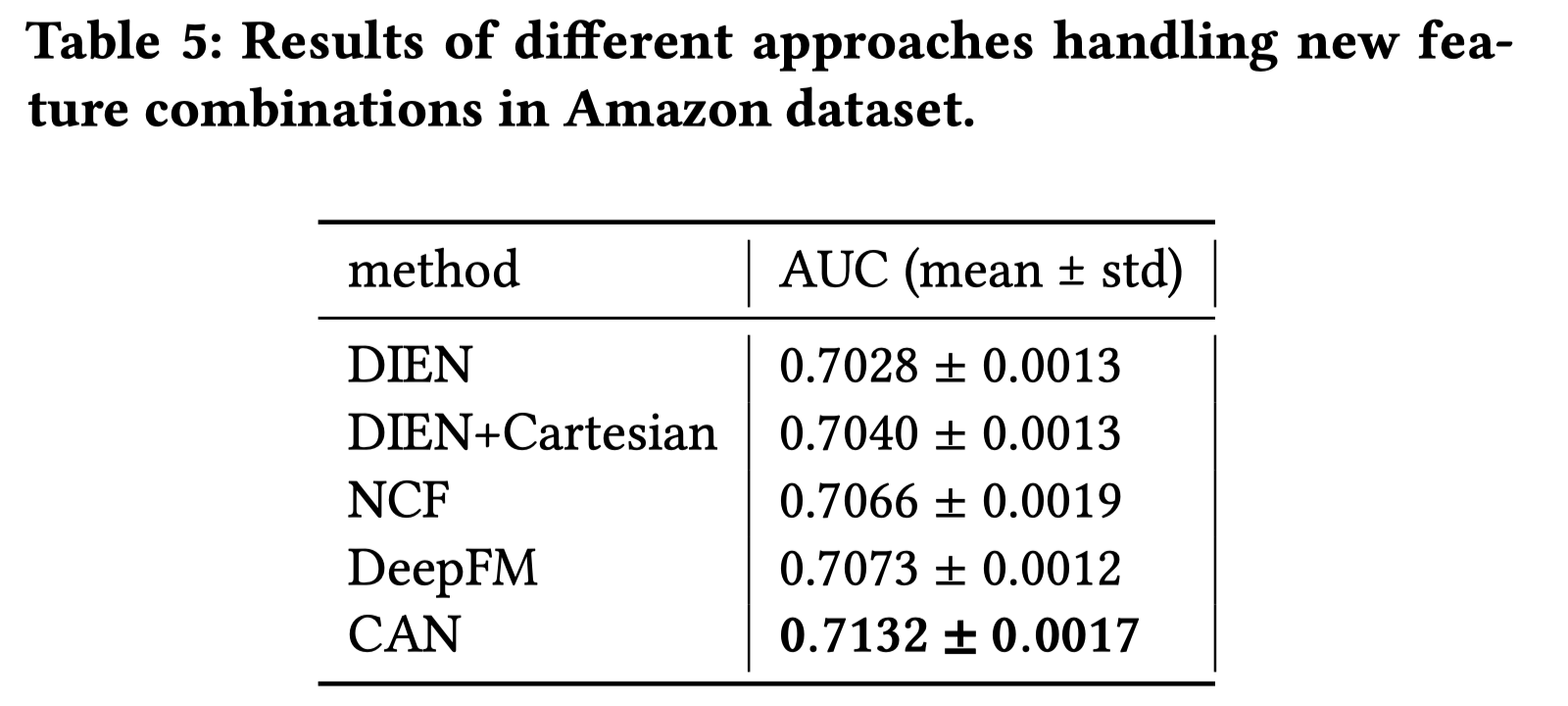
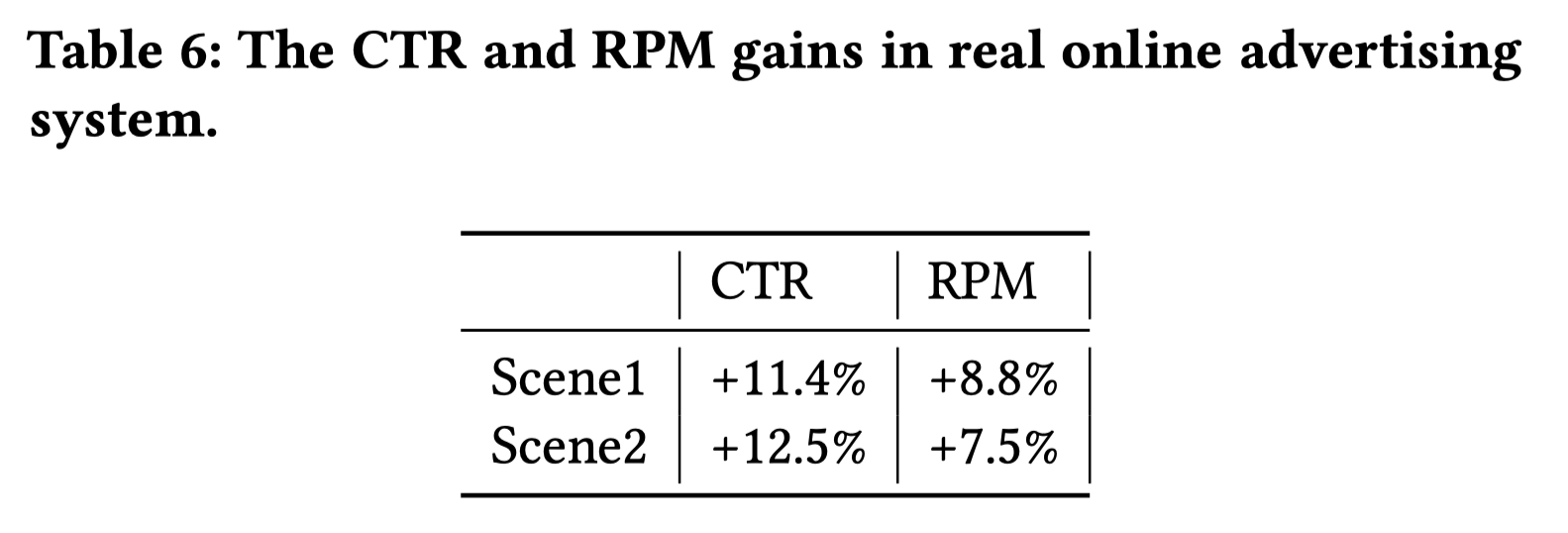
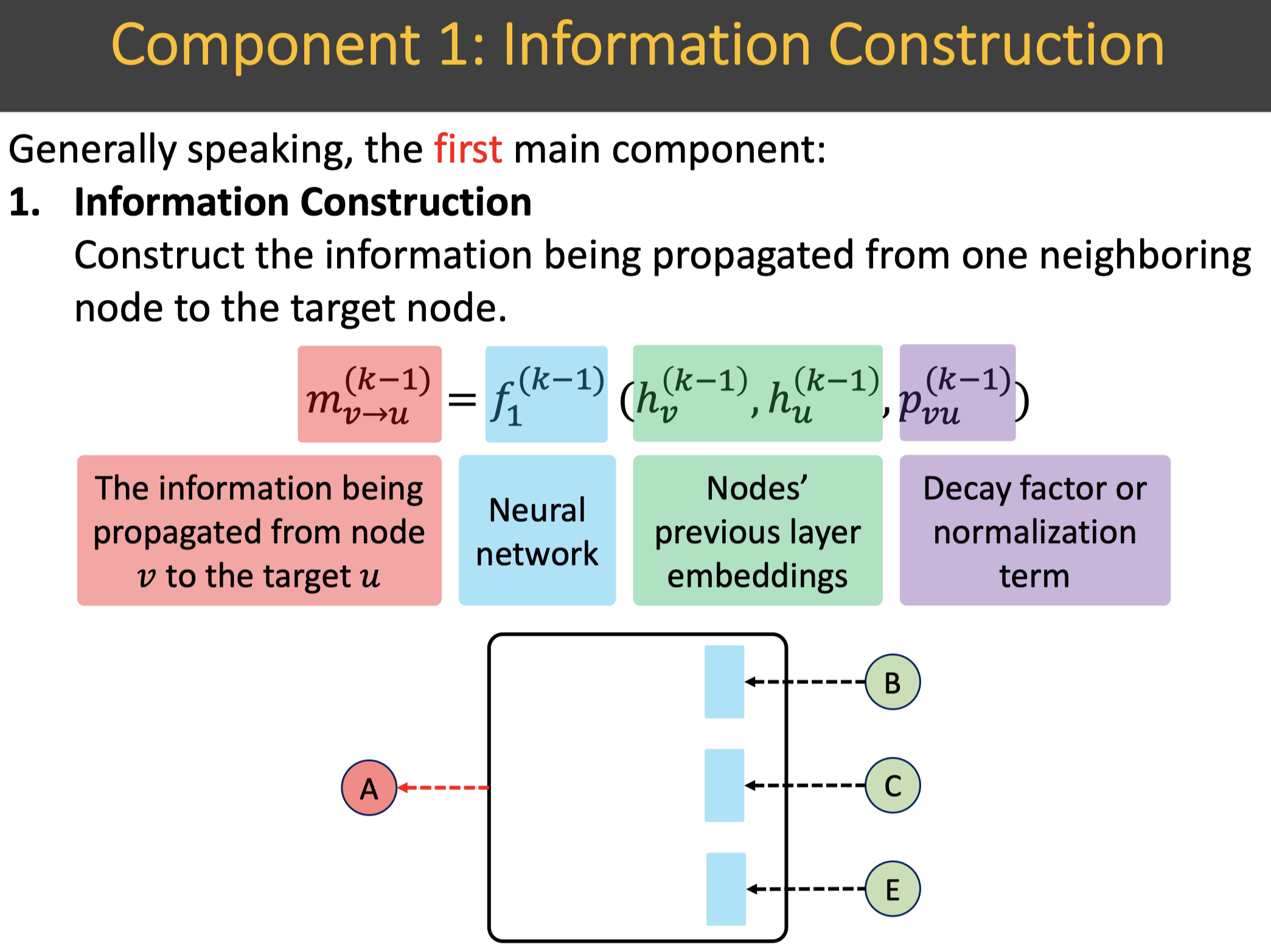
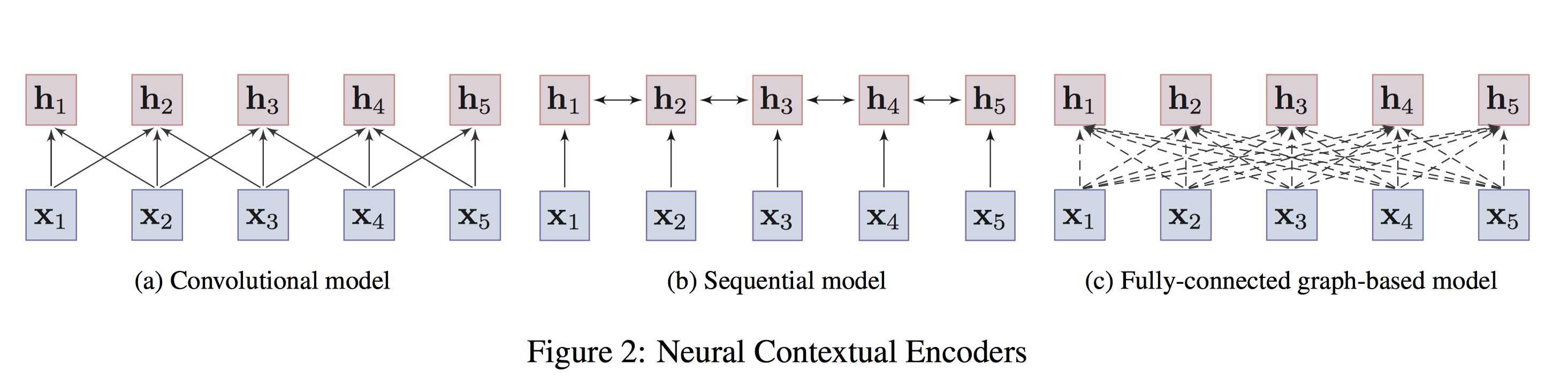
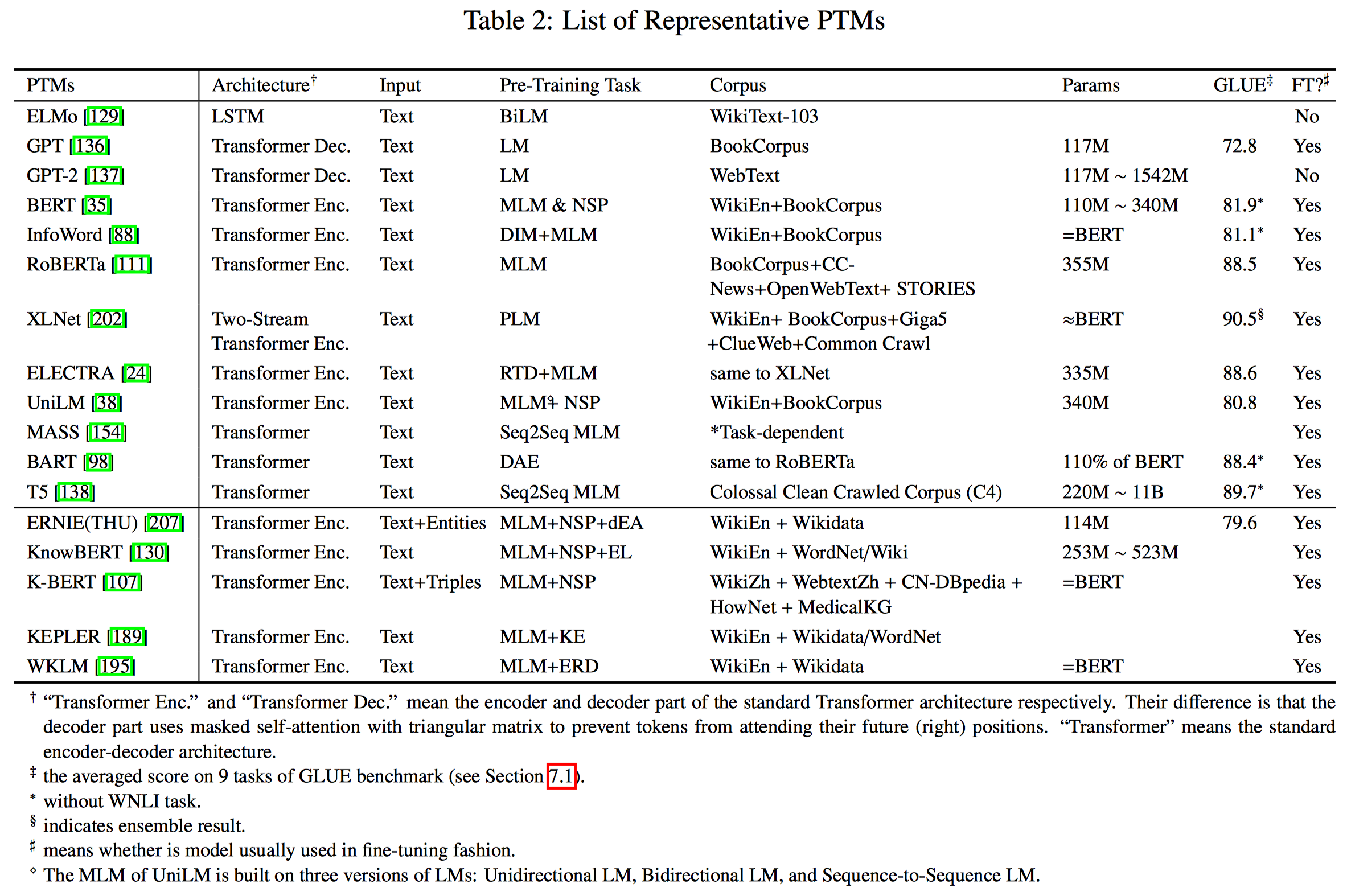
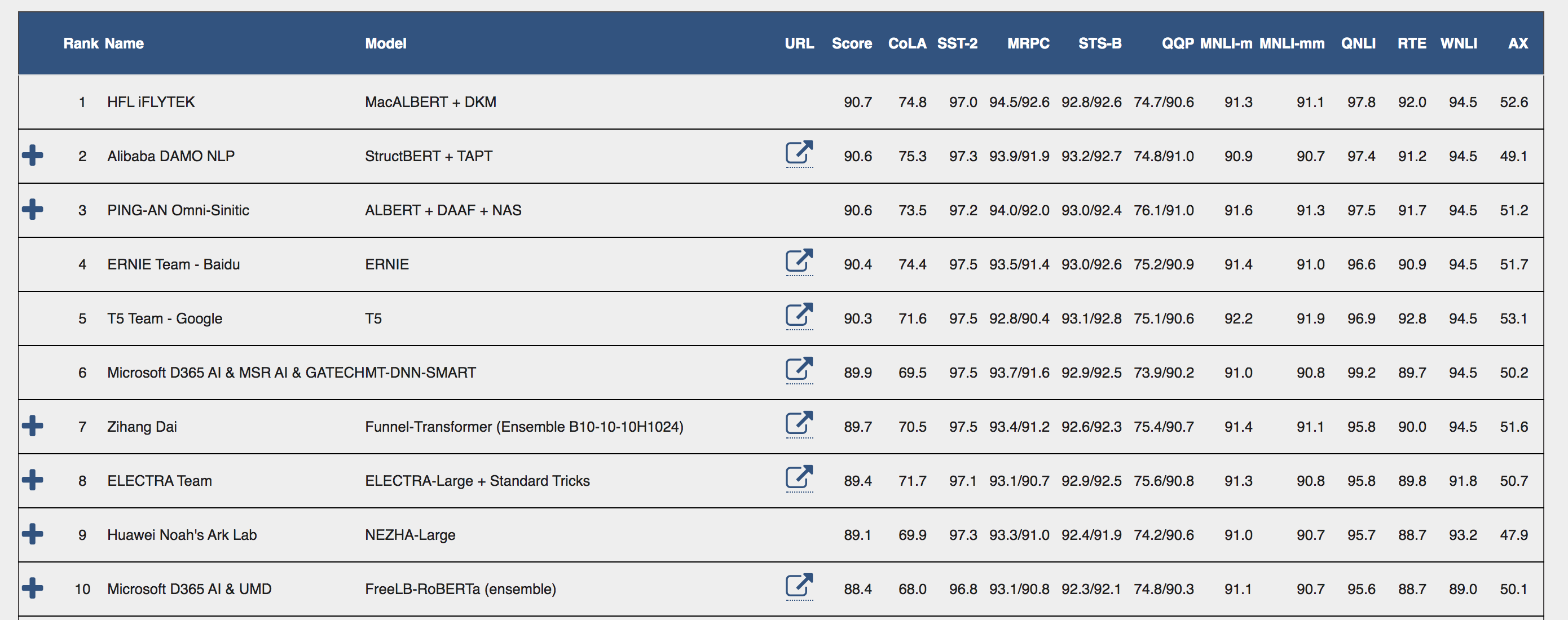
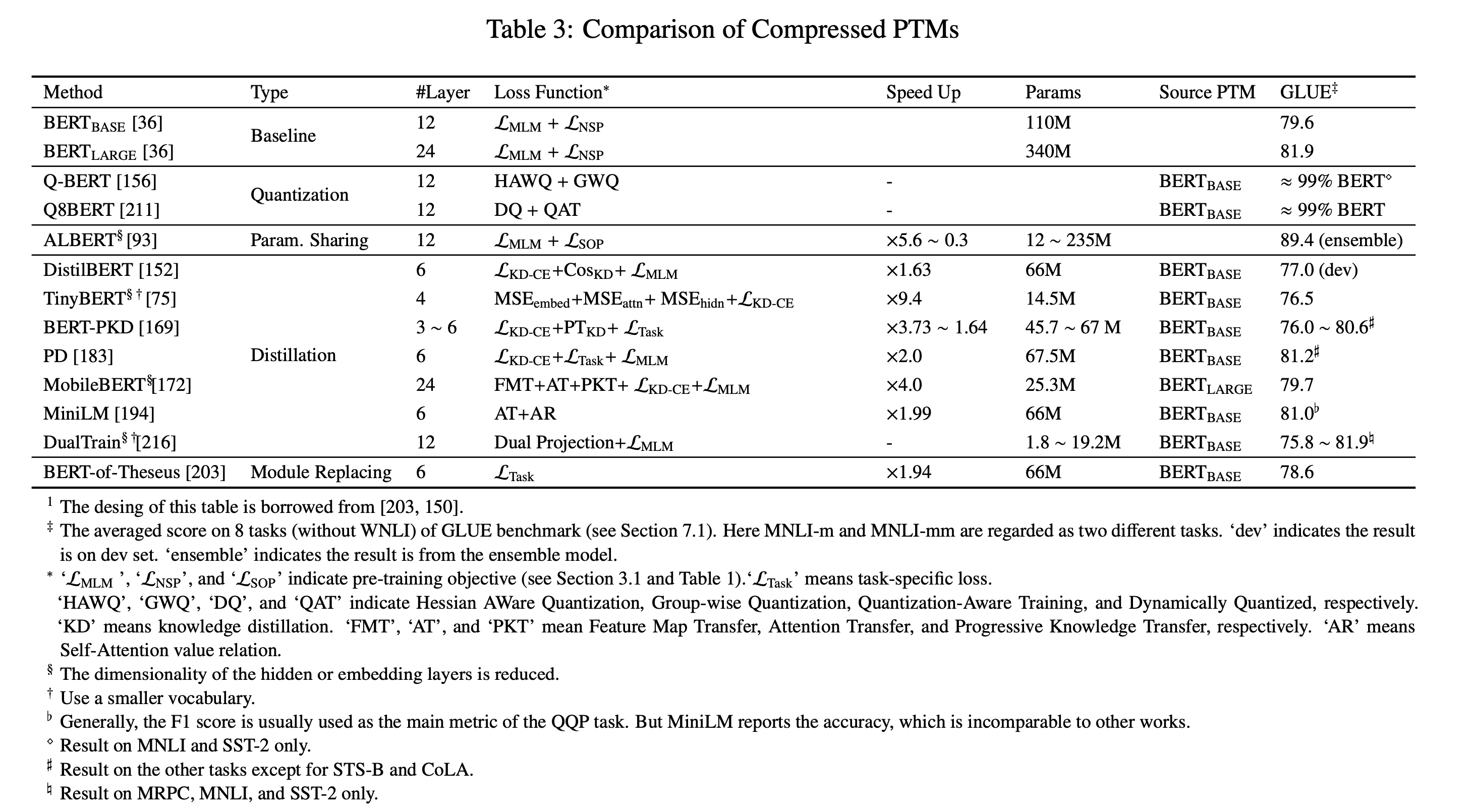
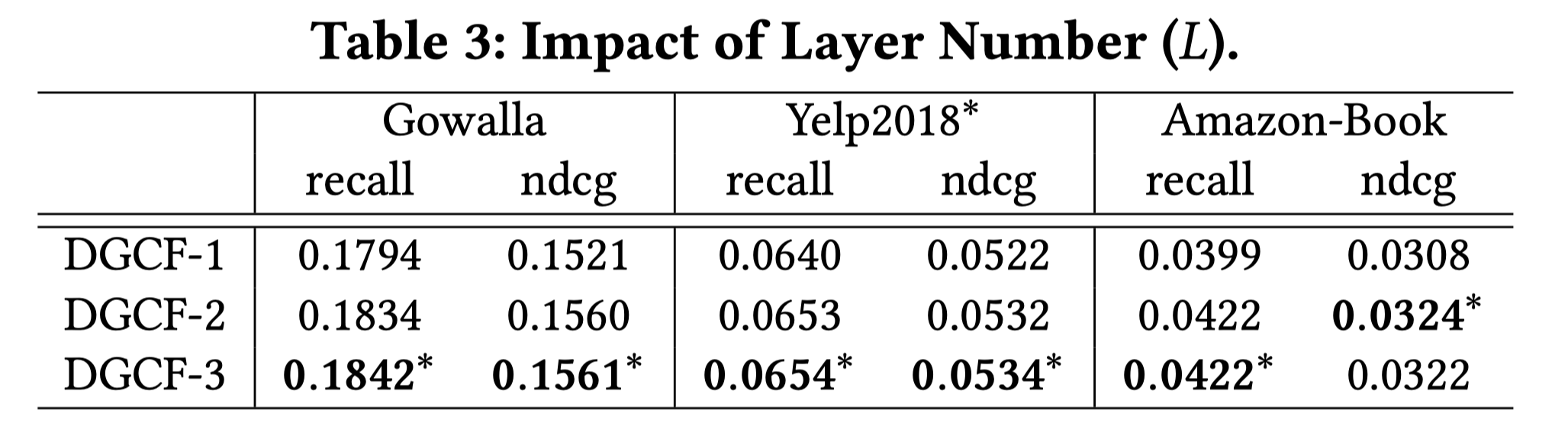
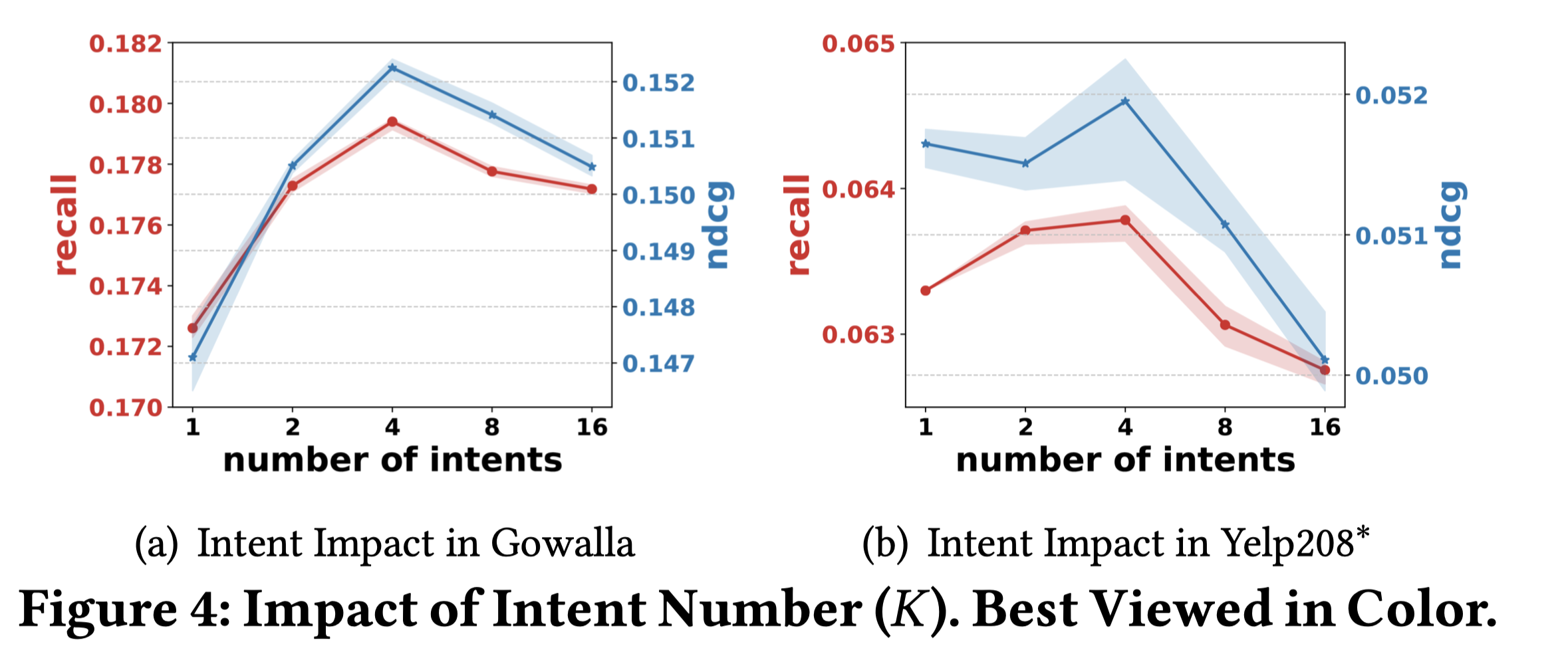
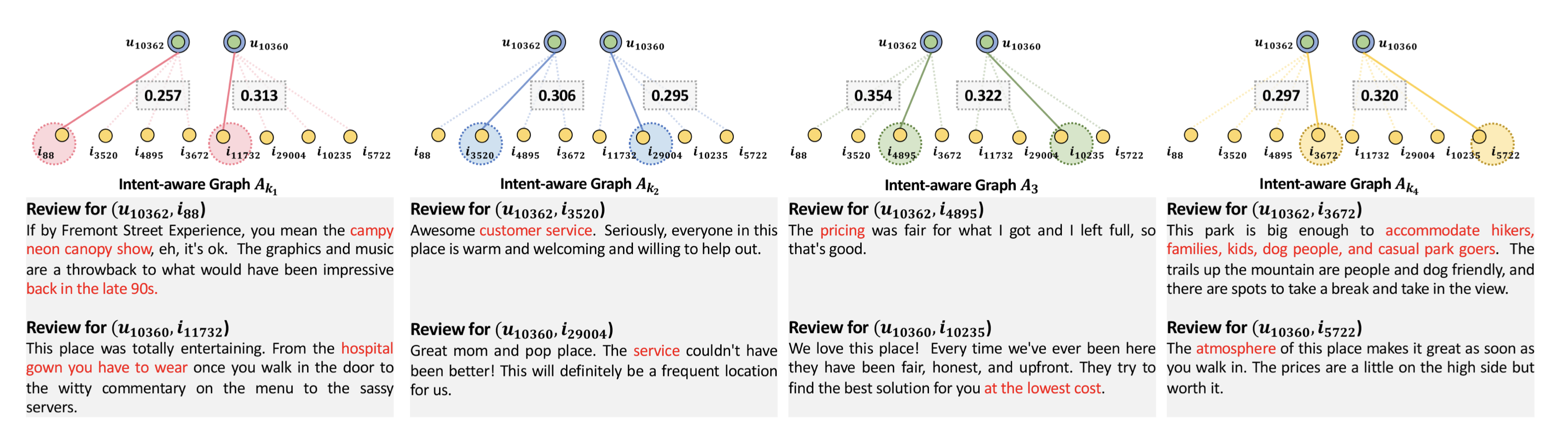
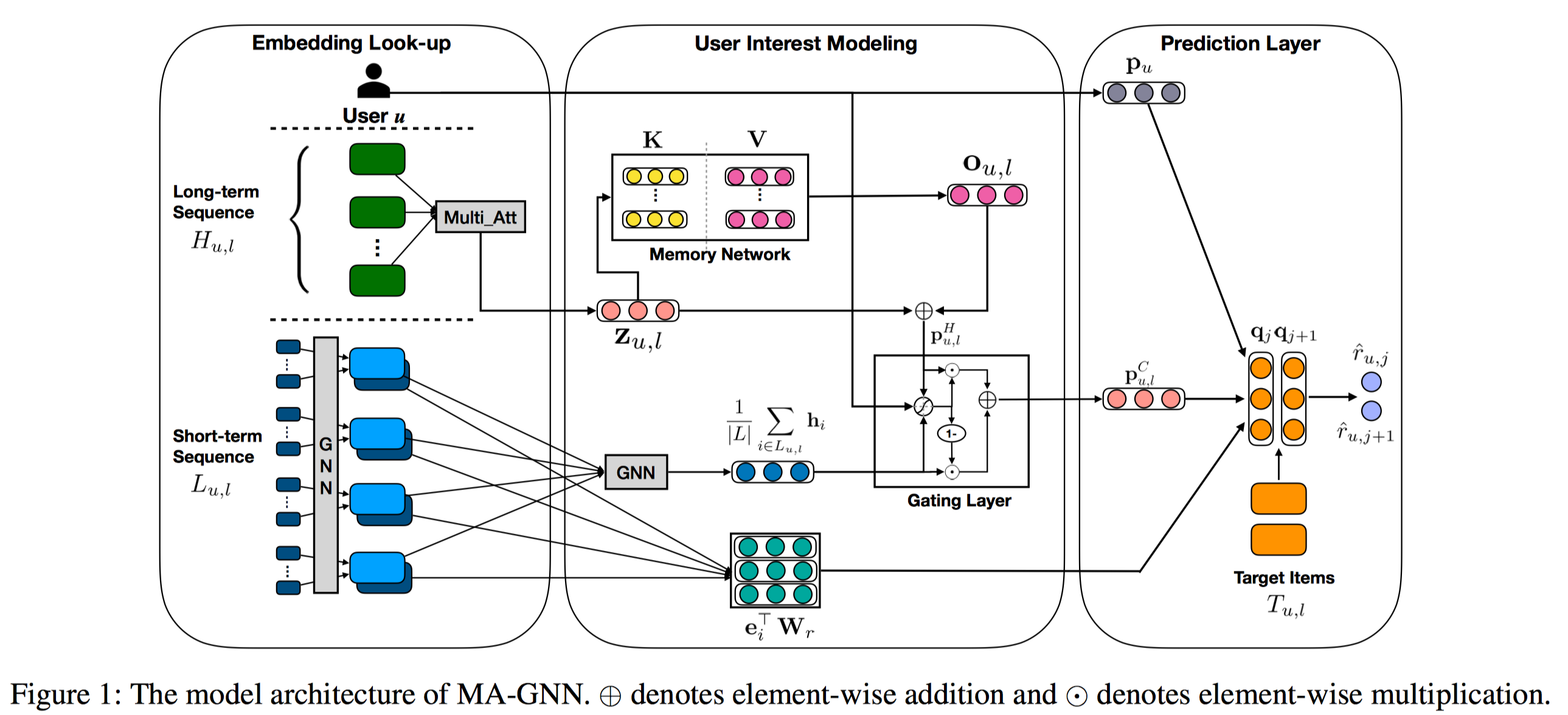
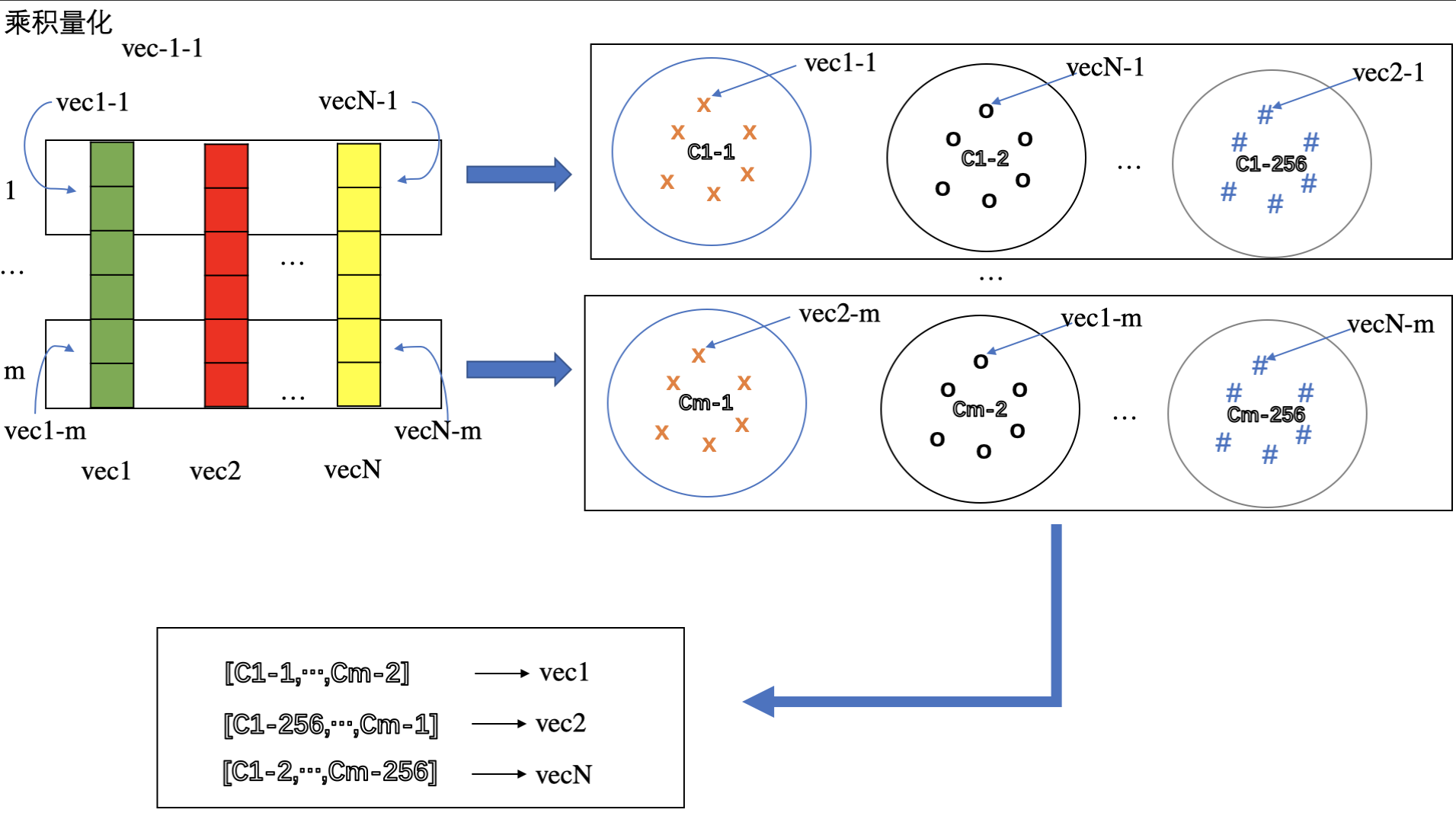
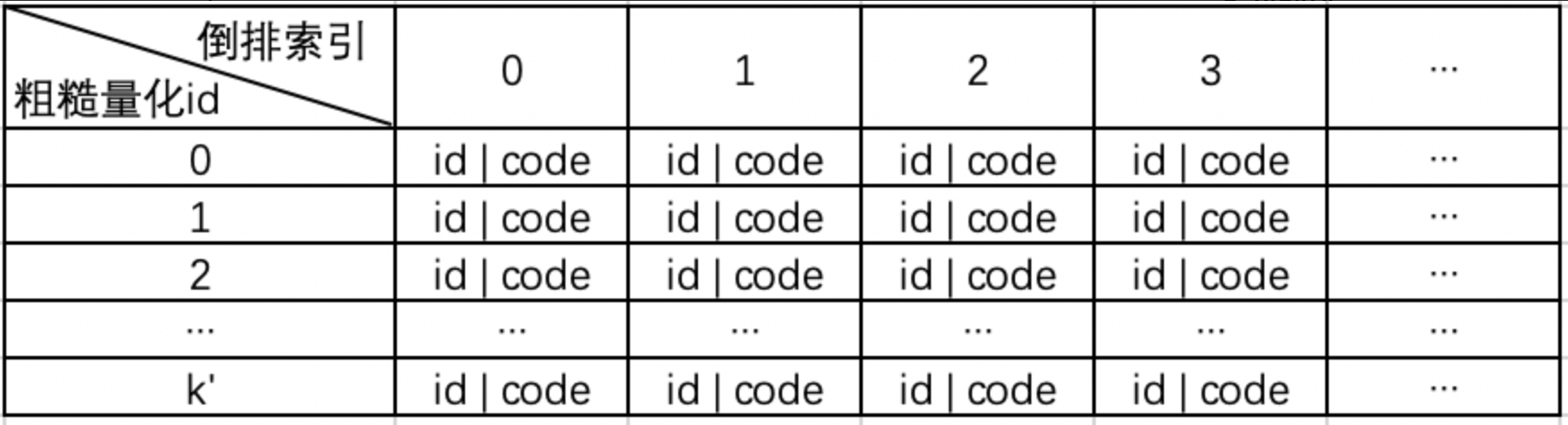
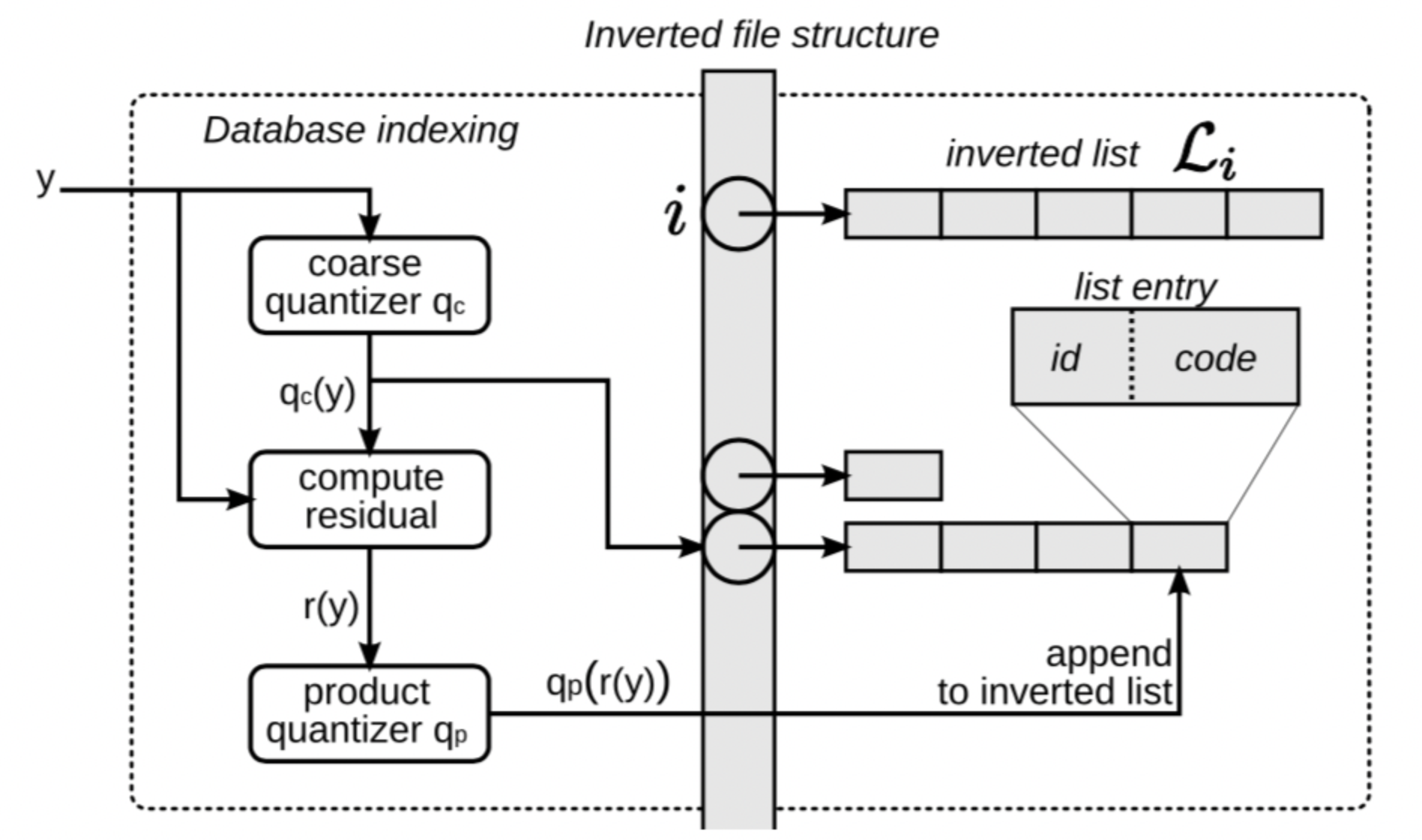
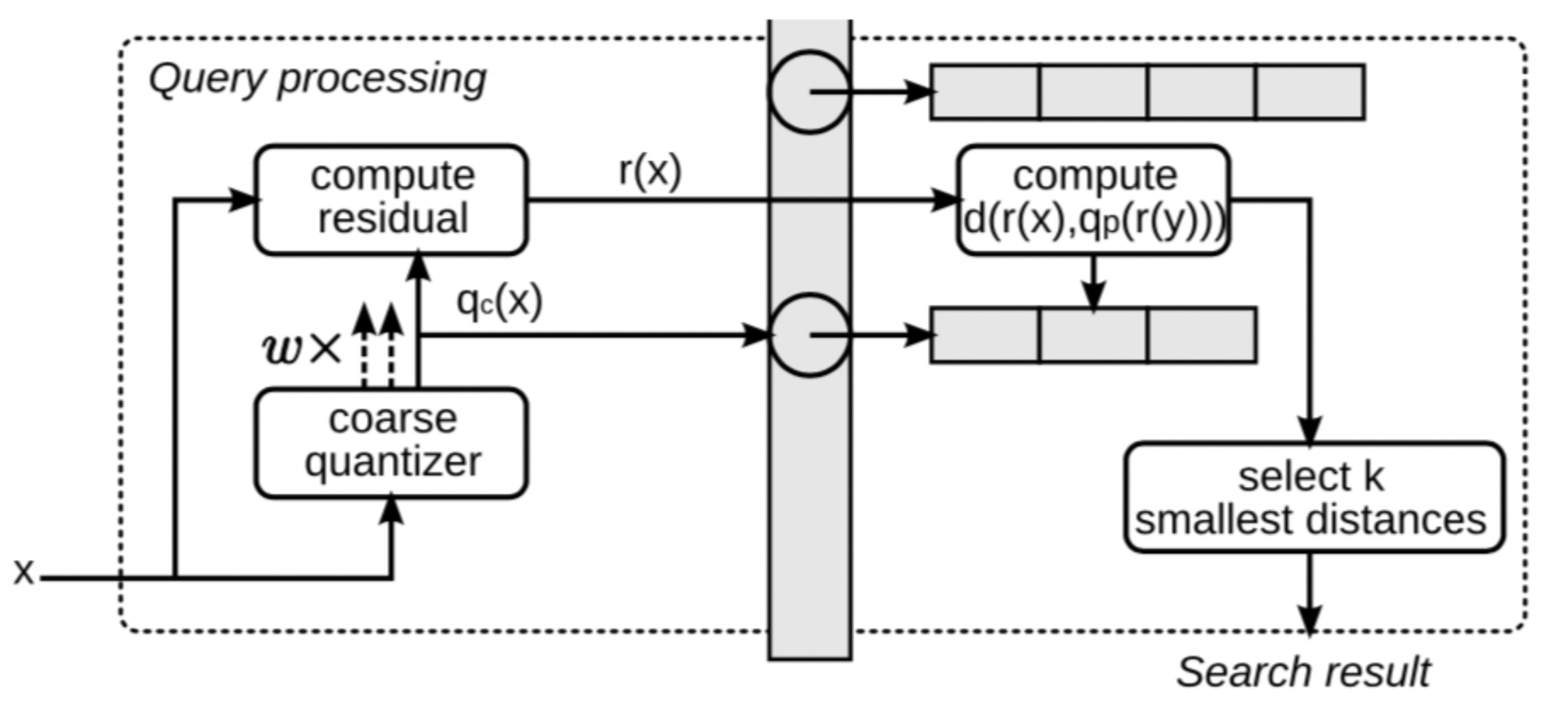
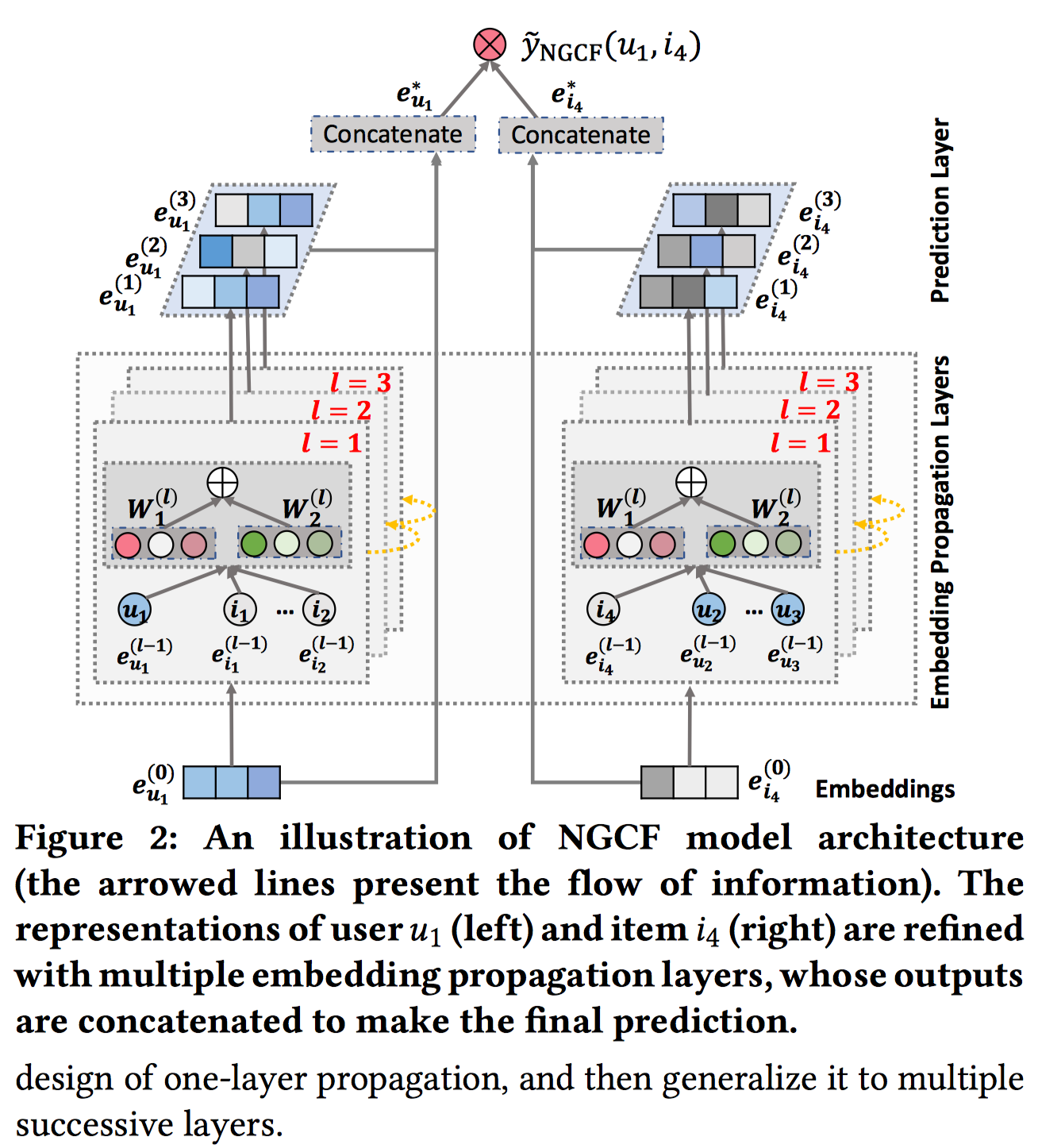
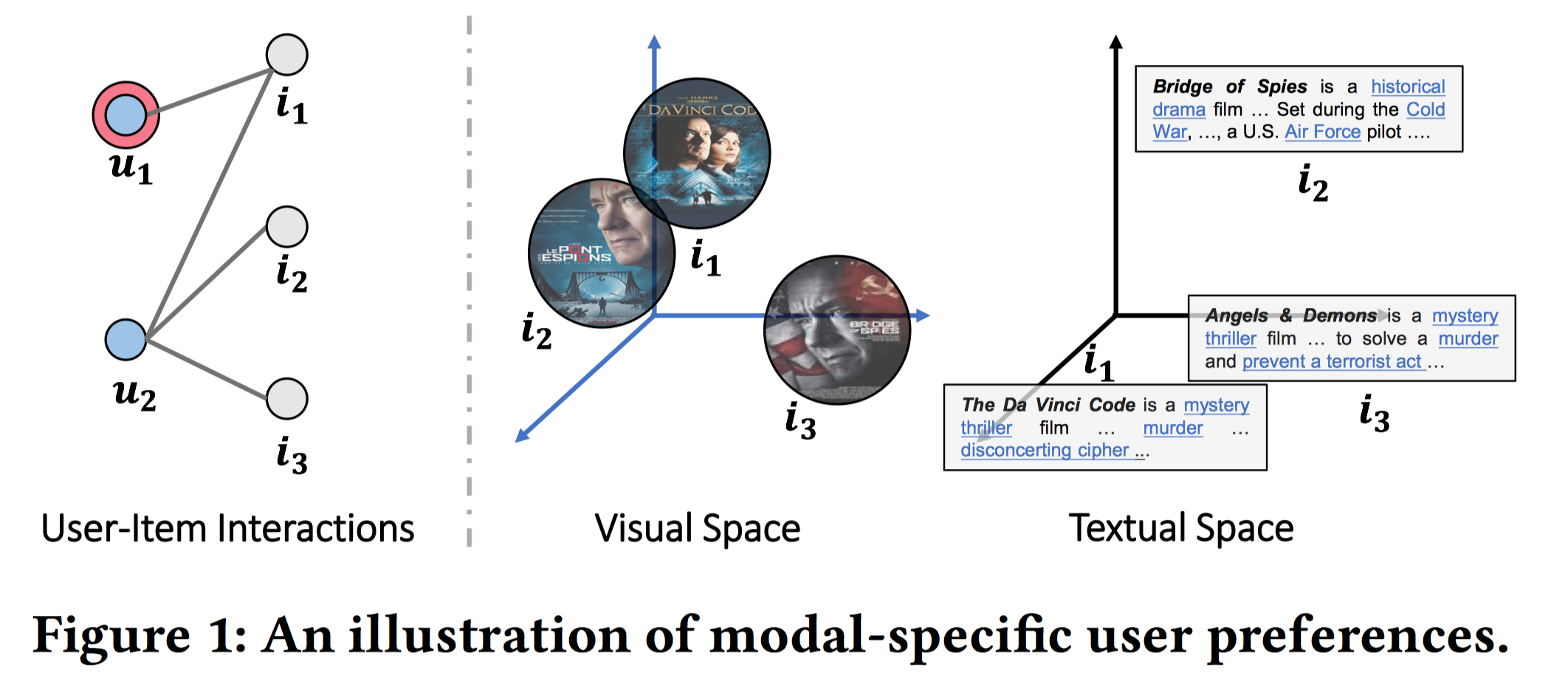
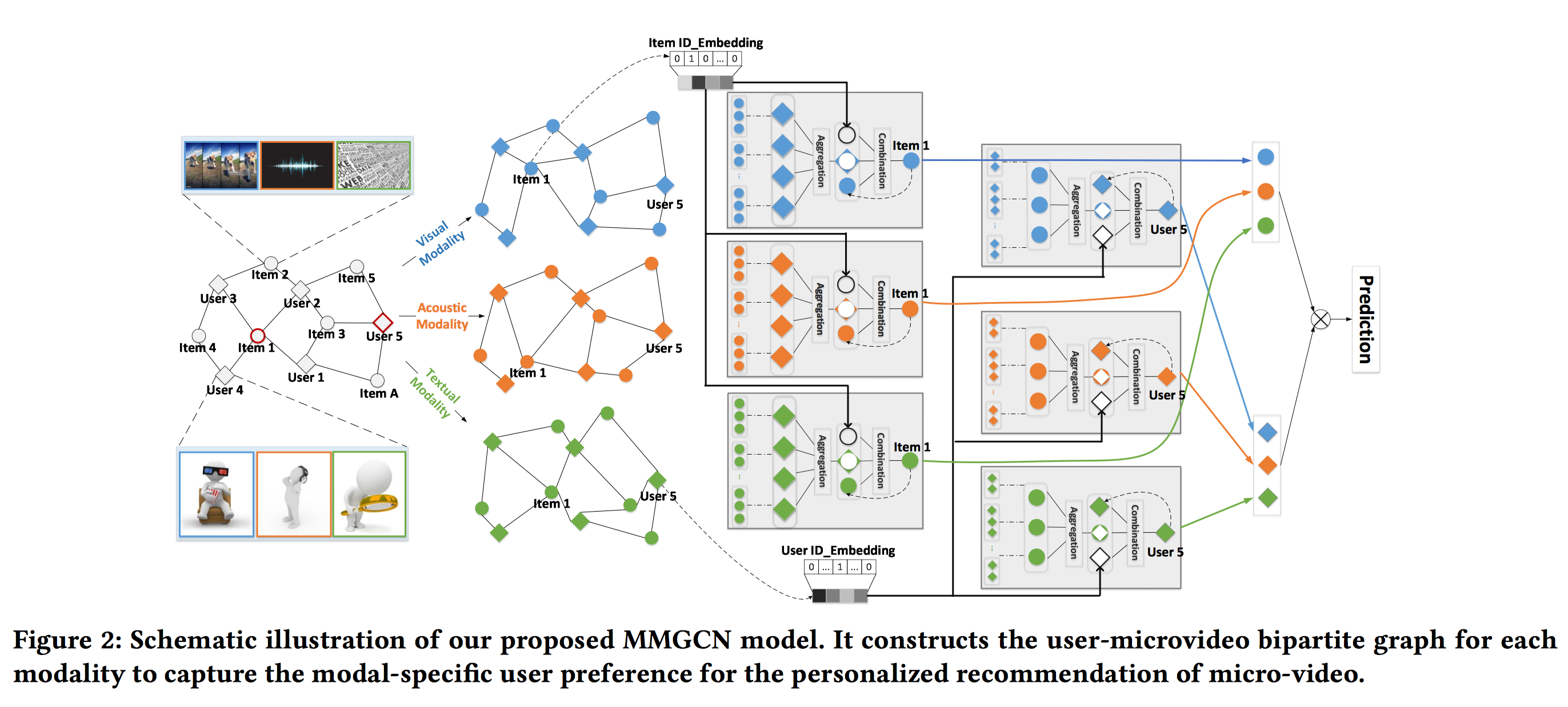
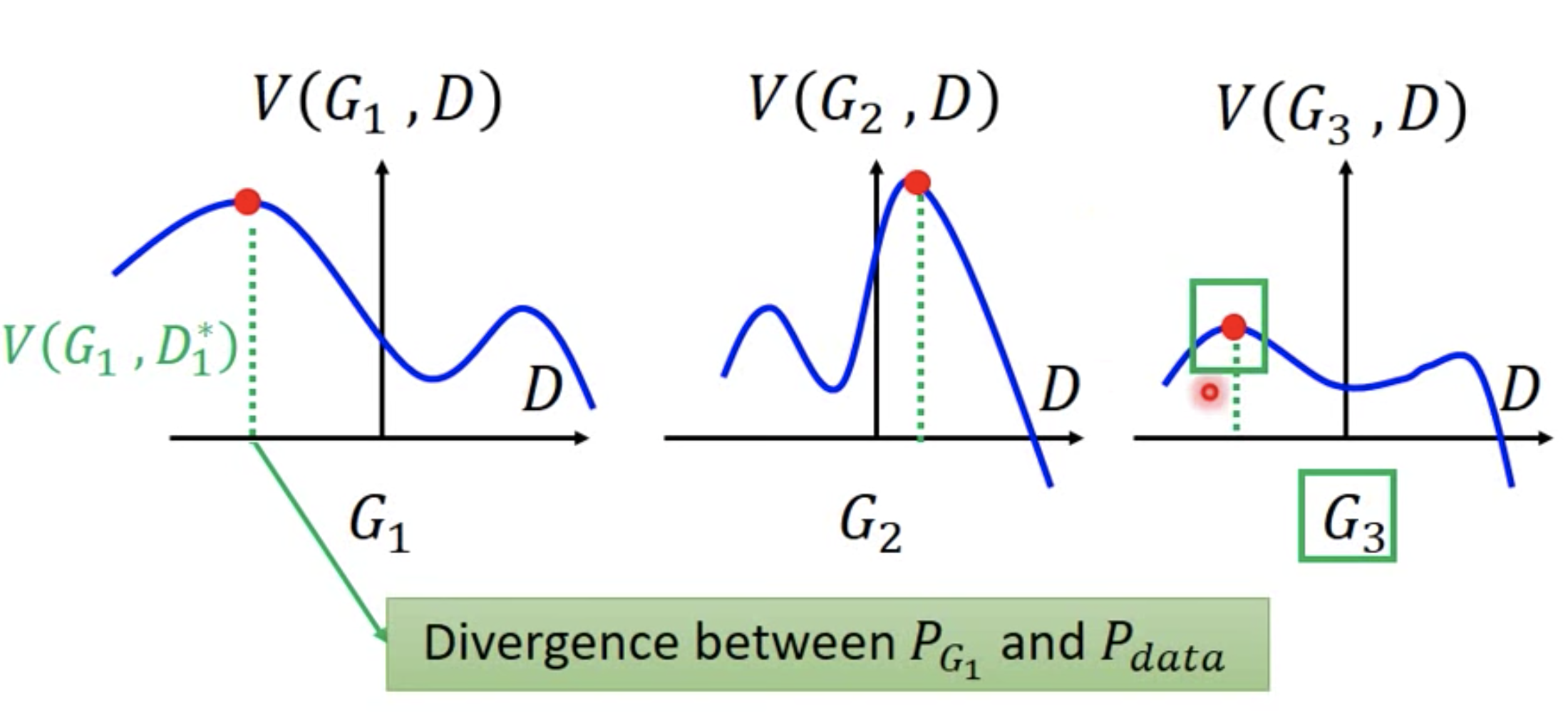
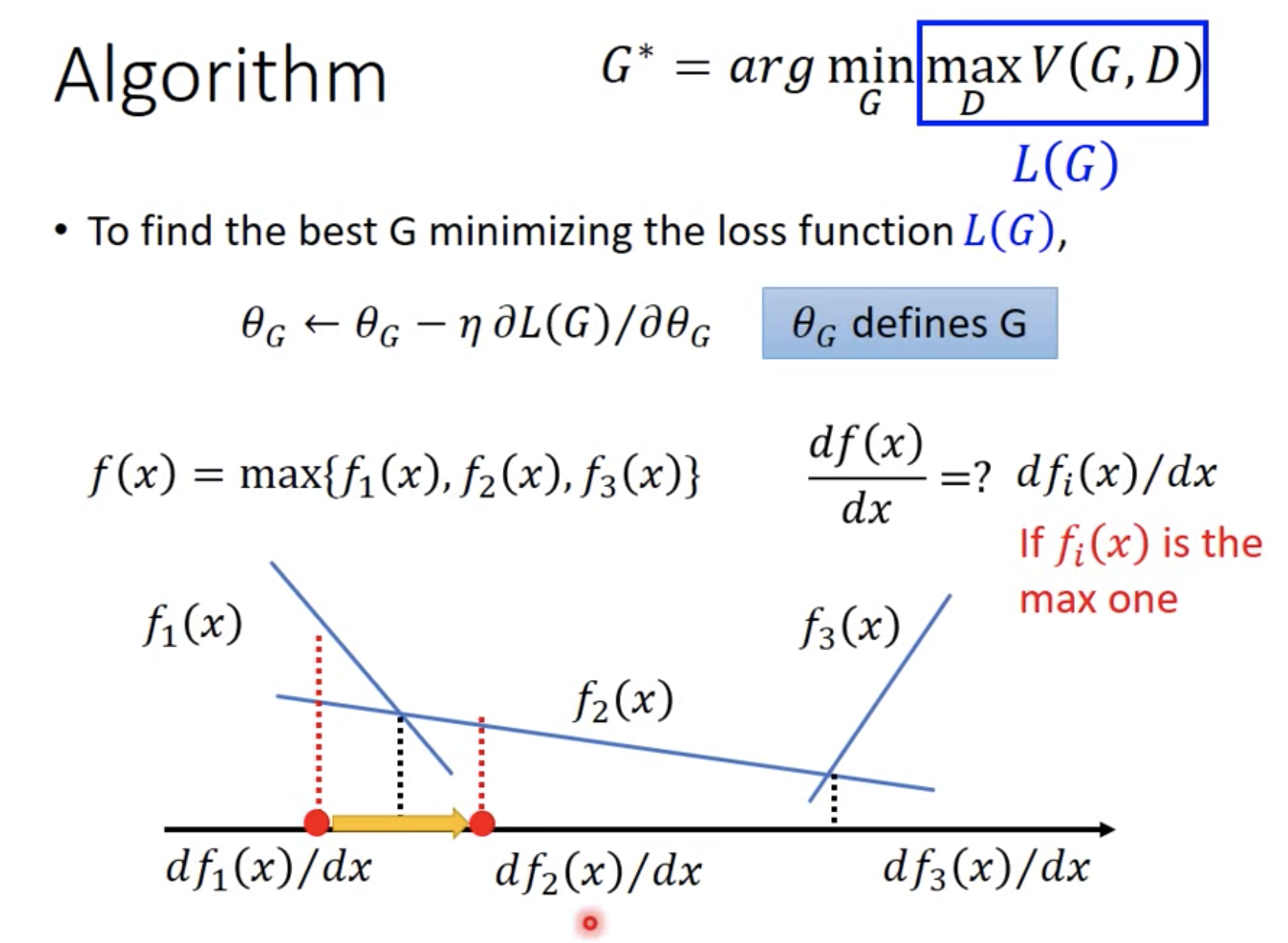
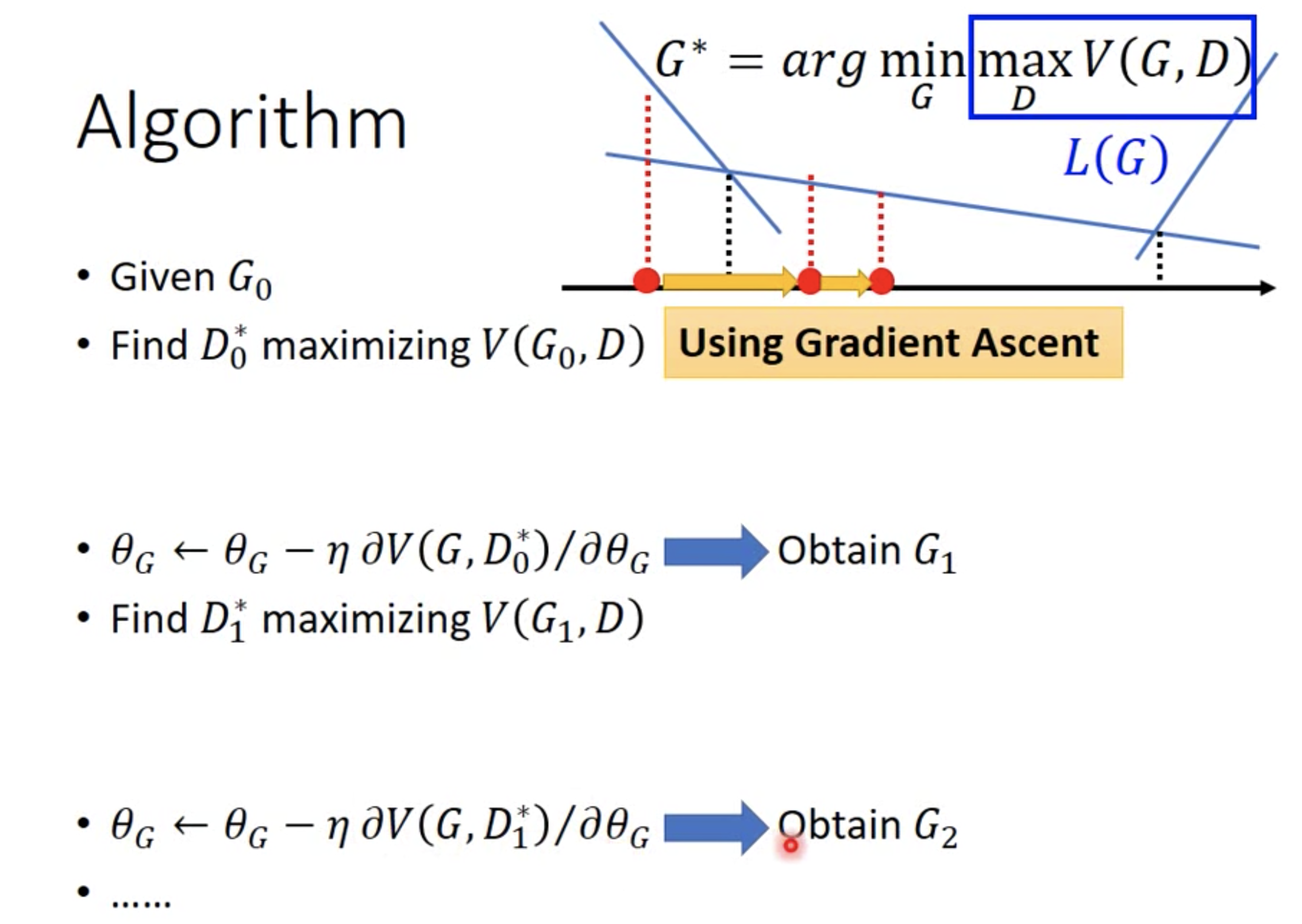
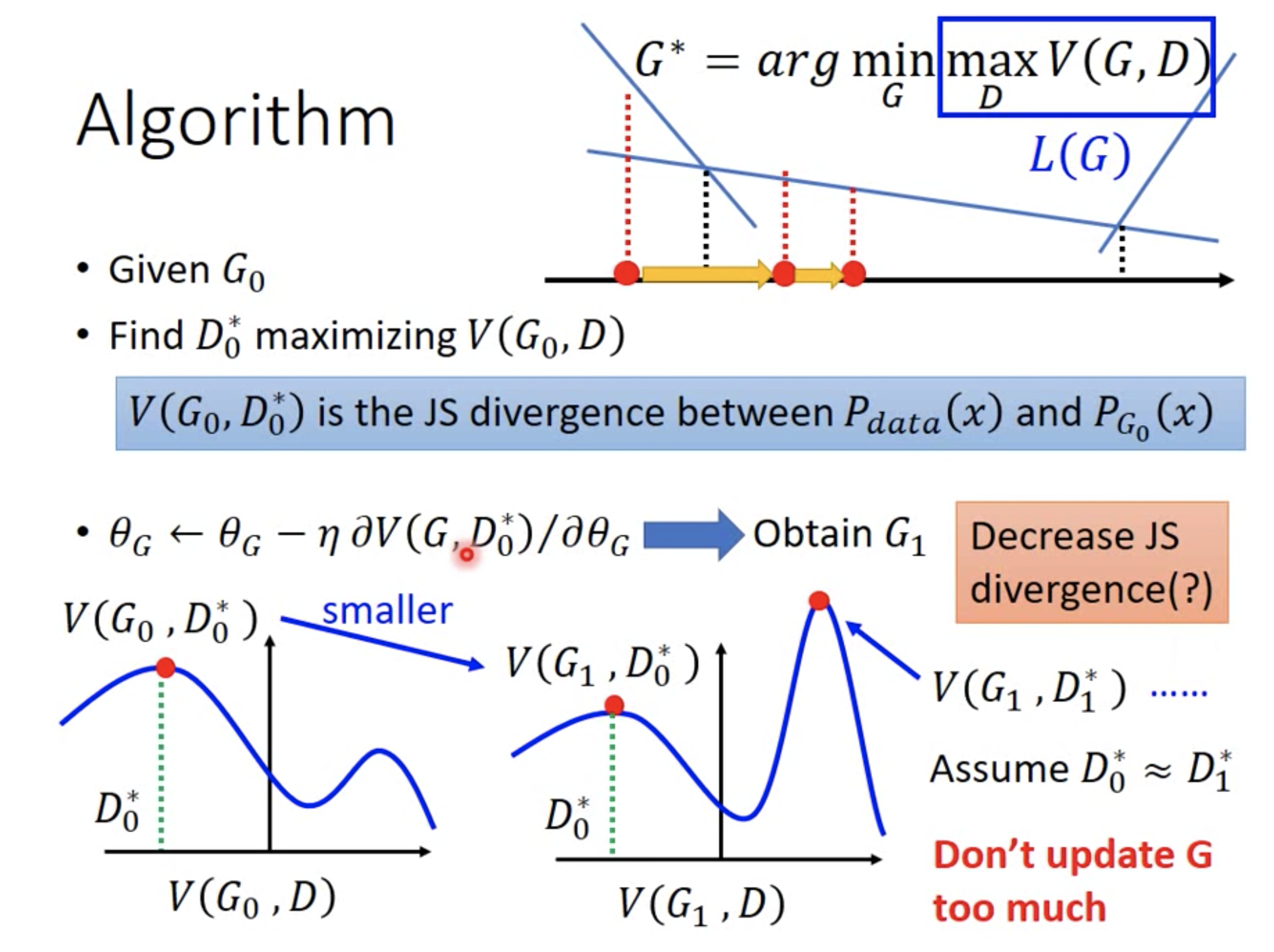
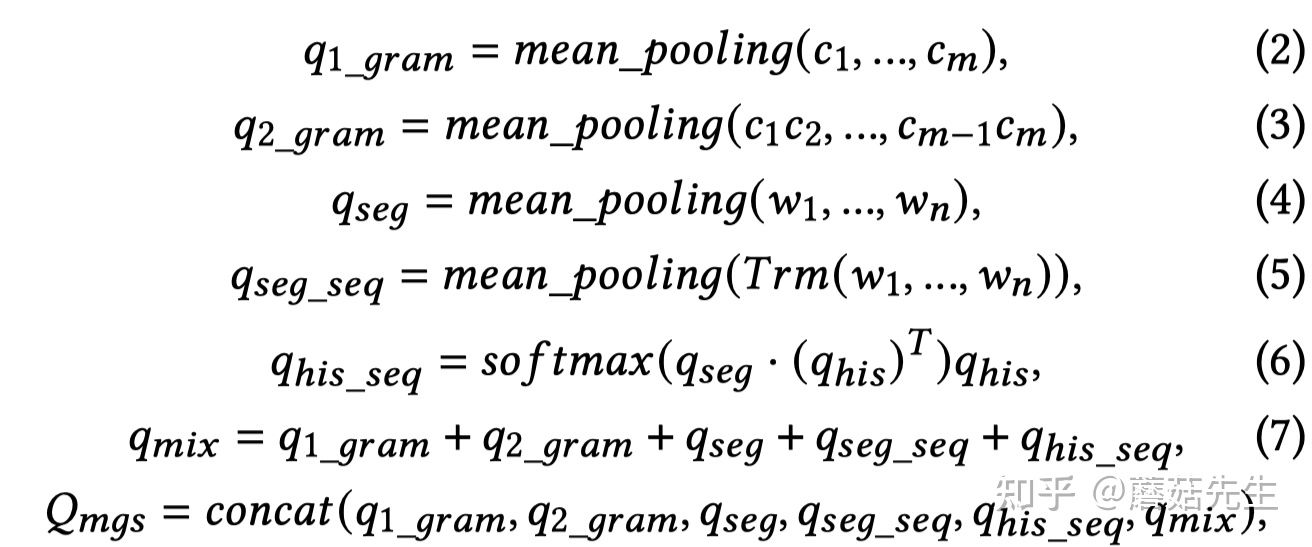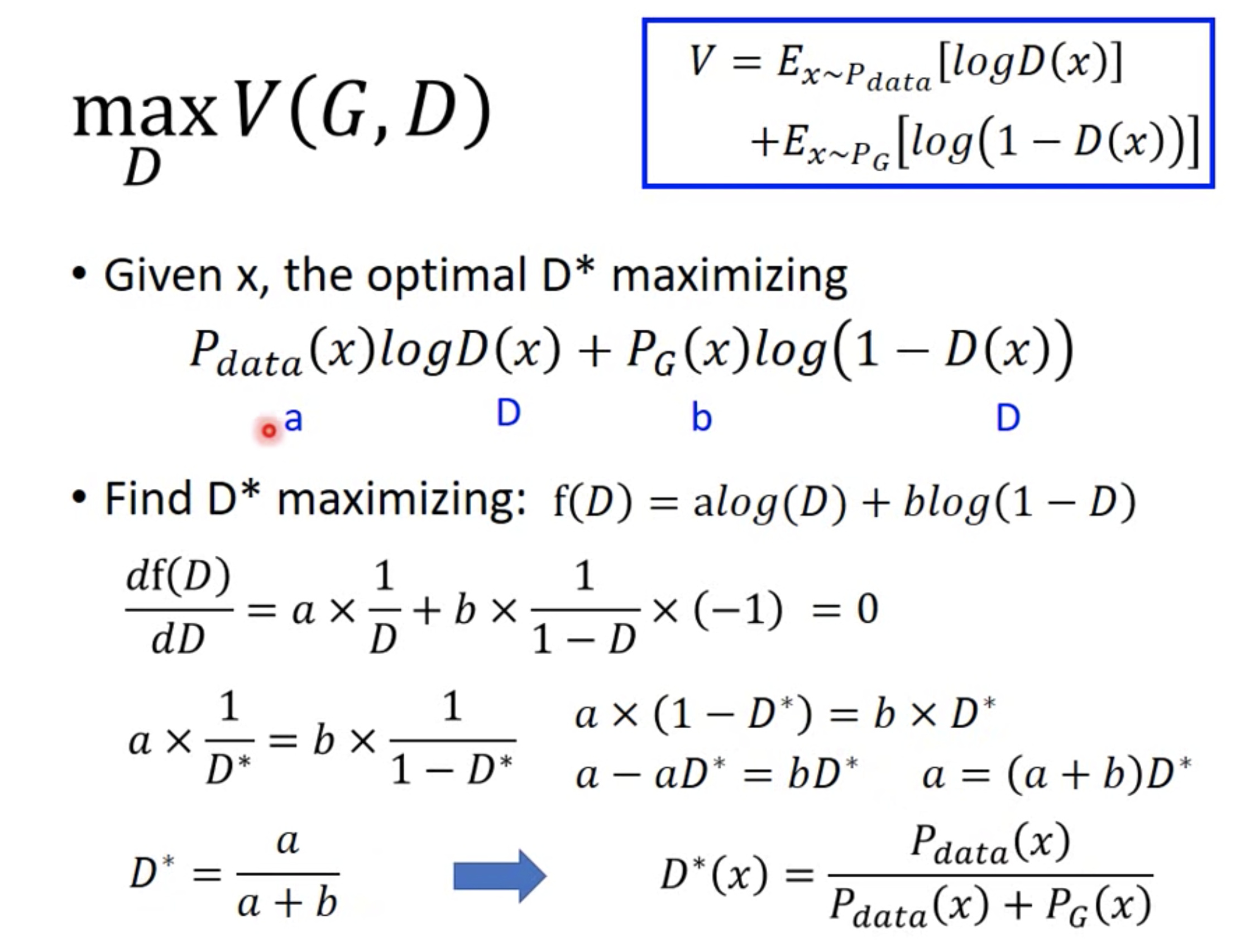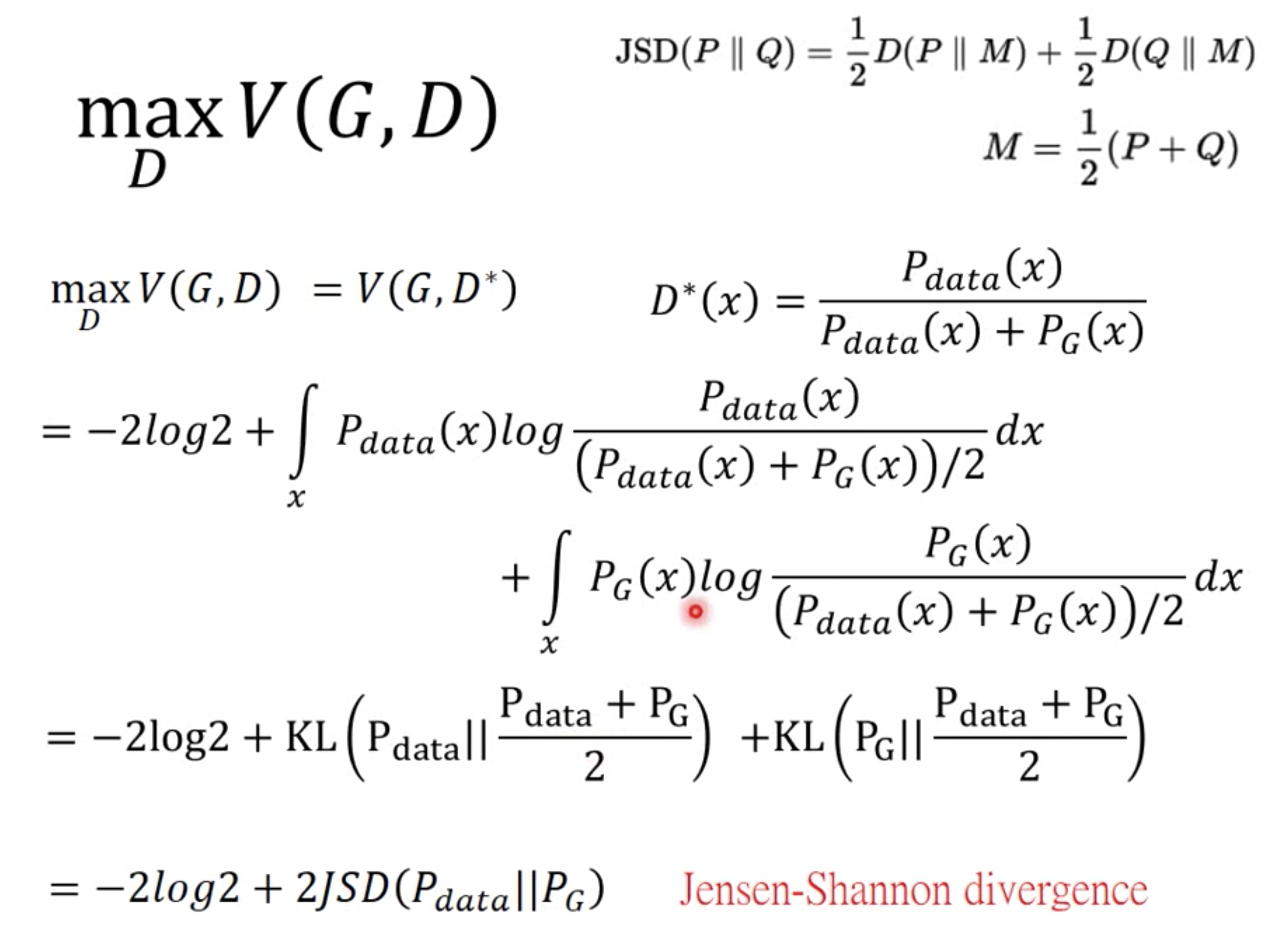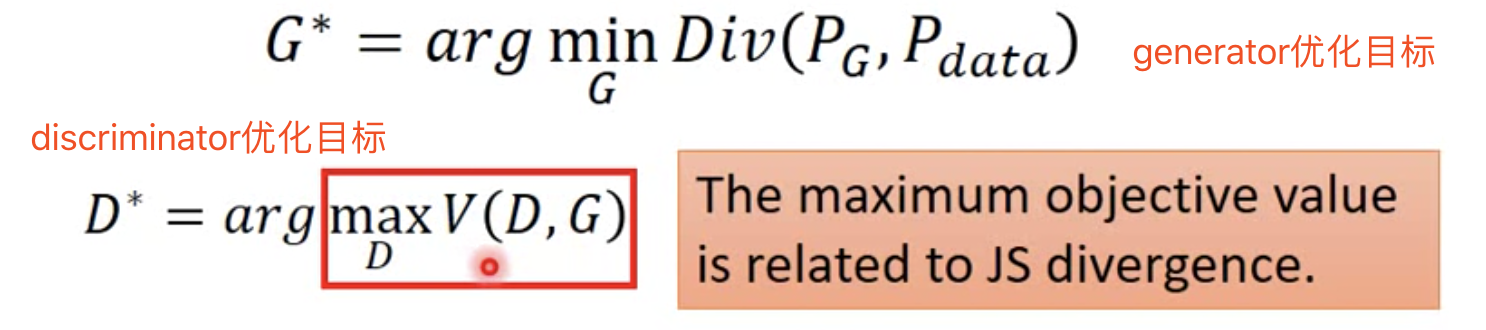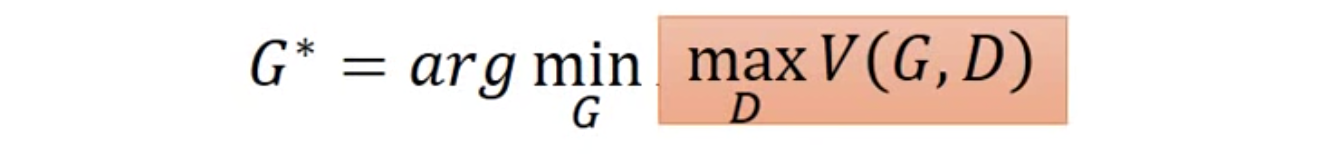排序是对一组物品列表按照某种方式进行排序,来最大化整个列表的效用的过程,广泛应用于搜索引擎、推荐系统、机器翻译、对话系统甚至计算生物学。一些监督机器学习技术经常被广泛应用在这些问题中,这些技术称作排序学习技术。本文会对排序学习进行调研。
欢迎关注我的公众号”蘑菇先生学习记“,更快更及时地获取推荐系统前沿进展!

Introduction
排序学习(Learning to Rank, LTR)最早兴起于信息检索领域。经典的信息检索模型包括布尔模型、向量空间模型 、 概率模型、语言模型以及链接分析等。这些在不同时期提出的模型都是无监督排序方法,其共同特点是利用一些简单的特征进行排序,例如词频、逆文档频率等。这些传统排序方法的优点在于容易进行经验参数的调整,得到最优的参数,用以对检索文档按照一定标准(往往是查询与文档之间的相关性)进行排序。
随着搜索引擎需要处理的数据量呈指数增长,人为凭经验优化参数的过程变得越来越复杂。另外,影响文档排序的信息多种多样(文本相关性中的VSM、LM、BM25分值;临近度;PageRank值;是否是垃圾网页;URL深度;域名重要性等),然后这些经典的模型往往偏重某一方面的因素而忽略了其他可以用于排序的重要因素,例如概率模型和语言模型都没有考虑网页链接、网页 pagerank 值等互联网结构对排序的影响。在这种情况下,排序学习应运而生。排序学习的定义为:基于机器学习中用于解决分类与回归问题的思想,提出利用机器学习方法解决排序的问题。排序学习的目标在于自动地从训练数据中学习得到一个排序函数,使其在文本检索中能够针对文本的相关性、重要性等衡量标准对文本进行排序。机器学习的优势是:整合大量复杂特征并自动进行参数调整,自动学习最优参数,降低了单一考虑排序因素的风险;同时,能够通过众多有效手段规避过拟合问题。
而在推荐系统领域,传统的推荐算法主要可以分为3 大类:基于内容的推荐算法、协同过滤推荐算法以及混合推荐算法。这些传统推荐算法重点考虑用户和物品之间的二元关系,大都可以转化为评分预测问题,根据用户对物品的评分进行排序后产生推荐列表。但仅仅依据用户对物品的评分产生推荐结果并不能准确地体现用户的偏好。随着数据的增长,关于用户、物品、上下文、搜索等信息的获取成为了可能,而这些因素对用户的偏好有很大的影响。单一的推荐模型仅能从某一个方面的因素考虑用户的偏好,此时就需要排序模型来综合考虑各种影响用户偏好的因素,推荐系统领域的排序学习也因此应运而生。
基于排序学习的推荐算法通用模型如下所示,
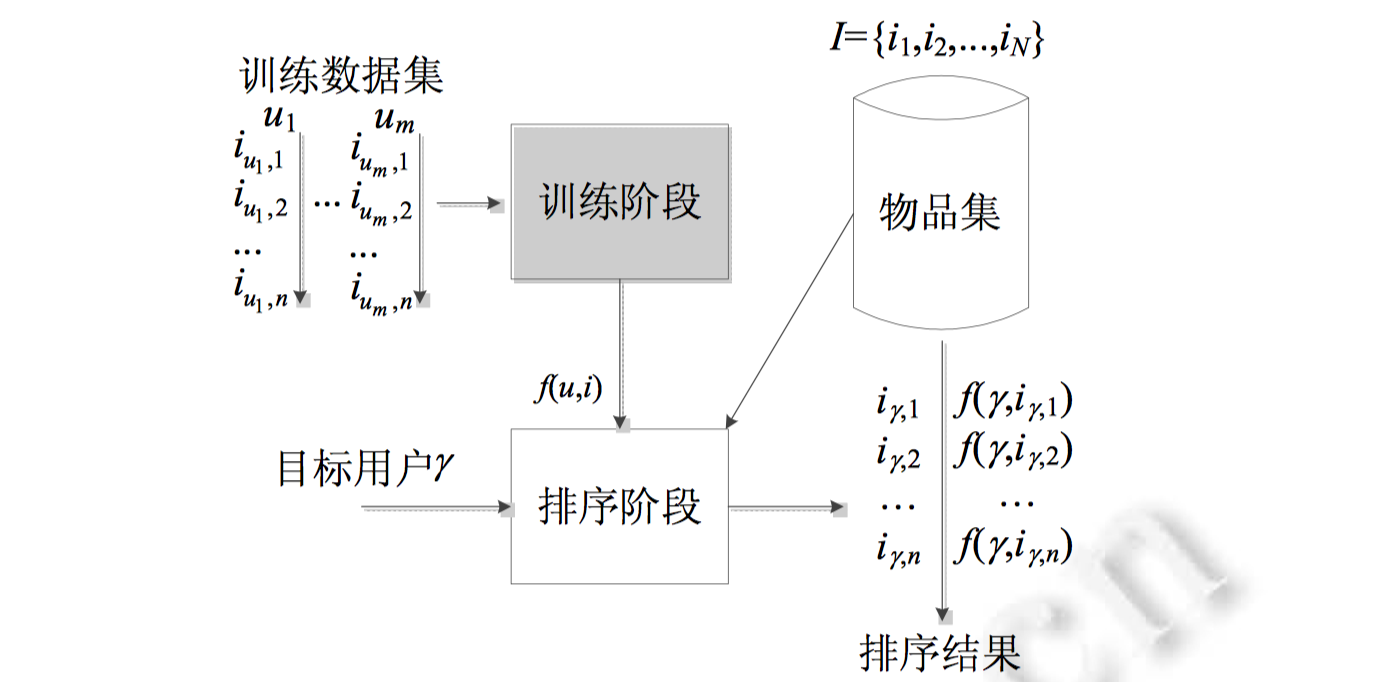
排序学习广义上可以算作是一种监督性学习,将推荐系统中已经处理好的交互数据或人为标注好的数据作为训练集进行学习。这里可以采用点级、对级、列表级等不同的排序技术,根据训练数据构建输入样本,并训练得到一个排序模型$ f(u,i)$,其中,$u\in U$ 表示某一特定用户,$U$表示所有用户的集合, 而$i \in I$ 表示某一具体物品, $I$表示所有物品的集合。在测试阶段,系统根据训练得到的排序模型$f(u,i)$ 对目标用户$\gamma$ 产生一个物品排序列表$\{ i_{\gamma,1} , i_{\gamma,2} ,…,i_{\gamma,n} \}$, 并将该列表推荐给用户$\gamma$, 其中 $i_{\gamma,1}$ 表示在目标用户 $\gamma$ 的物品排序列表中排在第1位的物品,以此类推。
不难发现:排序学习融合进推荐算法之中,其目的在于对具有潜在购买力的目标用户,根据训练得到的排序模型对物品列表进行排序,最终得到一个排序列表,作为该目标用户的推荐列表进行推荐。不得不说IR领域的LTR方法和推荐领域的LTR方法非常像。只不过,推荐领域的LTR更强调利用原始交互数据(interaction data)进行排序学习,原始交互数据更像是一种无监督数据,因此从狭义上来说,推荐系统很大程度上应当归到无监督学习,而IR领域更强调人为专家标注的监督数据进行排序学习,因此更应该归到监督学习。另外,IR领域的OLTR(Online Learning to Rank, SIGIR2016: Slides: Online Learning to Rank for Information Retrieval )利用的是交互数据,更接近于推荐系统领域的LTR。
特别要强调的是,工业界的推荐系统通常会分为两个阶段,召回阶段和排序阶段。召回阶段根据用户的兴趣和历史行为,从千万级的物品库中挑选出一个小的候选集(e.g., 几百到几千个物品)。这些候选都是用户很大概率会感兴趣的内容,排序阶段在此基础上进行更精准的计算,能够给每一个物品进行精确打分,进而从成千上万的候选中选出用户最感兴趣的少量物品(e.g., 十几个)。一般召回阶段包含了多个通道的召回模型,比如协同过滤,主题模型,基于内容的推荐等通道(不同通道召回时,可以使用近似近邻搜索、最大点积搜索等搜索算法提高召回速度),每种召回模型分别考虑了某个或某些影响用户偏好的因素,因此不同召回模型能够从物品库中选出多样性的物品。然而多个通道的召回的物品是不具有可比性的(e.g.,不同模型预测方式不同),且因为数据量太大也难以一一进行更加精确的偏好和质量评估,因此需要在排序阶段对召回结果进行统一的准确的打分排序。
个人认为召回模型和排序模型不是正交的关系,召回模型的输出结果可以进一步根据一定策略排序并进行推荐,大部分召回模型可以看做是pointwise的排序模型;排序模型也可以不需要进行召回,直接根据预测值排序并进行推荐。只不过在实际应用过程中,用户对物品的满意度是有很多维度因子来决定的,用户的偏好是复杂而多样的,为了保证多样化、且精准的推荐,通常需要先使用多种多样的模型,从多种多样的数据源里头挖掘用户偏好,每种模型只考察小部分的因素,多种模型能保证多样性,这是由召回阶段负责的;而不同模型产生的结果通常不具有可比性,无法通过人为制定的规则来融合各种结果并展示给用户,因此通常需要一个排序模型对召回的结果进行排序,且需要进一步综合考虑各种影响用户偏好的因素(特征工程)以及用户真实的反馈行为(数据标注),使用排序模型进行排序学习。至于由哪个模型充当最终排序的角色,这就主要根据最佳实践来选择的。通常,机器学习模型能够充当这样的角色(LR、GBDT、DNN等)。因此下文主要就是调研实践中表现较好的排序模型,另外在结尾部分,本文还讨论了关于排序学习的一些高级话题。
Preliminary
排序学习方法按照输入样例的不同,一般可分为3类:点级(pointwise)、对级(pairwise)、列表级(listwise)。点级方法输入包括用户、物品等特征,根据其对待排序的不同方式划分为回归和分类两种方法,它们分别将排序问题退化为回归与分类问题求解;对级方法考虑物品对之间的偏序关系,将问题转换为有序分类问题,更接近排序问题的实质。列表级方法输入所有相关联的物品集合,更加全面地考虑了不同物品的序列关系,因而成为近年被研究较多的方法。
因此,排序学习主要依赖于用户行为的数据标注,用户、物品、搜索、上下文的特征工程以及排序模型。
Data Labeling
其中,用户行为的数据标注主要从用户搜索、系统展示以及用户实际的反馈操作中收集得到。标注数据包括Pointwise方式、Pairwise方式、Listwise方式。
Pointwise方式中,单个物品对于某个用户而言,要么是正样本、要么是负样本。对于正样本,用户实际的反馈操作包括点击、浏览、收藏、下单、支付等,不同操作反映了该物品对用户需求的不同匹配程度,对应的样本可以看做正样本,且赋予不同的权重。对于负样本,为了模拟用户的真实浏览行为(从上往下),可以采取Skip Above策略,即用户点过的物品之上,采样没有点过的物品作为负样本。
Pairwise方式中,主要构造物品pair对,对单个用户而言,没有绝对的偏好,只有对某个物品的相对偏好(e.g., 比起B,用户更喜欢A)。同样存在多种策略,可以收集Pairwise数据标注。例如,
$$
\begin{aligned}
&\text{Click} > \text{Skip Above}; \\
&\text{Last Click} > \text{Skip Above}; \\
&\text{Click} > \text{Earlier Click};\\
&\text{Click} > \text{No-Click Next}。
\end{aligned}
$$
其中,Click >Skip Above代表某个点击的物品比排在该物品之前、但用户略过的物品更好。
Listwise方式中,会考察列表级别的排序。例如,列表的NDCG指标融入到目标函数中,目标函数能够优化列表级别的排序指标。
Feature Engineer
特征工程涵盖面较广,包括用户特征、物品特征、搜索特征、上下文特征(时间、地点、天气等)等,以及不同特征之间的交叉关联,还包括从其他高阶特征,如使用主题模型提取的用户兴趣分布,使用神经网络提取的高阶特征等等,这些特征都可以作为排序模型的输入。
Ranker
Pointwise模型的关键要素如下:
- 输入空间:每个物品的的特征向量(feature vector)。
- 输出空间:每个物品的相关性程度(relevance degree)。
- 假设空间:得分函数(scoring functions)。
- 损失函数:回归损失(regression loss)、分类损失(classification loss)、有序回归损失(orginal regression loss,即类别之间有某种顺序关系的模型,如Perfect>Excellent> Good>Fair>Bad)
优势:
劣势:
- 损失函数中未考虑排序列表的顺序
- Pointwise LTR形式化和IR排序问题不够一致
- 扭曲了数据的真实分布(数据之间非独立分布)
- 严重的位置偏差(Position Bias),比如用户会倾向于点击靠前的物品,但不一定是用户真正感兴趣的;展示偏差(Presentation Bias),比如未展示物品用户不会点击,但是用户可能感兴趣。
Pairwise模型的关键要素如下:
- 输入空间:物品对(Item pairs) $(x_i,x_j)$
- 输出空间:偏好(prefenence)$r_{ij} \in \{-1, 1\}$
- 假设空间:偏好函数(preference function)
- 损失函数:pairwise分类损失(Pairwise Classification Loss)
优势:
劣势:
- 排序列表中所有物品一视同仁,即Top Ranking未匹配的重要性和Bottom Ranking未匹配的重要性一样。这和IR排序指标中强调Top Ranking的情况不太一致(如NDCG)
- 高复杂度($O(N^2)$, $N$是物品数量)
- 假设物品相互独立。
Listwise模型的关键要素如下:
- 输入空间:物品集合,$x=\{x_j\}_{j=1}^m$
- 输出空间:所有物品的得分或所有物品的完整排序。
- 假设空间:排序函数(permutation function)或得分函数(scoring function)。
- 损失函数:IR评估指标或其平滑近似。
优势:
- 直接优化IR排序指标
- 可以学习物品间listwise层面的属性(如物品之间的依赖性、多样性等)
排序模型利用样本的标注、样本的特征工程,并借助排序模型进行训练和学习。排序模型对候选物品按照得分进行排序,并最终按顺序展示有限个物品给用户。得分一般使用$P(y|\boldsymbol{x})$来衡量,即在给定特征$\boldsymbol{x}$条件下,用户行为是$y$的概率($y$一般取0或者1)。$\boldsymbol{x}$是上述所述特征工程得到的各种各样特征;$y$是上述所述数据标注中,收集到的各种各样的用户操作。大部分用于CTR点击率预估($y$代表点击行为)的模型,都可以用在推荐系统的排序阶段。
另外,实际应用时,不管哪种模型,都要支持离线学习和在线学习。离线学习根据标注的历史数据进行离线训练。在线学习根据用户实时的搜索,实时的反馈,实时的特征变化等,对模型进行增量更新和迭代,并实时的进行在线排序。同时,在线学习还要兼顾探索-利用问题(exploration-exploitation dilemma),如果只展示用户一定满意的物品,那其余潜在满意或不满意的物品就很难获取反馈。在线学习的算法设计核心要素如下图所示(SIGIR2016: Slides: Online Learning to Rank for Information Retrieval):
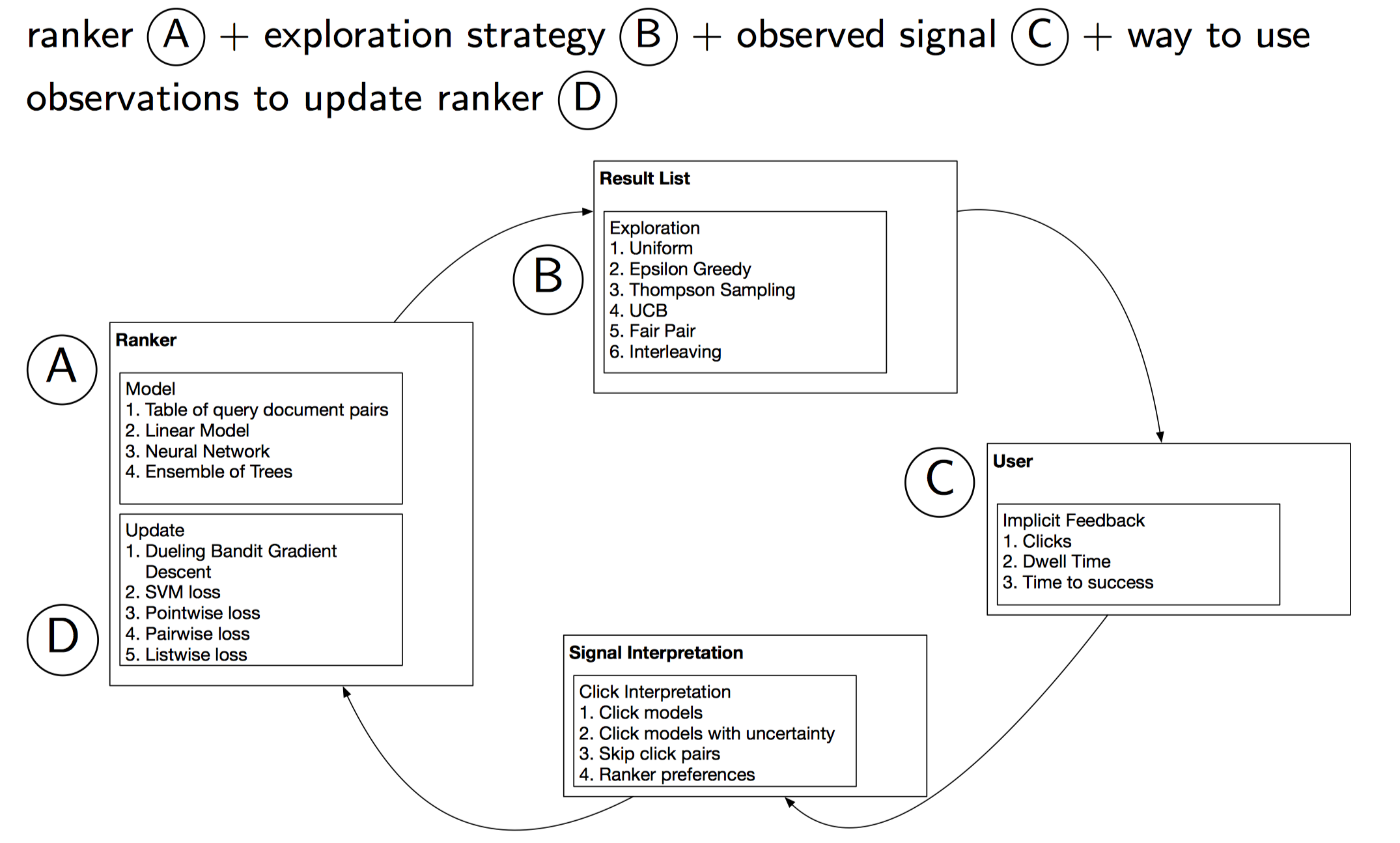
可以看出,包含了各种各样的排序模型ranker(解决exploitation)、各种各样的探索策略(解决exploration)、收集用户实时的反馈(如点击、停留时间等)、反馈数据处理(将反馈数据处理并转换成输入空间格式)、不同ranker不同损失函数的在线更新。
下文主要对应用较广的一些排序模型ranker进行调研。
Pointwise Ranker
首先介绍Pointwise排序模型,这种模型直接对标注好的pointwise数据,学习$P(y|\boldsymbol{x})$或直接回归预测$y$。
LR
LR(LogisticRegression)逻辑回归模型,用于建模Pointwise方式的数据。解释性强,方便debug,并且通过特征权重可以解释推荐的内容,找到模型的不足之处。实际优化过程中,会给样本添加不同权重,例如根据反馈的类型点击、浏览、收藏、下单、支付等,依次提高权重,优化如下带权重的损失:
$$
J(\theta)=-\frac{1}{m}\sum_{i=1}^m w_i \cdot \Big( y_i log(\sigma_\theta(\boldsymbol{x}_i))+(1-y_i)log(1-\sigma_\theta(\boldsymbol{x}_i))\Big)
$$
其中,$w_i$是样本的权重,$y_i$是样本的标签。$\sigma_{\theta}(\boldsymbol{x}_i)=\frac{1}{1+e^{-(\boldsymbol{\theta}\cdot \boldsymbol{x}+ \boldsymbol{b})}}$。
另外,LR是个线性分类模型,要求输入是线性独立特征。我们使用的稠密的特征(维度在几十到几百之间)往往都是非线性的,并且具有依赖性,因此需要对特征进行转换。特征转换需要对特征的分布,特征与label的关系进行分析,然后采用合适的转换方法。通常使用以下几种:Polynomial Transformation(多项式变换),Logarithmic or Exponential Transformation(对数变换或指数变换,例如特征符合幂率分布),Interaction Transformation(组合特征变换)和Cumulative Distribution Function(累计分布函数)等。这些特征变换相当于人工将特征转换为线性特征,以提高特征的表达能力。
虽然LR模型简单,解释性强,不过在特征逐渐增多的情况下,劣势显而易见的;
- 特征都需要人工进行转换为线性特征,十分消耗人力,并且质量不能保证。
- 特征两两作Interaction 的情况下,模型预测复杂度是。在100维稠密特征的情况下,就会有组合出10000维的特征,复杂度高,增加特征困难。
- 三个以上的特征进行Interaction 几乎是不可行的。
另外值得注意的是,目前工业界普遍使用FTRL(Follow-the-Regularized-Leader)优化算法来在线更新LR等模型。
FM
分解机FM(Factorization Machine)是由Konstanz大学Steffen Rendle于2010年最早提出的,旨在解决稀疏数据下的特征组合问题。FM设计灵感来源于广义线性模型和矩阵分解。
在线性模型中,我们会单独考察每个特征对Label的影响,一种策略是使用One-hot编码每个特征,然后使用线性模型LR来进行回归,但是one-hot编码后,一者,数据会变得稀疏,二者,很多时候,单个特征和Label相关性不够高。最终导致模型性能不好。为了引入关联特征,可以引入二阶项到线性模型中进行建模:
$$
y(\boldsymbol{x}) = w_0+ \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n w_{ij} x_i x_j
$$
$y(\boldsymbol{x})$是未激活前的回归值,$x_i,x_j$是经过One-hot编码后的特征,取0或1。只有当二者都为1时,$w_{ij}$权重才能得以学习。然而由于稀疏性的存在,满足$x_i,x_j$都非零的样本很少,导致组合特征权重参数缺乏足够多的样本进行学习。
矩阵分解思想此时发挥作用。借鉴协同过滤中,评分矩阵的分解思想,我们也可以对$w_{ij}$组成的二阶项参数矩阵进行分解,所有二次项参数 $w_{ij}$可以组成一个对称阵$W$,那么这个矩阵就可以分解为 $W=V^TV$,$V$的第 $j$ 列便是第 $j$维特征的隐向量。换句话说,每个参数 $w_{ij}=⟨v_i,v_j⟩$,这就是FM模型的核心思想。因此,FM的模型方程为:
$$
y(\boldsymbol{x}) = w_0+ \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n \langle \boldsymbol{v}_i, \boldsymbol{v}_j \rangle x_i x_j
$$
这里的关键是每个特征都能学习到一个隐向量。这样$w_{ij}=⟨v_i,v_j⟩$不仅仅可以通过$x_i,x_j$进行学习,凡是和$x_i$相关联的特征$h$, 都对学习$x_i$的隐向量$v_i$有所帮助,同理和$x_j$关联的其他特征对学习$x_j$的隐向量$v_j$有所帮助。这样$w_{ij}=⟨v_i,v_j⟩$就有足够多的样本进行学习。
乍看上述式子的时间复杂度为$O(n^2)$,$n$是特征的数量,但是重写上述方程,可以得到:
$$
\begin{aligned}
\sum_{i=1}^{n-1}\sum_{j=i+1}^n(\boldsymbol{v}_i^T \boldsymbol{v}_j)x_ix_j
&= \frac{1}{2}\left(\sum_{i=1}^n\sum_{j=1}^n(\boldsymbol{v}_i^T \boldsymbol{v}_j)x_ix_j-\sum_{i=1}^n(\boldsymbol{v}_i^T \boldsymbol{v}_i)x_ix_i\right)\\
&=\frac{1}{2}\left(\sum_{i=1}^n\sum_{j=1}^n\sum_{l=1}^kv_{il}v_{jl}x_ix_j-\sum_{i=1}^n\sum_{l=1}^k v_{il}^2x_i^2\right)\\\
&=\frac{1}{2}\sum_{l=1}^k\left(\sum_{i=1}^n(v_{il}x_i)\sum_{j=1}^n(v_{jl}x_j)-\sum_{i=1}^nv_{il}^2x_i^2\right)\\
&=\frac{1}{2}\sum_{l=1}^k\left(\left(\sum_{i=1}^n(v_{il}x_i)\right)^2-\sum_{i=1}^n (v_{il}x_i)^2\right)\\
\end{aligned}
$$
可以看出上述的时间复杂度为$O(kn)$。因此,FM能够解决LR进行特征组合学习时,遇到的稀疏特征学习问题以及学习的复杂度高问题。
GBDT
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree)。是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结果累加起来做预测。近些年因为广泛引用于搜索排序,而引起大家关注。GBDT本身也可以做排序学习,但更多的和其他排序模型结合起来一起做排序。下面要介绍的是两种和线性模型结合起来做排序的典型方法。
GBDT+LR
GBDT+LR方法是Facebook2014年提出在论文Practical Lessons from Predicting Clicks on Ads at Facebook提出的点击率预估方案。其动机主要是因为LR模型中的特征组合很关键, 但又无法直接通过特征笛卡尔积解决,只能依靠人工经验,耗时耗力同时并不一定会带来效果提升。如何自动发现有效的特征、特征组合,弥补人工经验不足,缩短LR特征实验周期,是亟需解决的问题。Facebook 2014年的文章介绍了通过GBDT(Gradient Boost Decision Tree)解决LR的特征组合问题。核心思想是利用GBDT训练好的多棵树,某个样本从根节点开始遍历,可以落入到不同树的不同叶子节点中,将叶子节点的编号作为GBDT提取到的高阶特征,该特征将作为LR模型的输入。首先简要介绍下GBDT。
GBDT是基于Boosting 思想的ensemble模型,由多棵决策树组成,具有以下优点:
- 对输入特征的分布没有要求(特征的量纲、取值范围无关,故可以不用做归一化,不过GBDT主要适用于稠密特征,不适用于高维稀疏特征)
- 学习模型可以输出特征的相对重要程度,可以作为一种特征选择的方法
- 对数据字段缺失不敏感
- 根据熵增益自动进行特征转换、特征组合、特征选择和离散化,得到高维的组合特征,省去了人工转换的过程,并且支持了多个特征的Interaction
原论文中的模型结构如下:
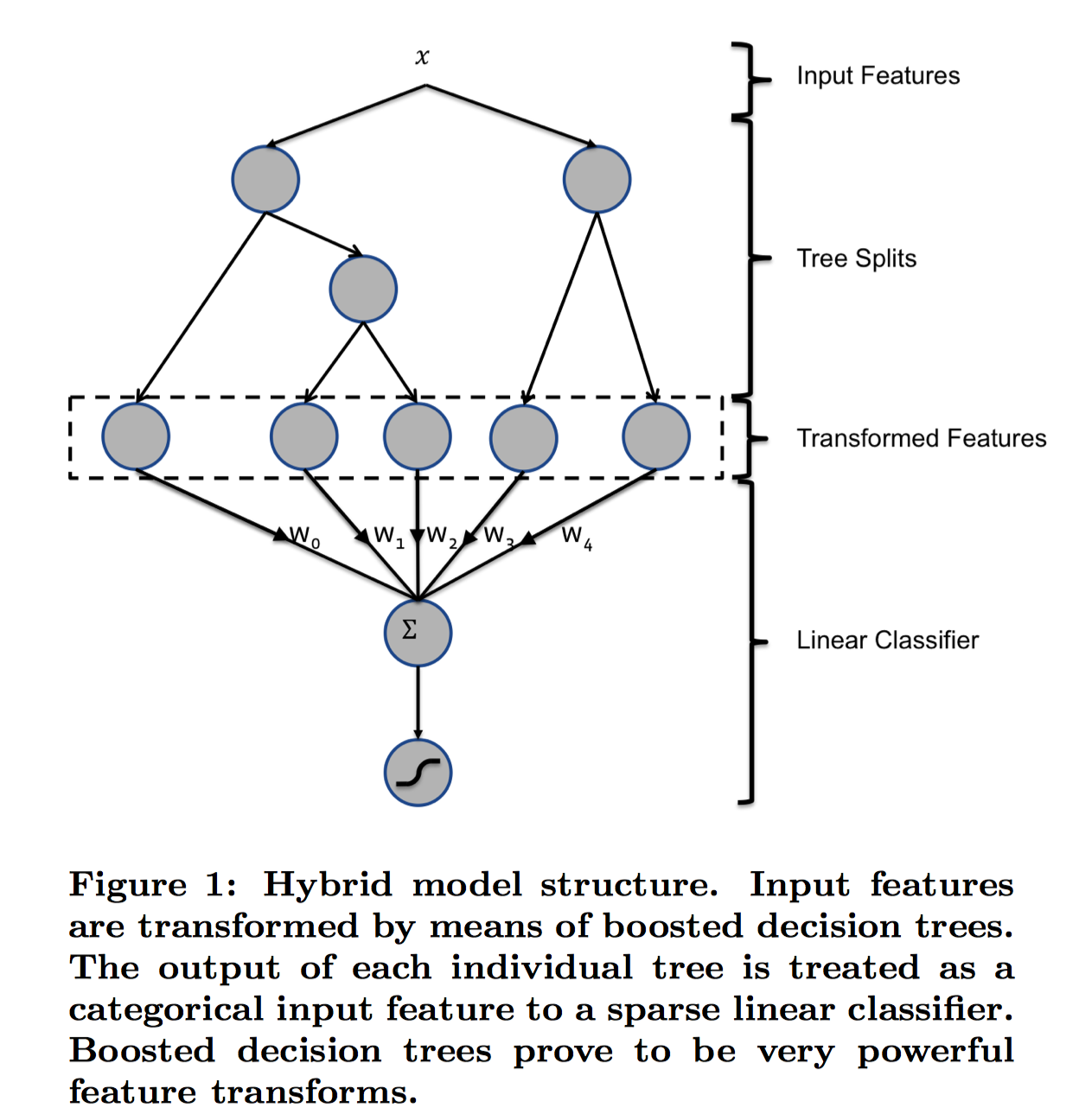
图中$\boldsymbol{x}$是一个样本,$\boldsymbol{x}$两个子节点对应两棵子树Tree1、Tree2为通过GBDT模型学出来的两颗树。遍历两棵树后,$\boldsymbol{x}$样本分别落到两棵树的不同叶子节点上,每个叶子节点对应提取到的一个特征,那么通过遍历树,就得到了该样本对应的所有特征。由于树的每条路径,是通过最小化均方差等方法最终分割出来的有区分性路径,根据该路径得到的特征、特征组合都相对有区分性,效果理论上不会亚于人工经验的处理方式。 最后,将提取到的叶子节点特征作为LR的输入。
GBDT模型的特点,非常适合用来挖掘有效的特征、特征组合。业界不仅GBDT+LR融合有实践,GBDT+FM也有实践,2014 Kaggle CTR竞赛冠军就是使用GBDT+FM,可见,使用GBDT融合其它模型是非常值得尝试的思路。另外,GBDT树模型可以使用目前主流的XGBoost或者LightGBM替换,这两个模型性能更好,速度更快。
GBDT+FM
GBDT+LR排序模型中输入特征维度为几百维,都是稠密的通用特征。这种特征的泛化能力良好,但是记忆能力比较差,所以需要增加高维的(百万维以上)内容特征来增强推荐的记忆能力,包括物品ID,标签,主题等特征。GBDT不支持高维稀疏特征,如果将高维特征加到LR中,一方面需要人工组合高维特征,另一方面模型维度和计算复杂度会是$O(n^2)$级别的增长。所以设计了GBDT+FM的模型如图所示,采用Factorization Machines模型替换LR。
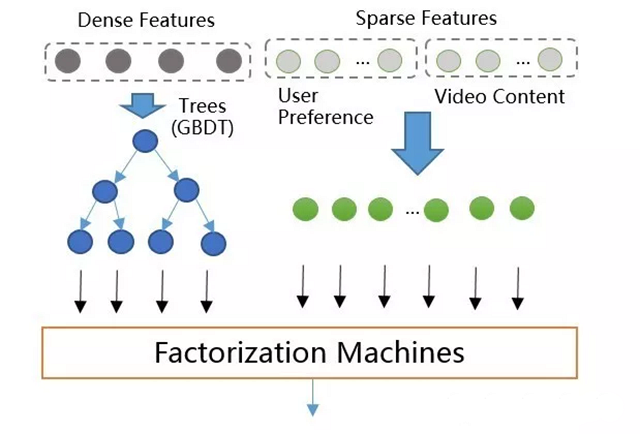
该模型既支持稠密特征,又支持稀疏特征。其中,稠密特征通过GBDT转换为高阶特征(叶子节点编号),并和原始低阶稀疏特征作为FM模型的输入进行训练和预测,并支持特征组合。且根据上述,FM模型的复杂度降低到$O(n)$(忽略隐向量维度常数)。
DNN
Youtube
GBDT+FM模型,对embedding等具有结构信息的深度特征利用不充分,而深度学习(Deep Neural Network)能够同时对原始稀疏特征(通过嵌入式embedding方式)和稠密特征进行学习,抽取出深层信息,提高模型的准确性,并已经成功应用到众多机器学习领域。因此可以将DNN引入到排序模型中,提高排序整体质量。
YouTube 2016发表了一篇基于神经网络的推荐算法Deep Neural Networks for YouTube Recommendations。文中使用神经网络分别构建召回模型和排序模型。简要介绍下召回模型。召回模型使用基于DNN的超大规模多分类思想,即在时刻$t$,为用户$U$(上下文信息$C$)在视频库$V$中精准的预测出用户想要观看的视频为$i$的概率,用数学公式表达如下:
$$
p(w_t=i|U,C)=\frac{e^{v_i^T u}}{\sum_{j \in V} e^{v_j^Tu}}
$$
向量$u$是信息的高维embedding,而向量$v$则是视频的embedding向量,通过u与v的点积大小来判断用户与对应视频的匹配程度。所以DNN的目标就是在用户信息和上下文信息为输入条件下学习视频的embedding向量$v$以及用户的embdedding向量$u$。召回模型架构如下:
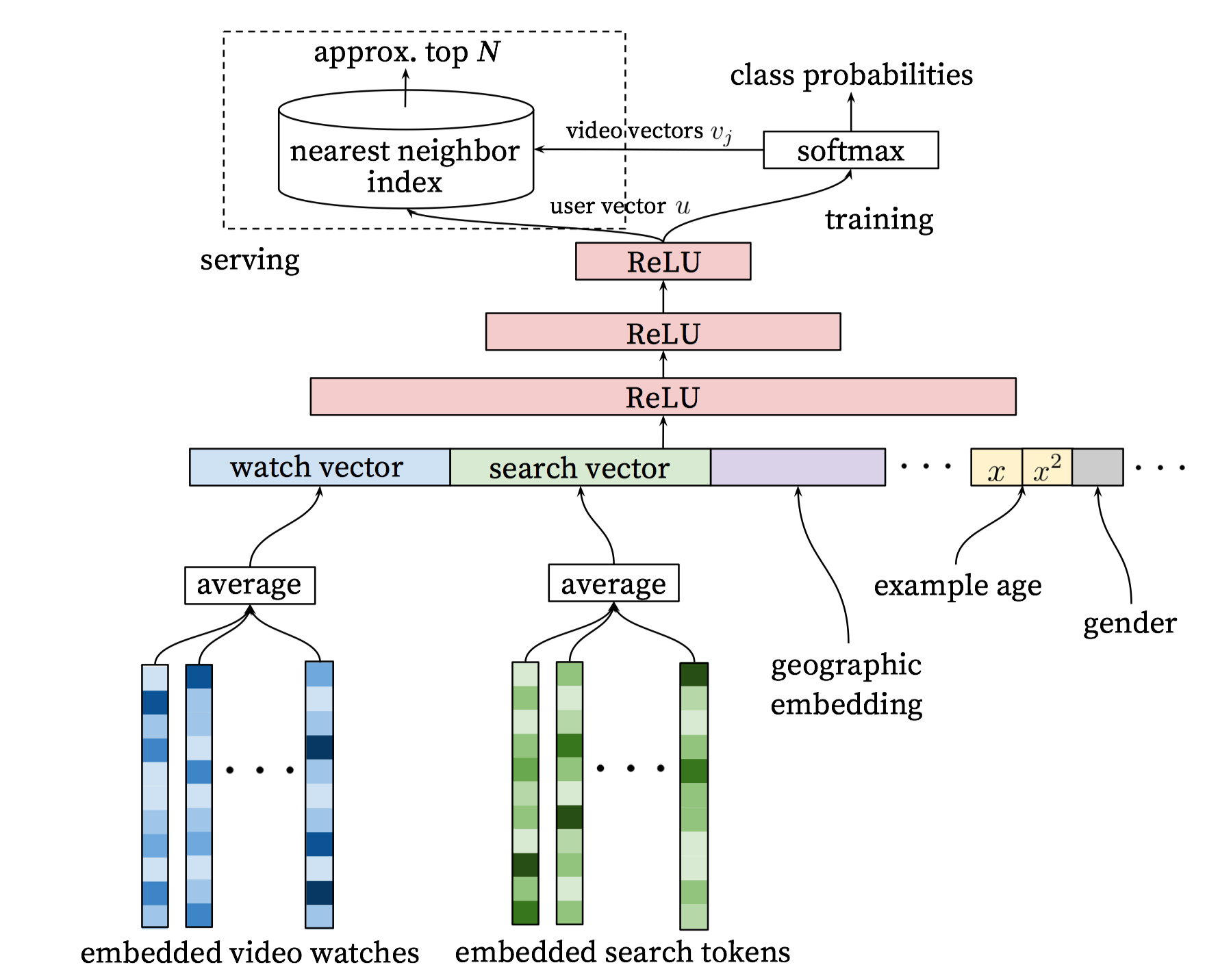
分为离线计算和在线服务两个部分。离线计算的时候,通过embedding提取用户的不同特征(历史观影序列、搜索词),同类型特征先average,然后再将不同类型特征concat起来,作为MLP的输入,最后一层隐藏层的输出作为用户的embedding向量,再和视频的embedding向量点乘,并用于预测该视频概率。(输出层神经元由所有视频构成,最后一层隐藏层和该视频对应的输出层某个神经元相连接的权重向量就是该视频的embedding)。在线服务的时候,利用学习到的用户embedding和视频embedding,并借助近似近邻搜索,求出TopN候选结果(这里的问题是最后使用的video vectors如何构建的问题,是直接使用最后全连接层的权重还是使用最底下embedded video watches中的各视频的embedding。这个问题已有大神讨论过,见关于’Deep Neural Networks for YouTube Recommendations’的一些思考和实现)
排序模型和上述几乎一样,只不过最后一层输出不是softmax多分类问题,而是logistic regression二分类问题,并且输入层使用了更多的稀疏特征和稠密特征。之所以在候选阶段使用softmax,是因为候选阶段要保证多样性等,因此面向的是全量片库,使用softmax更合理。而在排序阶段,需要利用实际展示数据(impression data)、用户反馈行为数据来对候选阶段的结果进行校准,由于召回阶段已经过滤了大量的无关物品,因此排序阶段可以进一步提取描述视频的特征、用户和物品关系的特征等。
如下图:
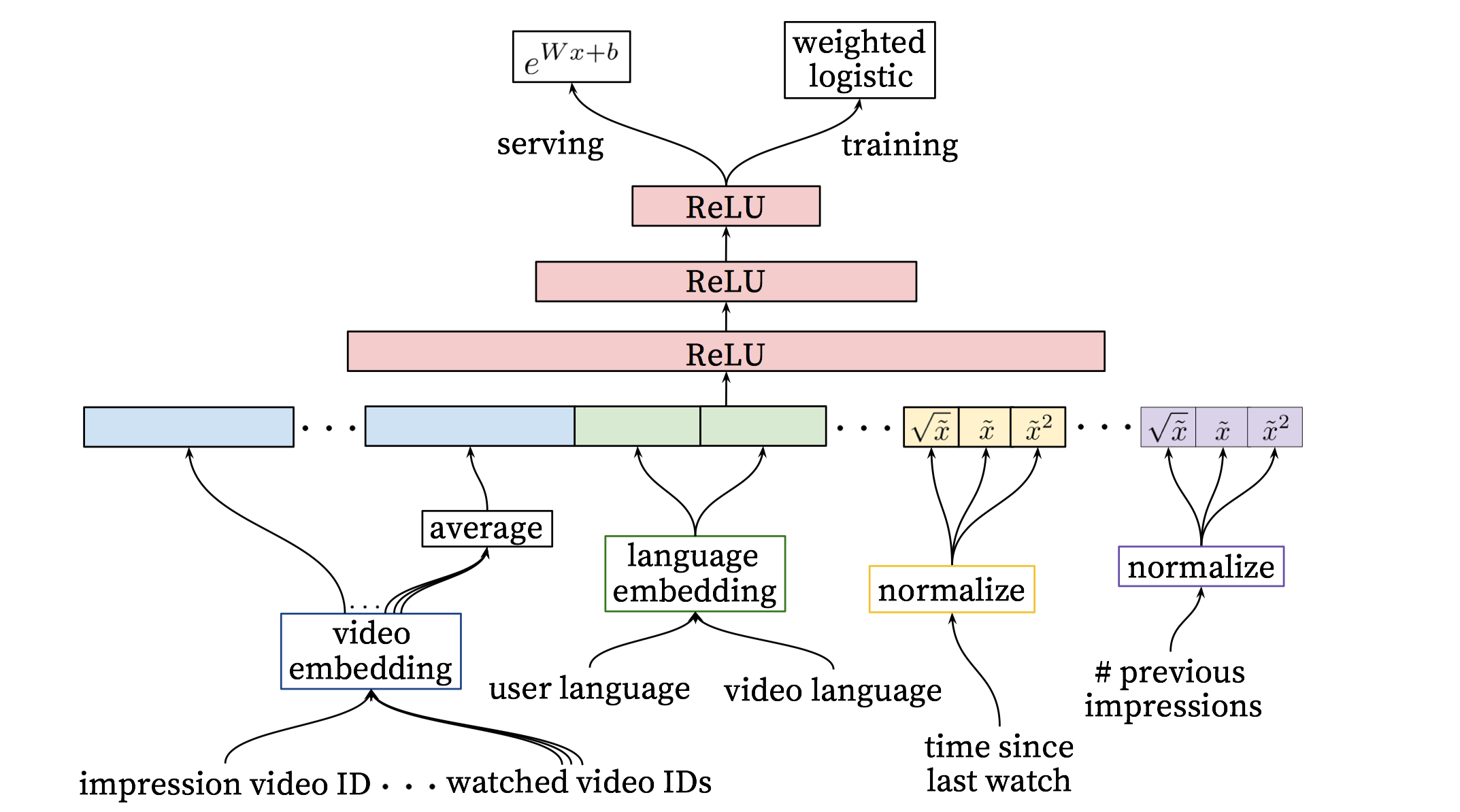
同样分为训练部分和服务部分。训练时,提取了更多关于视频、用户、上下文的特征,其中,稀疏特征通过embedding方式传入,稠密特征通过归一化、幂率变换等传入,最后使用加权的logistic regression来训练,权重使用观看时长表示,最大化$P(y|\boldsymbol{x})$的概率。
训练好后,使用$e^{Wx+b}$来计算得分并排序即可(不需要进行sigmoid操作,排序时二者等价)。
Google Play: Wide & Deep Learning
该模型是Google 2016论文 Wide & Deep Learning for Recommender Systems 提出的,用于Google Play应用中app的推荐。该模型将线性模型组件和深度神经网络进行融合,形成了在一个模型中实现记忆和泛化的宽深度学习框架。其中,宽度学习组件使用广义的线性模型(也可以看做是单层的感知器);而深度学习组件使用多层感知器。结合这两种学习技术,能够使得推荐系统同时捕捉到记忆性和泛化性。宽度学习组件的输入主要是稀疏特征以及稀疏特征间转换后的交叉特征,能够实现记忆性,记忆性体现在从历史数据中直接提取特征的能力;深度学习组件的输入包括了稠密特征以及稀疏特征,其中稀疏特征通过embedding方式转换成稠密特征,能够实现泛化性,泛化性体现在产生更一般、抽象的特征表示的能力。我们希望在宽深度模型中的宽线性部分可以利用交叉特征去有效地记忆稀疏特征之间的相互作用,而在深层神经网络部分通过挖掘特征之间的相互作用,提升模型之间的泛化能力。下图是宽深度学习模型框架:
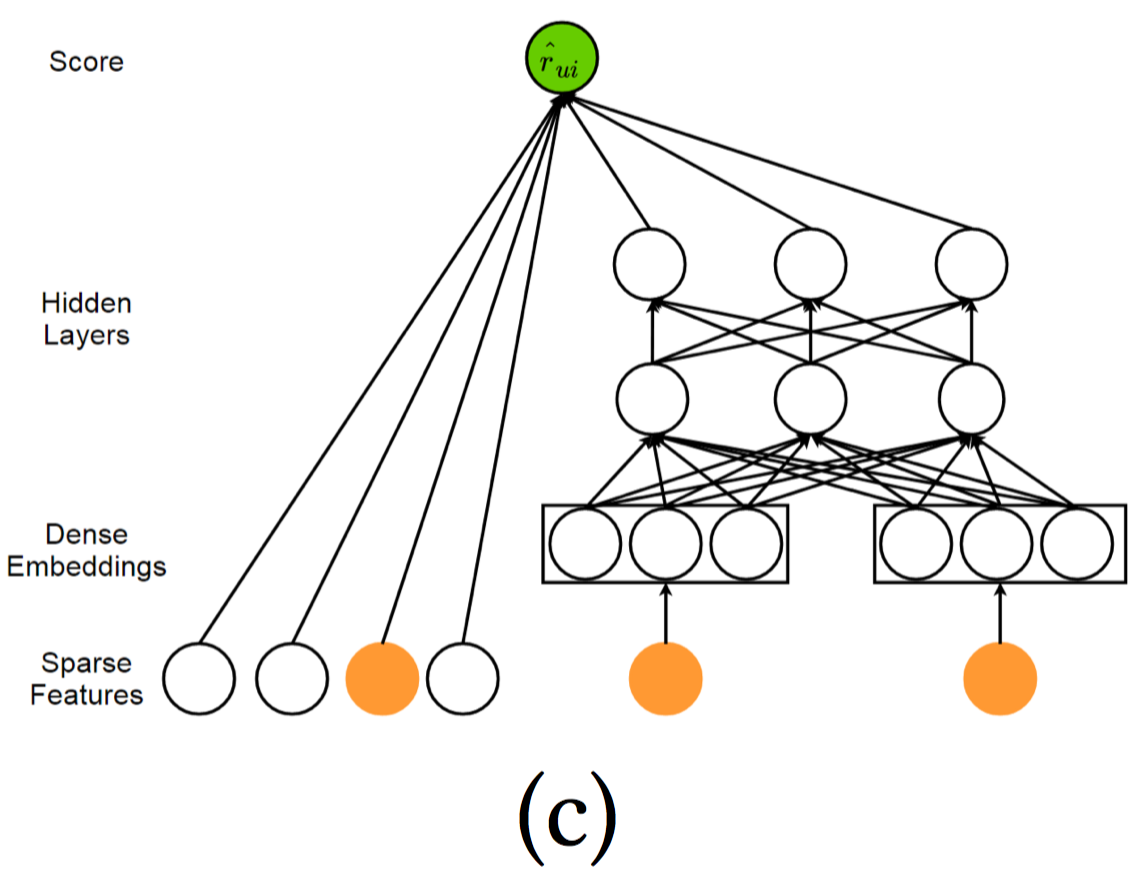
如上图,左侧为宽度组件,使用单层感知器,直接和输出相连接。右侧为深度组件,使用多层感知器。
wide learning 形式化为:$y=W_{\text{wide}}^T \{\boldsymbol{x}, \phi(\boldsymbol{x}\} + b$, $\{\boldsymbol{x}, \phi(\boldsymbol{x})\}$是concatenated起来的特征,其中$\boldsymbol{x}$是原始稀疏特征,$\phi(\boldsymbol{x})$是手动精心设计的、变换后的稀疏特征,例如使用叉乘来提取特征间的关联(特征组合)。这个特征需要精心设计,取决于你希望模型记住哪些重要信息。deep learning形式化为:$a^{l+1} = W^T_{deep} a^{l} + b^{l}$,deep组件的输入包括连续值特征以及稀疏特征。其中稀疏特征通过embedding方式转换成稠密特征。sigmoid激活后:
$$
P(\hat{r}_{ui}=1|x) = \sigma(W^T_{\text{wide}}\{\boldsymbol{x},\phi(\boldsymbol{x})\} + W^T_{\text{deep}}a^{(l_f)}+ bias)
$$
$\hat{r}_{ui}=1$表示正反馈行为,$P(\hat{r}_{ui}=1|x)$是正反馈行为的概率。上述手工设计的特征在很大程度上影响模型的性能。
在Google Play App推荐应用上,针对该场景设计的神经网络架构如下:
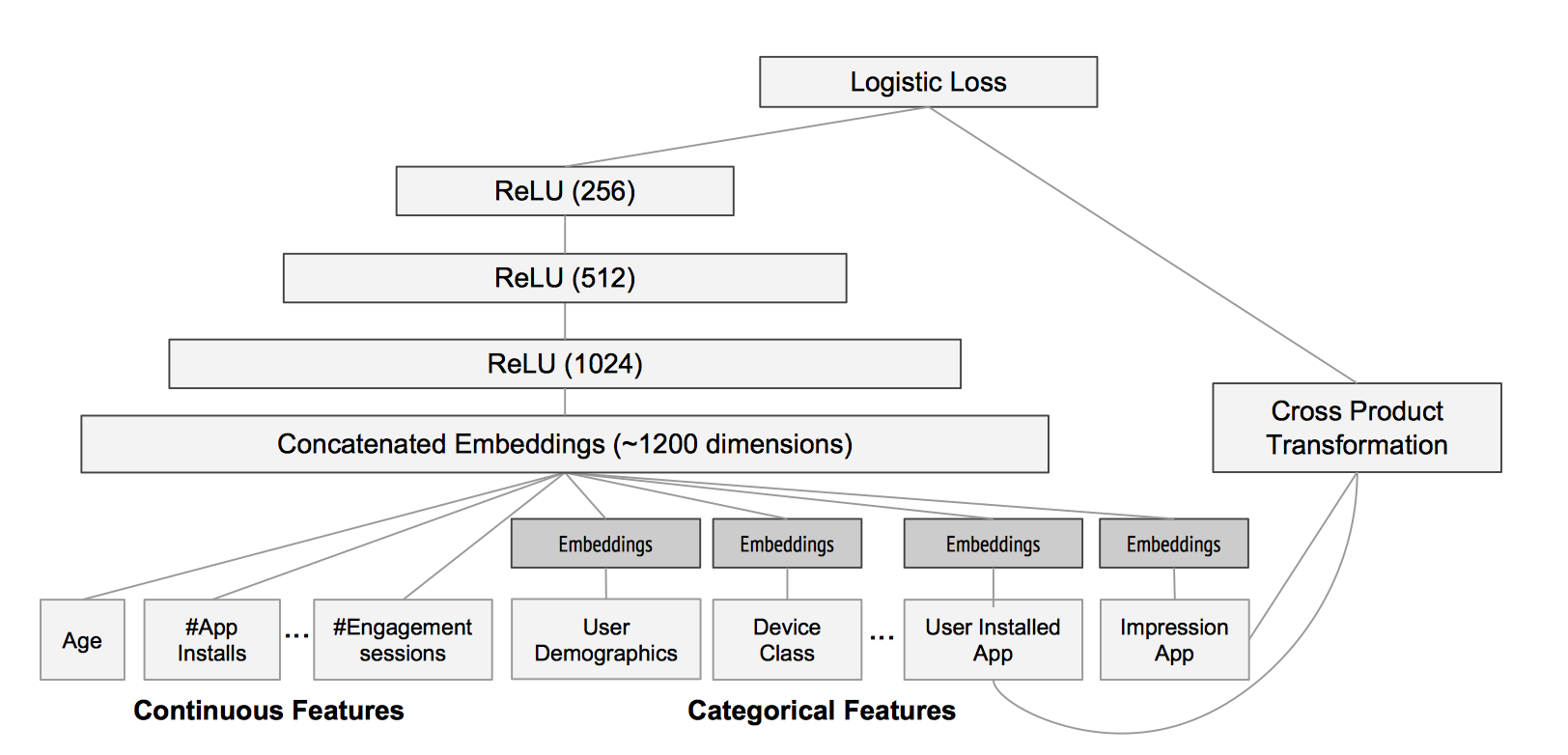
从上图可以看出,宽度组件主要从稀疏特征(类别特征)中进行特征组合操作;深度组件从原始稠密特征(连续值特征),以及将稀疏特征通过embedding方式,输入到MLP提取高阶特征。宽度和深度组件输出结果相加,并通过sigmoid函数激活,最后一起联合优化Logistic Loss进行学习。
Deep Factorization Machine
DeepFM是2017年提出的一种端到端模型,解决了上述Wide & Deep Learning中手工设计特征的问题。DeepFM整合了Factorization Machine(FM)和MLP。其中FM能够建模特征间的低阶关联,MLP能够建模特征间的高阶关联。
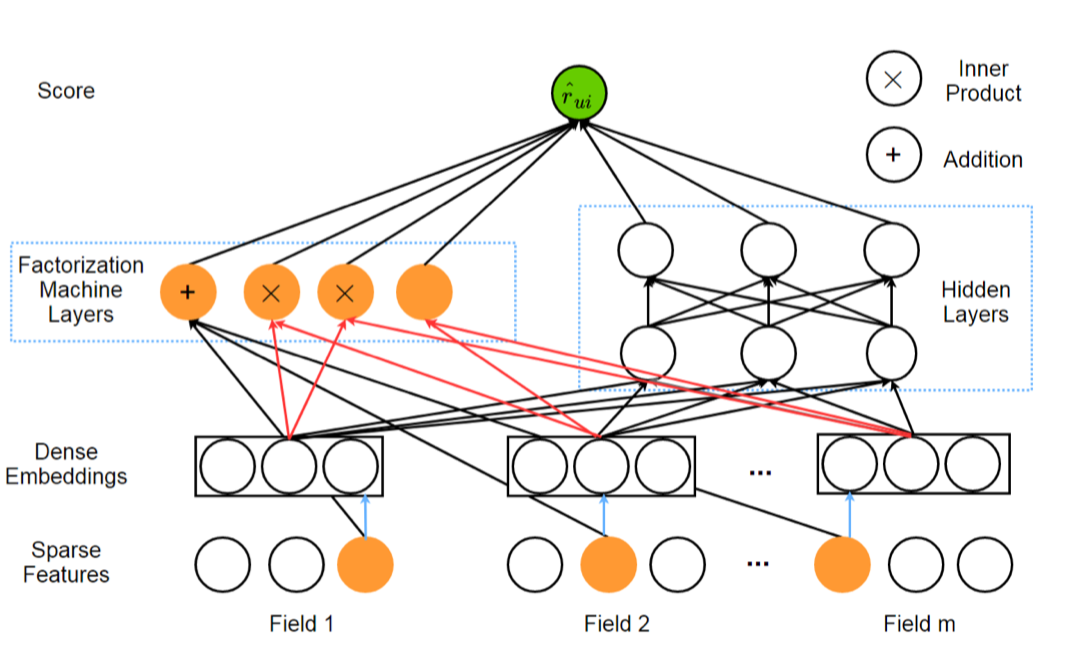
DeepFM不需要特征工程,它将Wide-Deep Learning中的Wide组件使用FM替换。DeepFM的输入是一个M-fields的数据,每条数据由$(u,i)$数据对组成,$u、i$分别指的是用户和商品特征。最终预测的结果是:
$$
P(\hat{r}_{ui}=1|\boldsymbol{x}) = \sigma(y_{\text{FM}}(\boldsymbol{x}) + y_{\text{MLP}}(\boldsymbol{x}))
$$
要注意,指向FM层中inner product的橙色的线的dense embedding代表的是FM模型中二阶项的$w_{ij}=⟨v_i,v_j⟩$中的$v_i$和$v_j$。另外,还可以看到原始稀疏特征有一条直接指向FM层中的Addition黑色的线,这代表的是FM中的一阶项的$⟨w, x_j⟩$中的$x$,$x$是原始稀疏特征(取值0/1)。而指向MLP中的黑色的线dense embedding是稀疏特征嵌入后的稠密特征。因此每个特征值实际上要学习两种embedding(FM二阶项、MLP输入)。
上述输入侧中的稀疏特征既可以包括类别型特征,又可以包括连续值特征,其中类别型特征使用one_hot方式来表示,连续值特征使用连续值本身来表示(可能需要归一化处理),也可以先根据其分布离散化后,再使用one_hot方式表示(图上画出来的架构应该更倾向于后者)。稀疏特征再通过embedding层转换为稠密特征输入到MLP中。另外,之所以说不需要人工特征工程,是因为交叉特征工作是模型自动进行的,在输入侧不需要手动进行交叉特征处理。
DCN
DCN是论文Deep & Cross Network for Ad Click Predictions中提到的架构,该论文是2017年四位在谷歌的中国人发表的一篇文章。用复杂网络结构做CTR预估。相比于DeepFM,主要优势在于能够学习更高阶的特征组合。在DeepFM中,宽度组件中FM的特征组合阶数为2,而在DCN中可以任意阶。模型结构如下:
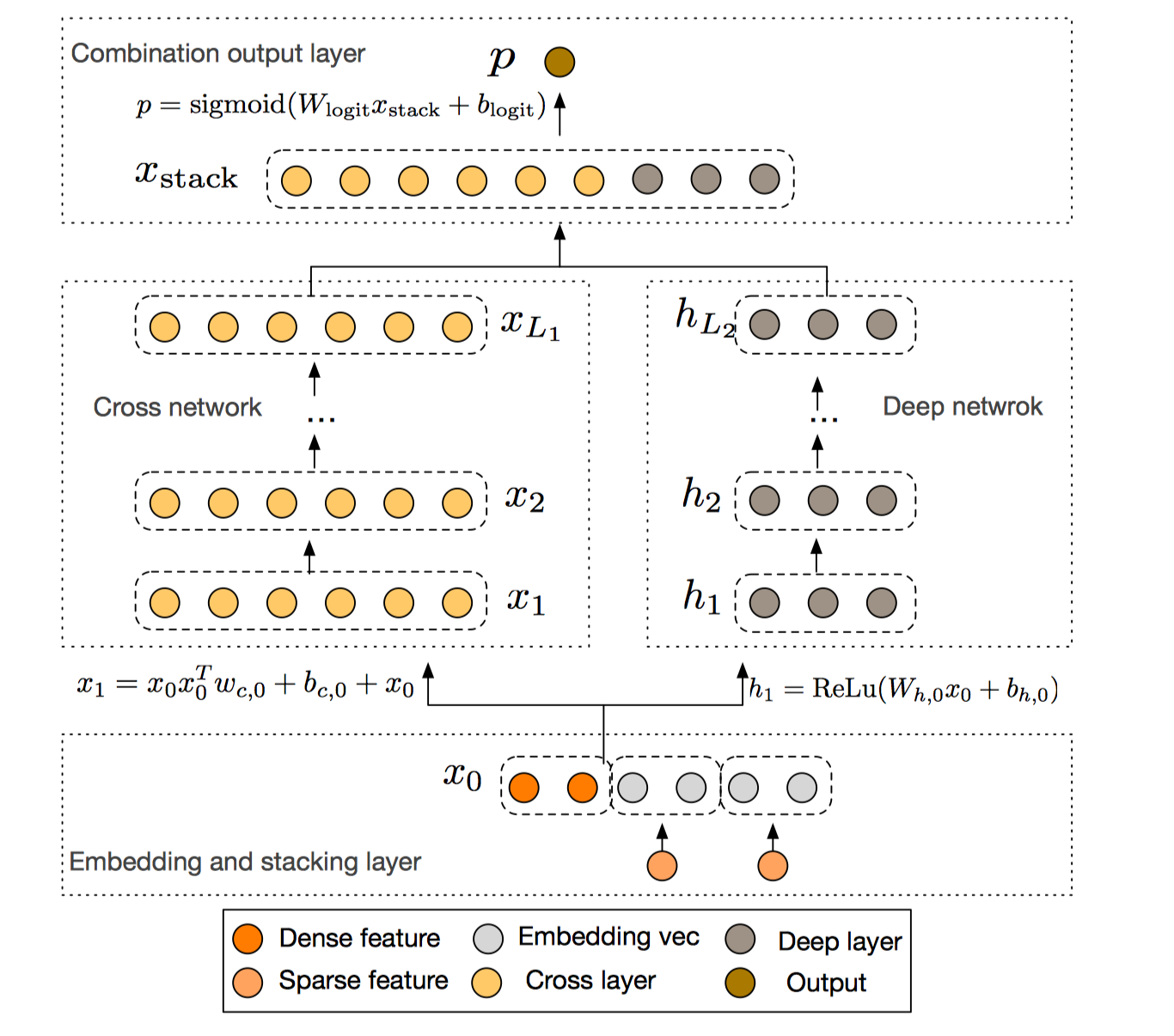
在输入侧,稀疏特征通过embedding层转化为稠密特征后,和连续特征concat起来,一起作为模型的输入。因此,输入层面只有embedding column+continuous column, 特征组合在网络结构中自动实现。上图右侧是常见的MLP深度网络,左侧是本文提出的交叉网络。
对于cross network, 首先将输入embedding column + continous column定义为$x_0 \in \mathbb{R}^d$,则第$l+1$层的cross layer:
$$
x_{l+1} = x_0 x_l^Tw_l + b_l + x_l = f(x_l,w_l,b_l) + x_l
$$
其中$w_l$($w_l \in \mathbb{R}^{d}$)和$b_l$($b_l\in \mathbb{R}^{d}$)为第$l$层的参数。Cross Network这部分网络的总参数量非常少,仅仅为$L_c \times d \times 2$,每一层的维度也都保持一致,最后的output依然与input维度相等。另一方面,特征交叉的概念体现在每一层,当前层的输出的高阶特征都要与第一层输入的原始特征做一次两两交叉(外积)。至于为什么要再最后又把$x_l$给加上,可能是为了借鉴ResNet的思想,最终交叉层网络$f:\mathbb{R}^d \rightarrow \mathbb{R}^{d}$,要去拟合的是$x_{l+1} - x_{l}$这一项残差。外积操作示意图如下:
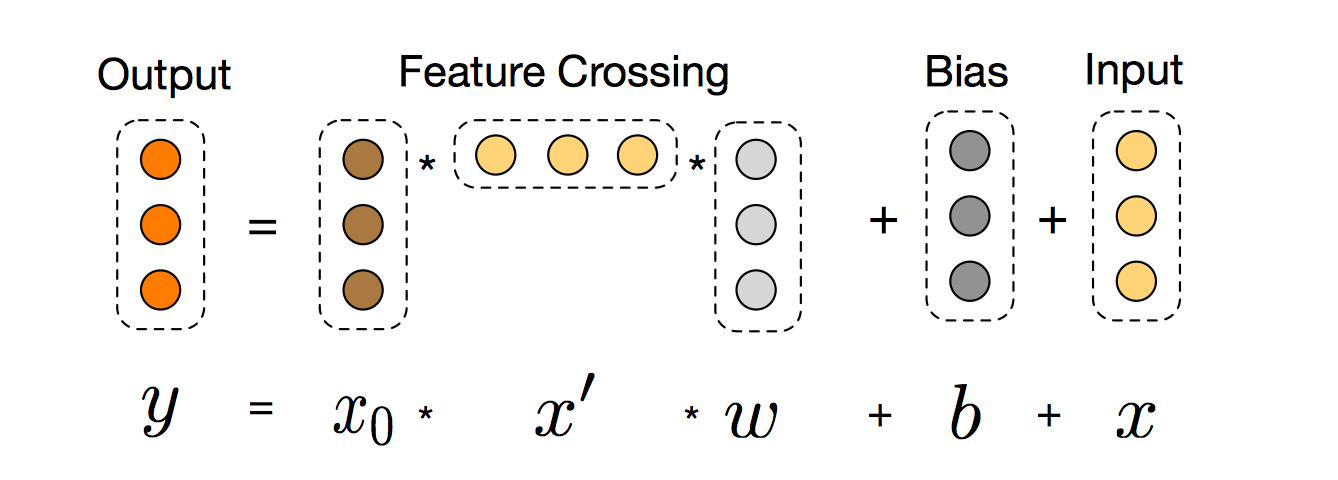
可以看出,上述的交叉特征操作面向的是stack后的稠密特征$x_0$(embedding+continuous)以及cross layer输出的稠密特征$x_l$之间的。这和FM以及DeepFM中基于原始稀疏特征进行交叉特征不大一样。
Deep Network侧就不多说了,和传统DNN一样,input进来,简单的N层full-connected layer的叠加,所以参数量主要还是在deep侧。
最后Cross Network输出和Deep Network输出concat在一起,使用一个Logistic层预测$P(y=1|\boldsymbol{x})$即可。
Pairwise Ranker
点级排序学习技术完全从单个物品的分类得分角度计算,没有考虑物品之间的顺序关系。而对级排序学习技术则偏重于对物品顺序关系是否合理进行判断,判断任意两个物品组成的物品对$<\text{item 1} , \text{item 2}>$,是否满足顺序关系,即,item 1是否应该排在 item 2 前面(相比于item 2, 用户更偏好于item 1)。具体构造偏序对的方法见Basic一节。支持偏序对的模型也有很多,例如支持向量机、BPR、神经网络等。然而,无论使用哪一种机器学习方法,最终目标都是判断对于目标用户,输入的物品对之间的顺序关系是否成立,从而最终完成物品的排序任务来得到推荐列表。
RankSVM
RankSVM来自于2002年发表的一篇论文Optimizing Search Engines using Clickthrough Data,截止到2018.12.12,引用量4208。它是在SVM基础上优化物品偏序对的pairwise损失。在SVM中,为实现软间隔最大化, 需要满足约束$y_i(w^Tx_i +b) > 1- \xi_i$,$y_i$代表样本$x_i$是正样本(1)还是负样本(-1)。而RankSVM是典型的pairwise方法,考虑两个有偏序关系的物品对,训练样本为$x_{u,i}-x_{u,j}$,则优化目标为:
$$
\begin{split}
& min_{w,b} \frac{1}{2}||w||^2 + C\sum_{i=1}^n \xi_{uij} \\
s.t., & y_{uij}(w^T(x_{u,i}-x_{u,j})) \geq 1-\xi_{uij}, \xi_{uij}\geq 0
\end{split}
$$
此时,$y_{uij}$代表用户$u$对$i$的喜爱程度比对$j$的喜爱程度高时,为1,否则为-1。上述优化等价于优化如下Hinge Loss:
$$
L_{w}=\sum_{(u,i,j)\in \mathcal{S} \cup \mathcal{D}}[1- y_{uij}\cdot w^T x_{u,i}+ y_{uij} \cdot w^Tx_{u,j}]_{+}
$$
其中,$S$集合中,$y_{uij}=1$,$D$集合中,$y_{uij}=-1$。$[z]_{+}=max(0,z)$。
上述的改进工作一般是围绕不同pair有序对权重不同展开,即$\xi_{uij}$前会加个权重。
Hinge Ranking Loss是排序学习中非常重要的损失函数之一,大部分做ranking任务的模型都会采用。
BPR
BPR(Bayesian Personalized Ranking)来自于2009年发表的一篇论文BPR: Bayesian Personalized Ranking from Implicit Feedback,截止到2018.12.12,引用量达到1550。它基于这样的假设,用户对交互过物品比起其他没有被交互过的物品而言更喜爱(而对于用户交互过的物品对之间不假设偏序关系,同样,对于用户没有交互过的物品对之间也不假设偏序关系)。从而将 “用户-物品 ”交互矩阵可以转换为物品对偏序关系矩阵。如下图所示:
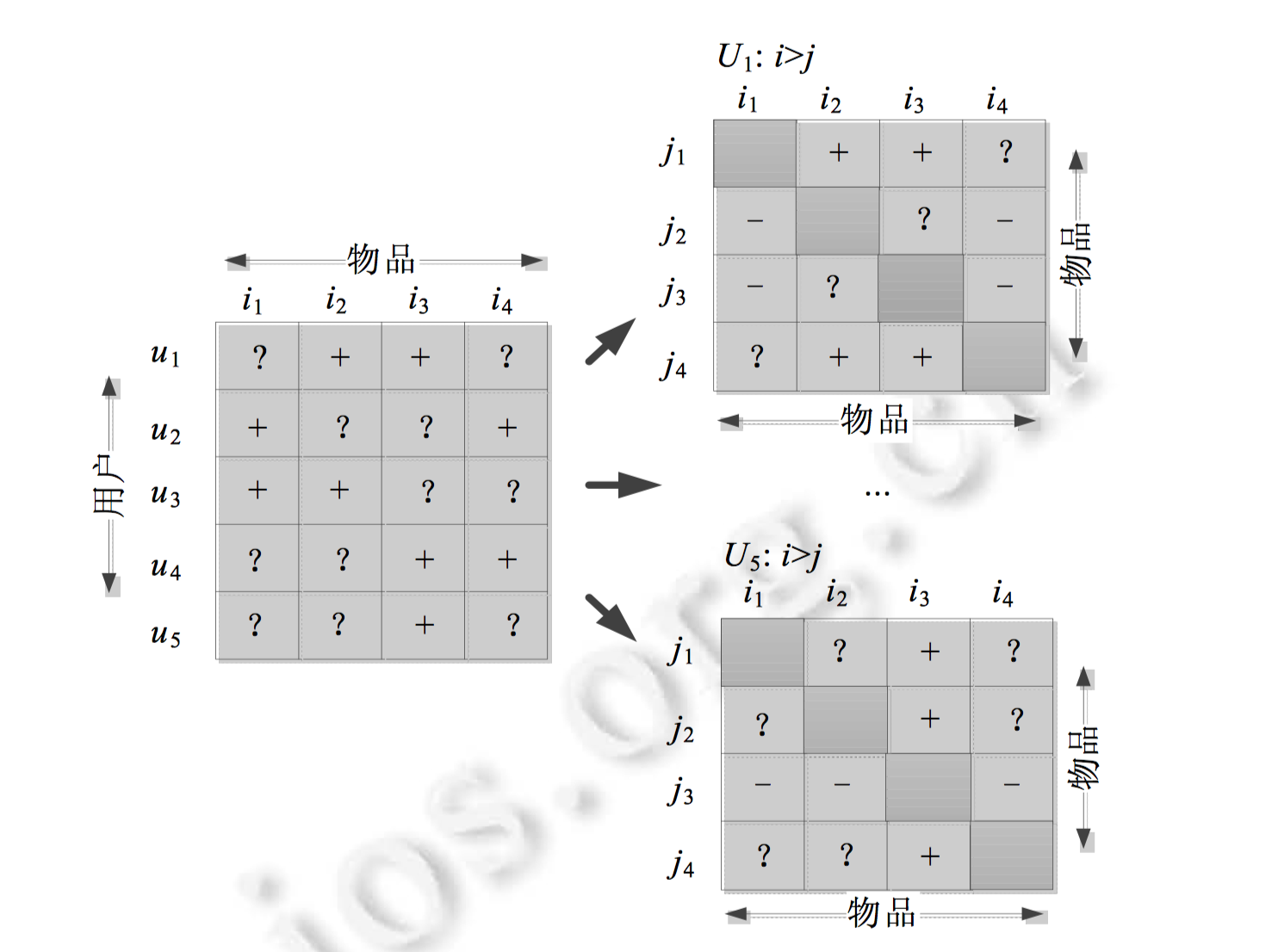
上述是交互矩阵转换为物品偏序对矩阵的过程。所有用户的物品偏序对矩阵可以表示成3元组,$⟨u,i,j⟩$,该三元组的含义为:相对于物品$j$,用$u$更喜欢物品$i$,使用符号$i >_u j$表示。令$D_s=\{(u,i,j)|i \in I_u^{+} ∧ j \in I \backslash I_u^{+}\}$。$I_u^{+}$表示用户$u$交互过的物品集合。
在此基础上 ,作者提出了基于贝叶斯的个性化排序算法,其目标最大化物品排序的后验概率。
$$
\prod_{(u,i,j) \in D_s} P(\Theta|i>_uj) \propto \prod_{(u,i,j) \in D_s} P(i>_uj|\Theta) P(\Theta)
$$
似然部分,
$$
P(i >_u j|\Theta) = \sigma(\hat{x}_{uij}(\Theta))=\sigma(\hat{x}_{ui}(\Theta)-\hat{x}_{uj}(\Theta))
$$
先验部分$P(\Theta)$可以根据参数的假设分布选择,如高斯分布。
对后验概率取log,并取反后得到Logistic Ranking Loss,也是BPR的优化目标(BPR-OPT):
$$
\begin{align}
L(\Theta) &= -\left(\sum_{(u,i,j) \in D_S}ln P(\Theta|i>_uj)+ln P(\Theta) \right) \\
&= \sum_{(u,i,j)\in D_s} -ln(\sigma(\hat{x}_{ui}(\Theta)-\hat{x}_{uj}(\Theta))) + \lambda_{\Theta} ||\Theta||^2
\end{align}
$$
$\Theta$是使用的模型的参数,可以使用不同的模型,例如:使用矩阵分解,则$\Theta=\{P,Q\}$, $P$是用户隐因子矩阵,$Q$是物品隐因子矩阵,则预测值$\hat{x}_{ui}(\Theta) = p_u^T q_i$,此时损失为:
$$
\sum_{(u,i,j)\in D_s} -ln \sigma(p_u^Tq_i-p_u^Tq_j)+\lambda(||p_u||^2+||q_i||^2)
$$
这篇文章的主要贡献就是提出了上述BPR优化目标。BPR优化目标中的模型$\Theta$可以使用多种多样的模型,包括协同过滤、神经网络等等。很多神经网络方法会采用该损失。
Logistic Ranking Loss和Hinge Ranking Loss是排序学习中非常重要的两种损失函数。大部分模型,包括神经网络都会采用,不同模型间的差异在于得分函数$\hat{x}_{ui}$的不同,例如设计不同神经网络架构来预测该得分。
还有个模型是RankNet,和BPR损失非常像,会在下面介绍LambdaMART的时候提到。
WRAP
WARP(Weighted Approximate-Rank Pairwise)是2011年论文WSABIE: Scaling Up To Large Vocabulary Image Annotation提出的一种Pairwise排序损失,截止2018.12.12,引用量为455。WARP主要用于优化Top K推荐。WARP在Hinge Loss基础上考虑了正样本的排序。通常的Top K推荐只关注前K个结果,忽略了对某些排名很低的正样本的惩罚。WARP引入加权排序指标,对那些排名很低的正样本进行惩罚,加大权重,使得模型更关注这些正样本的学习。样本的权重:
$$
w_{ui} = log(rank(u,i)+1)
$$
$rank(u,i)$代表用户$u$推荐结果中物品$i$的排名。越大说明排名越低,则权重越高。在Hinge Loss改进:
$$
L_{WARP}=\sum_{u \in \mathcal{U}} \sum_{(i,j)\in \mathcal{D}_u} w_{ui}[1+f_{u,j}-f_{u,i}]_{+}
$$
其中,$f_{u,i}$代表用户$u$对$i$的预测值,$f_{u,j}$同理。可以使用矩阵分解中点乘形式来预测。$[z]_{+}=max(0,z)$是hinge loss损失。推导即,对正样本$i$的预测值要比$j$大一个margin值,即,$f_{u,i}-f_{u,j}>1$, 则:$f_{u,j}-f_{u,i} < -1$, 则:$f_{u,j}-f_{u,i} + 1< 0$, 对于满足该式的损失为0,否则损失为$f_{u,j}-f_{u,i}+1$,即为$[1+f_{u,j}-f_{u,i}]_{+}$。
优化的时候,作者提出了一种采样的方法来估计$rank(u,i)$。即对每对$(u,i)$, 一直采样,直到有一个样本$j$不满足$f_{u,i}-f_{u,j}>1$, 记采样次数为$N$, $J$为所有物品的个数。则$rank(u,i) \approx \lfloor {\frac{J}{N}} \rfloor$。这个可以直观理解,采样次数$N$越小,说明很容易采到$j$, 即$i$的排名不是很高($rank(u,i)$值大),因此对其进行惩罚,让模型关注该正样本$i$, 使得优化后该样本排名能高一些。
DNN
大部分用于做排序的深度神经网络模型都会采用RankSVM中提出的pairwise Hinge Loss或BPR中的pairwise Logistic Loss,主要差别仅在于打分模型不同。下面列举部分:
Listwise Ranker
LambdaMART
LambdaMART是LambdaRank的提升树版本,而LambdaRank又是基于pairwise的RankNet。因此LambdaMART本质上也是属于pairwise排序算法,只不过引入Lambda梯度后,还显示的考察了列表级的排序指标,如NDCG等,因此,也可以算作是listwise的排序算法。LambdaMART由微软于2010年的论文Adapting Boosting for Information Retrieval Measures提出,截止到2018.12.12,引用量达到308。本小节主要介绍LambdaMART,参考文章 From RankNet to LambdaRank toLambdaMART: An Overview。
LambdaMART是基于 LambdaRank 算法和 MART (Multiple Additive Regression Tree) 算法,将排序问题转化为回归决策树问题。MART 实际就是梯度提升决策树(GBDT, Gradient Boosting Decision Tree)算法。GBDT 的核心思想是在不断的迭代中,新一轮迭代产生的回归决策树模型拟合损失函数的梯度,最终将所有的回归决策树叠加得到最终的模型。LambdaMART 使用一个特殊的 Lambda 值来代替上述梯度,也就是将 LambdaRank 算法与 MART 算法结合起来,是一种能够支持非平滑损失函数的学习排序算法。
首先是RankNet,RankNet和BPR非常像。创新之处都在于,原本Ranking常见的评价指标都无法求梯度,因此没法直接对评价指标做梯度下降,而它们将不适宜用梯度下降求解的 Ranking 问题,转化为对偏序概率的交叉熵损失函数的优化问题,从而适用梯度下降方法。
RankNet 的终极目标是得到一个带参的算分函数:
$$
s = f(x; w)
$$
于是,根据这个算分函数,我们可以计算物品 $x_i$ 和 $x_j$ 的得分 $s_i$ 和 $s_j$。
$$
s_i = f(x_i; w)\quad s_j = f(x_j; w)
$$
然后根据得分计算二者的偏序概率:
$$
P_{ij} = P(x_i \rhd x_j) = \frac{1}{1 + \exp\bigl(-\sigma \cdot (s_i - s_j)\bigr)}
$$
其中,$\sigma$是Sigmoid函数的参数,决定了Sigmoid曲线的形状。(不得不说,作者定义的这个Sigmoid函数的参数太坑爹了,正常大家会用$\sigma$来表示Sigmoid函数,此处却拿来表示Sigmoid函数的参数,原论文写成了$\sigma (s_i - s_j)$,一开始以为是最外面的Sigmoid函数里头又嵌套了个Sigmoid函数,结果看了大半天,才发现此处的$\sigma$只是个参数,故本文还是加上$\cdot$点乘符号来区分 )
再定义交叉熵为损失函数:
$$
\begin{aligned}
L_{ij} &=
-\bar{P}_{ij}\log P_{ij} - (1 - \bar{P}_{ij})\log (1 - P_{ij}) \\
&= -\frac{1}{2}(1+S_{ij})log P_{ij} -\frac{1}{2}(1-S_{ij}) log(1-P_{ij}) \\
&= -\frac{1}{2}S_{ij}(\log P_{ij} - \log(1-P_{ij})) -\frac{1}{2}(log P_{ij} + \log(1-P_{ij}))\\
&= -\frac{1}{2}S_{ij}\log(\frac{P_{ij}}{1-P_{ij}}) - \frac{1}{2} \log (P_{ij}(1-P_{ij})) \\
&= -\frac{1}{2}S_{ij} \cdot \sigma \cdot (s_i-s_j) - \frac{1}{2}\log ( \frac{\partial P_{ij}}{\partial (\sigma \cdot (s_i - s_j))})\\
&= -\frac{1}{2}S_{ij} \cdot \sigma \cdot (s_i-s_j) - \frac{1}{2} \Bigl(-\sigma \cdot (s_i-s_j)-2\log (1+exp(-\sigma \cdot (s_i-s_j) ))\Bigr) \\
&=\frac12 (1 - S_{ij})\cdot \sigma \cdot (s_i - s_j) + \log\Bigl\{1 + \exp\bigl(-\sigma \cdot (s_i - s_j)\bigr)\Bigr\}
\end{aligned}
$$
上式利用了性质,$P=\frac{1}{1+e^{-x}} \rightarrow x=log (\frac{P}{1-P}), P(1-P)=\frac{\partial P}{\partial x}$。
上式是单个样本的损失,$S_{ij}=\{1,-1,0\}$是标签,$\bar{P}_{ij}$是物品$i$比$j$排序靠前的真实概率,即,$i \rhd j$($S_{ij}=1$)则为1,$j \rhd i$($S_{ij}=-1$) 为0,否则为1/2($S_{ij}=0$)(这个概率定义也是不同于BPR的一个地方)。则:$\bar{P}_{ij}=\frac{1}{2}(S_{ij}+1)$.
最后可以进行梯度下降:
$$
w_k \to w_k - \eta\frac{\partial L}{\partial w_k}.
$$
注意,和BPR一样,算法函数$f(x_i; w)$可以取任何模型,如GBDT、DNN、LR等。
在介绍LambdaRank的动机之前,我们从一张图从Intuition的角度来考察RankNet学习过程中,列表的排序变化。
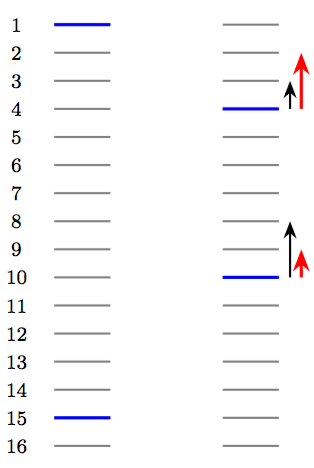
这里每条横线代表一个物品,其中蓝色的表示相关的物品,灰色的则表示不相关的物品。在某次迭代中,RankNet 将物品的顺序从左边变成了右边。于是我们可以看到:
- RankNet 的梯度下降表现在结果的整体变化中是逆序对的下降。左图中,2~14不相关物品都排在了15号相关物品之前,这些不相关物品和15号物品构成的逆序对共13个,因此损失等价于为13;而右图中,将1号相关物品降到了4号,15号相关物品上升到了10号,此时逆序对的数量为3+8=11个,因此损失等价于11.
- 对于一些强调最靠前的TopN个物品的排序指标(NDCG、ERR等)而言,上述优化不是理想的。例如,右图下一次迭代,在Ranknet中梯度优化方向如黑色箭头所示,此时损失可以下降到8;然而对于NDCG指标而言,我们更愿意看到红色箭头所示的优化方向(此时Ranknet同样是8,但是NDCG指标相比前一种情况上升了)。
这启发我们,能不能直接定义关于排序指标的梯度呢?
此时LambdaRank登场。LambdaRank是一个经验算法,它不是通过显示定义损失函数再求梯度的方式对排序问题进行求解,而是分析排序问题需要的分数$s$的梯度的物理含义,直接定义梯度,即Lambda梯度。只希望$L$对$s$的梯度可以按照理想NDCG指标的方向走。
首先看下RankNet的梯度:
$$
\frac{\partial L}{\partial w_k} =
\sum_{(i, j) \in P}\frac{\partial L_{ij}}{\partial w_k} =
\sum_{(i, j) \in P}
\frac{\partial L_{ij}}{\partial s_i}\frac{\partial s_i}{\partial w_k}
+
\frac{\partial L_{ij}}{\partial s_j}\frac{\partial s_j}{\partial w_k}
$$
不难证明:
$$
\frac{\partial L_{ij}}{\partial s_i} = \sigma \cdot \Biggl[\frac12(1 - S_{ij}) -\frac{1}{1 + \exp\bigl(\sigma \cdot (s_i - s_j)\bigr)}\Biggr] = -\frac{\partial L_{ij}}{\partial s_j}
$$
令,$\lambda_{ij}\mathrel{\stackrel{\mbox{def}}{=}} \frac{\partial L_{ij}}{\partial s_i} = -\frac{\partial L_{ij}}{\partial s_j}$.
则RankNet梯度写作:
考虑对于有序对 $(i,j)$,有 $S_{ij}=1$,于是有简化,
$$
\lambda_{ij}= \frac{-\sigma}{1 + \exp\bigl(\sigma \cdot (s_i - s_j)\bigr)}
$$
在此基础上,考虑评价指标$Z$(比如 NDCG,$\Delta |NDCG|$)的变化:
$$
\lambda_{ij}= \frac{-\sigma}{1 + \exp\bigl(\sigma \cdot (s_i - s_j)\bigr)}\cdot \lvert\Delta Z \rvert
$$
其中$\Delta Z$表示将物品$i$和$j$位置相互调换之后重新计算得到的评估指标的差值(此时其他的物品顺序是不变的)。
稍微有点变化的是,我们希望对于$S_{ij}=1$,$\lambda_{ij}$越大越好。因此,此时的目标是最大化某个效用函数$C$,有:$\lambda_{ij}= \frac{\partial C(s_i-s_j)}{\partial s_i}$。则,此时需要使用梯度上升!
$$
w_k \to w_k + \eta\frac{\partial C}{\partial w_k}
$$
至于$C$长什么样没有显示定义,但是可以证明$C=-L \cdot |\Delta Z|$。
即$C$反了一下(相对于$L$),正好梯度更新也反一下(变成加法)。(个人认为这里也是非常啰嗦的)
考虑偏序对的对称性,对于单个物品$i$,
$$
\lambda_{i} = \sum_{(i, j) \in P}\lambda_{ij} - \sum_{(j, i) \in P}\lambda_{ij}
$$
每个物品移动的方向和趋势取决于其他所有与之 label 不同的物品(比它靠前或比它靠后都考虑)。$i$比越多的物品$j$真实排名更优,则$\lambda_i$越大;反之,则越小。
由于引入了排序指标,Lambda梯度更关注位置靠前的物品的排序位置的提升。有效的避免了下调位置靠前的物品的情况发生。LambdaRank相比RankNet的优势在于分解因式后训练速度更快,同时考虑了排序指标,直接对问题求解,效果更明显。上述优化背后真正的损失函数的探索工作也有些文章在研究,参考CIKM18: The LambdaLoss Framework for Ranking Metric Optimization,也可参见下文Advanced Topics中Ranking Metric Optimization一节。
最后轮到LambdaMART登场。其中,MART又称作GBDT,是是一种 Boosting 思想下的算法框架。它通过加法模型,将每次迭代得到的子模型叠加起来;而每次迭代拟合的对象都是学习率与损失函数梯度的乘积。这两点保证了 MART 是一个正确而有效的算法。MART 中最重要的思想,就是每次拟合的对象是损失函数的梯度。值得注意的是,在这里,MART 并不对损失函数的形式做具体规定。实际上,损失函数几乎只需要满足可导这一条件就可以了。这一点非常重要,意味着我们可以把任何合理的可导函数安插在 MART 模型中。LambdaMART 就是用LambdaRank中提出的Lambda梯度代替了损失函数的梯度,将 Lambda和MART结合起来罢了。
LambdaMART有很多有点:
- 直接求解排序问题,而不是用分类或者回归的方法;
- 可以将 NDCG 之类的不可求导的排序指标转换为可导的损失函数,具有明确的物理意义;
- 可以在已有模型的基础上进行Continue Training;
- 每次迭代选取 gain 最大的特征进行梯度下降,因此可以学到不同特征的组合情况,并体现出特征的重要程度(特征选择);(MART的好处)
- 对正例和负例的数量比例不敏感。
AdaRank
AdaRank是Jun Xu(研一教我们网络数据挖掘的老师) etc.于2007年在SIGIR文章中SIGIR2007: AdaRank: A Boosting Algorithm for Information Retrieval提出的方法,目前引用量718。AdaRank利用Boosting来解决Listwise排序学习问题。思路来源于Adaboost算法,通过组合多个“弱”排序函数,得到“强”的排序函数,并且可以在“查询级别”考虑弱排序函数的构造和组合。
其损失函数推导如下:

$E$是排序评价指标函数,根据真实的排序标注$\boldsymbol{y}_i$(作为物品的相关性分数的参考),希望最大化模型$f$得到的排序结果$\pi(q_i,\boldsymbol{d_i},f)$。然后借助$e^{-x} \geq 1-x$不等式关系,转成指数损失函数。然后使用Adaboost中的加性模型$f$进行优化和学习,具体的优化过程和Adaboost几乎一样:根据误差不断调整样本的权重分布,不断更新加性模型。
更多排序学习模型参考维基百科列出的方法:Approach: Learning to Rank。
Advanced Topics
本节主要讨论排序学习的一些高级话题。
由于排序学习主要应用于大数据的场景,因此急需一个扩展性强的工具支持排序学习。到2018年12月之前,都不存在一个开源的工作能够大规模的进行排序学习,工业界一般都会自己搭建分布式系统来进行排序学习。幸运的是,Google于2018年12月初新开源了既支持开箱即用、又可扩展的TensorFlow库TF-Ranking,可用于排序学习。
TF-Ranking提供了一个统一的框架,包含了一系列state-of-arts排序学习算法,并提供了灵活的API,支持了多种特性,如:自定义pairwise 或 listwise 损失函数,评分函数,指标等;多物品联合评分;非平滑排序度量指标的直接优化;无偏的排序学习方法(下面会介绍到)。同时,TF-Ranking还能够利用Tensorflow提供的深度学习特性,如稀疏特征的embedding,大规模数据扩展性、泛化性等。
代码见:Github: TF-Ranking,论文见:TF-Ranking: Scalable TensorFlow Library for Learning-to-Rank,博客见:Blog: TF-Ranking。
Multi-Item Joint Scoring
多物品联合打分是最近刚刚提出的一种排序学习模型,见论文DAPA2019:Learning Groupwise Scoring Functions Using Deep Neural Networks。传统的排序学习模型单个物品独立的被打分(pairwise当中,物品也是单独被打分,再进行比较的),但实际应用过程中,也会关注跨物品之间的比较,每一个物品的相关性会取决于整个物品列表的分布。
在这篇文章中,作者提出了一个groupwise scoring functions(GSFs),该函数接收一组物品作为输入,通过考察该组物品的feature级别之间的联系,来同时进行打分,该函数输出每个物品相对于组内其他物品的相对得分,最后采用投票机制将该物品所在的不同组中其得分累加作为该物品的最终得分。
令输入物品的数量为n。思想很简单,就是把所有物品的特征concat在一起,通过MLPs输出不同物品的得分值,这个是全局的对比模型。但是作者做了一些改进,让模型输出和输入物品的顺序无关;捕捉物品之间的局部对比模式。对于第二个改进,只需要限制一次同时进行对比的物品的数量为m。对于第一个改进,作者从n个文档列表中取出所有m个物品之间的排列组合Permutations,将所有的排列组合得到的组中,物品出现过的组的得分加起来作为该物品的最终评得分,这样就和输入顺序无关。得到不同物品的最终得分后,最后定义真实标签和预测得分之间的损失时,作者还是使用了pairwise loss,不过该模型确实能同时输出n个不同输入物品的得分。由于排列组合的复杂度较高,作者在训练过程中做了一些技巧来降低复杂度,比如对n个物品先做shuffle,然后取shuffle后的子序列作为组,即,每个位置$i \sim i+m$之间的物品构成一组。同时,pairwise模型是该模型的特例,当n=2且m=1时就退化为pairwise模型。模型架构如下图所示:

Ranking Metric Optimization
前面我们提到,不管是pointwise还是pairwise都不能直接优化排序度量指标。在listwise中,我们通过定义Lambda梯度来优化排序度量指标,如LambdaRank和LambdaMART,然后Lambda梯度是一种经验性方法,缺乏理论指导。最近,有研究者提出了优化排序度量指标的概率模型框架,叫做LambdaLoss(CIKM18: The LambdaLoss Framework for Ranking Metric Optimization),提供了一种EM算法来优化Metric驱动的损失函数。文中提到LambdaRank中的Lambda梯度在LambdaLoss框架下,能够通过定义一种良好、特殊设定的损失函数求解,提供了一定的理论指导。
传统的pointwise或pairwise损失函数是平滑的凸函数,很容易进行优化。有些工作已经证明优化这些损失的结果是真正排序指标的界,即实际回归或分类误差是排序指标误差(取反)的上界(bound)。但是这个上界粒度比较粗,因为优化不是metric驱动的。
然而,直接优化排序指标的挑战在于,排序指标依赖于列表的排序结果,而列表的排序结果又依赖于每个物品的得分,导致排序指标曲线要么不是平坦的,要么不是连续的,即非平滑,也非凸。因此,梯度优化方法不实用,尽管有些非梯度优化方法可以用,但是时间复杂度高,难以规模化。为了规模化,目前有3种途径,1是近似法,缺点是非凸,容易陷入局部最优;2是将排序问题转成结构化预测问题,在该方法中排序列表当做最小单元来整体对待,损失定义为实际排序列表和最理想排序列表之间的距离,缺点是排序列表排列组合数量太大,复杂度高;3是使用排序指标在迭代过程中不断调整样本的权重分布(回顾下WRAP就是这种,LambdaRank也属于这种,$|\Delta NDCG|$就可以看做是权重。),这个方法优点是既考虑了排序指标,同时也是凸优化问题。
本文的动机之一就是探索LambdaRank中提出的Lambda梯度真正优化的损失函数是什么。文章通过提出LambdaLoss概率框架,来解释LambdaRank可以通过EM算法优化LambdaLoss得到。进一步,可以在LambdaLoss框架下,定义基于排序和得分条件下,metric-driven的损失函数。
假定给定文档集合下,不同文档的模型预测得分$\boldsymbol{s}=\Phi(\boldsymbol{x})$确定了一个关于所有可能排序排列组合的分布,即$p(\pi|\boldsymbol{s})$,其中$\pi$是其中一种排序列表结果。也就是说,模型$\Phi$可以得到多种排序结果,而每种排序结果下,文档真实标签$\boldsymbol{y}$的似然$p(\boldsymbol{y}|\boldsymbol{s},\pi)$是不同的(pairwise loss只和$\boldsymbol{s}$有关,而Lambda梯度不仅和$s$有关,还和位置(即排序)有关)。我们将$\pi$看做隐变量,则真实标签$\boldsymbol{y}$的似然关于该隐变量分布的期望如下:
$$
p(\boldsymbol{y}|\boldsymbol{s})=\sum_{\pi \in \Pi} p(\boldsymbol{y}|\boldsymbol{s},\pi)p(\pi|\boldsymbol{s})
$$
我们的目标是学习排序模型$\boldsymbol{s}=\Phi(\boldsymbol{x})$来最大化该期望$p(\boldsymbol{y}|\boldsymbol{s})$(可以类比EM算法中的$P(X|\Theta)$,我们这里的$\boldsymbol{y}$是EM中的$X$,因为我们要最大化的是文档的标签的似然值)。
则负对数似然为(考察了List-Level的损失):
$$
l(\boldsymbol{y},\boldsymbol{s})= -\log_2 P(\boldsymbol{y}|\boldsymbol{s})=-\log_2 \sum_{\pi \in \Pi} p(\boldsymbol{y}|\boldsymbol{s},\pi)p(\pi|\boldsymbol{s})
$$
这个式子有两个核心要素,1是排序分布$p(\pi|\boldsymbol{s})$,2是似然$P(\boldsymbol{y}|\boldsymbol{s},\pi)$。这两个核心要素取不同形式,会得到不同的损失函数。
1) 似然$P(\boldsymbol{y}|\boldsymbol{s},\pi)$不同形式:
Logistic: $p(y_i >y_j|s_i,s_j)=\frac{1}{1+e^{-\sigma \cdot (s_i-s_j)}}$,此时$\boldsymbol{y}$和$\pi$没关系,只和得分之间的相对关系有关。则$\forall \pi$,$P(\boldsymbol{y}|\boldsymbol{s},\pi)=P(\boldsymbol{y}|\boldsymbol{s})$,故负对数似然求和公式中可以把该似然提取出来,排序列表分布求和为1,则损失等价于Logistic Loss,$l(\boldsymbol{y},\boldsymbol{s})=-\log_2 p(\boldsymbol{y}|\boldsymbol{s})=\sum_{y_i>y_j} \log_2(1+e^{-\sigma \cdot (s_i-s_j)})$,注意$\sigma$是参数。
generalized logistic: $p(y_i >y_j|s_i,s_j, \pi_i, \pi_j)=\frac{1}{1+e^{-\sigma \cdot (s_i-s_j)}}^{|\Delta \text{NDCG}_{ij}|}$。这是带指数的广义Logistic分布。此处使用了$|\Delta \text{NDCG}_{ij}|$代表排序列表$\pi_i$和$\pi_j$(交换i和j)的NDCG值的差。下面会证明通过EM算法可以根据该式得到LambdaRank的损失函数。
借鉴上述的思想,可以得到如下1个文档级别的训练样本的损失函数:(我将其称为 ranking-sensitive pairwise loss),
$$
l(\boldsymbol{y},\boldsymbol{s})=-\sum_{y_i>y_j}\log_2 \sum_{\pi}p(y_i>y_j|s_i,s_j,\pi_i,\pi_j)p(\pi|\boldsymbol{s})
$$
2) 至于排序分布$p(\pi|\boldsymbol{s})$,作者举了上述LambdaLoss框架中,使用高斯分布作为排序分布时,等价于我们熟知的SoftRank方法,而使用Plackett-Luce作为排序分布时,等价于我们熟知的ListNet算法。
使用EM算法优化上述损失:
- E步:根据当前模型$\Phi^{(t)}$计算隐变量的分布$p^{(t)}(\pi|\boldsymbol{s})$.
- M步:固定$p^{(t)}(\pi|\boldsymbol{s})$,重新在complete数据集上最小化负对数似然,并优化模型参数。其中,完整数据集为:$C=\{(\boldsymbol{y},\boldsymbol{x},\pi)|\pi \sim p^{(t)}(\pi|\boldsymbol{s}) \}$。目标是优化如下损失:$\Phi^{(t+1)}=argmin \mathcal {L}_C(\Phi)=arg min\frac{1}{|T|} \sum_{(\boldsymbol{y},\boldsymbol{x}) \in T} l_C(\boldsymbol{y},\Phi(\boldsymbol{x}))$。
C是抽样得到的所有的训练样本(每个训练样本都是文档列表级别的,由$(\boldsymbol{y},\boldsymbol{x},\pi)$构成,也可以理解为E步会对每个原始文档集合$\boldsymbol{x}$排序($\pi$),得到的所有文档集合排序结果构成M步的训练样本),M步在C上求期望损失。
其中,
$$
l_C(\boldsymbol{y},\boldsymbol{s})=-\sum_{\pi}p^{(t)}(\pi|\boldsymbol{s}) \log_2 p(\boldsymbol{y}|\boldsymbol{s},\pi) \approx -\frac{1}{K} \sum_{k=1}^K \log_2 P(\boldsymbol{y}|\boldsymbol{s},\pi^{k})
$$
其中,$\pi^{k}$是根据分布$p^{(t)}(\pi|\boldsymbol{s})$采样得到的。
更特殊的,直接使用hard assignment distribution来表示$p^{(t)}(\pi|\boldsymbol{s})$。
$$
H(\hat{\pi}|\boldsymbol{s})=1 \text{and} H(\pi|\boldsymbol{s})=1 \forall \pi \neq\hat{\pi}
$$
其中,$\hat{\pi}$是按照得分$\boldsymbol{s}$降序排序得到的列表。(此时EM算法和K-means中的优化方法一样,可以将K-means中E步将样本归入到某个类别簇 类比为 此处对文档列表排一个序,每种序对应一个类别,类别是隐向量;将文档按照得分降序得到唯一的序类别于K-means中将某个样本硬性(hard)的归入到一个具体的类。)
此时,可以通过推导下述负对数似然损失函数得到LambdaRank的损失函数:
$$
l(\boldsymbol{y},\boldsymbol{s})=-\sum_{y_i>y_j}\log_2 \sum_{\pi}p(y_i>y_j|s_i,s_j,\pi_i,\pi_j)H(\pi|\boldsymbol{s})
$$
E步:根据当前模型计算所有文档的得分,然后按照得分降序排序,得到排序结果$\hat{\pi}$。
M步:所有Complete的文档列表的损失简化为:
$$
\begin{aligned}
l_C(\boldsymbol{y},\boldsymbol{s})&=
-\sum_{\pi}p^{(t)}(\pi|\boldsymbol{s}) \log_2 p(\boldsymbol{y}|\boldsymbol{s},\pi) \\
&= -\sum_{\pi} H(\pi|\boldsymbol{s})\log_2 p(\boldsymbol{y}|\boldsymbol{s},\pi) \\
&= -\log_2 p(\boldsymbol{y}|\boldsymbol{s}, \hat{\pi})
\end{aligned}
$$
进一步,代入generalized logistic可得到:
$$
\begin{aligned}
l_C(\boldsymbol{y},\boldsymbol{s}) &= -\log_2 p(\boldsymbol{y}|\boldsymbol{s}, \hat{\pi}) \\
&= -\sum_{y_i>y_j} \log_2 p(y_i>y_j|s_i,s_j,\hat{\pi}_i,\hat{\pi}_j) \\
&=\sum_{y_i>y_j}|\Delta \text{NDCG}_{ij}| \log_2(1+e^{-\sigma \cdot (s_i-s_j)})
\end{aligned}
$$
因此,上式是LambdaRank潜在的损失函数。
作者进一步给出了定义Metric-driven Loss的方法:
LamdaLoss中一个最具吸引力的特性是,似然部分$p(\boldsymbol{y}|\boldsymbol{s}, \pi)$既考虑了得分,又考虑了排序。这提供了一个沟通依赖于得分的传统损失函数(e.g., pairwise loss)和依赖于排序的排序度量指标(e.g., NDCG)的桥梁。
作者给出一些常用的排序度量指标的metric-driven Loss。主要利用0-1Loss的上界为Logistic Loss这一性质。即:
$$
\mathcal I_{s_i<s_j} \leq \log_2(1+e^{-\sigma \cdot(s_i-s_j)})
$$
作者推导了Average Relevance Position($ARP=\sum_{i=1}^n y_i \cdot i$),ARP是cost-based function,越小越好。
$$
\begin{aligned}
\text{ARP}&=\sum_{i=1}^n y_i (\sum_{j=1}^n \mathcal{I}_{s_i < s_j} +1) \\
&=\sum_{i=1}^n\sum_{j=1}^n y_i \mathcal{I}_{s_i < s_j} + C_1\\
&\leq \sum_{i=1}^n\sum_j^n y_i \log_2(1+e^{-\sigma \cdot(s_i-s_j)}) + C_1
\end{aligned}
$$
此时在LambdaLoss框架下的,相应的损失函数为,$\text{APR-LOSS1}$:
$$
l(\boldsymbol{y},\boldsymbol{s})=-\sum_{i=1}^n\sum_{j=1}^n \log_2 \sum_{\pi}(\frac{1}{1+e^{-\sigma \cdot (s_i-s_j)}})^{y_i} H(\pi|\boldsymbol{s})
$$
上述推导有2个技巧:1) 把ranking中的position $i$写成关于$\mathcal I_{s_i<s_j}$的形式,这样可以利用0-1损失上界为Logistic损失这一性质。2) 把Metric转成Metric-driven loss过程中,先整理成generalized logistic形式,这个就是排序分布$p(\pi|\boldsymbol{s})$,再利用EM算法中概率排序分布取hard assignment distribution,将generalized logistic进一步改写成$\sum_{\pi} p(\pi|\boldsymbol{s}) H(\pi|\boldsymbol{s})$;再取负对数得到损失。另外文中还给出了ARP的另一种损失。
作者还推导了NDCG的LambdaLoss,由于NDCG是gain-based function,故先转成Loss:
$$
\text{NDCG}_{\text{cost}}=\sum_{i=1}^n G_i - \sum_{i=1}^n \frac{G_i}{D_i} =\sum_{i=1}^n \frac{G_i}{D_i}(D_i-1)=\sum_{i=1}^n G_i(1-\frac{1}{D_i})
$$
其中,$G_i=\frac{2^{y_i}-1}{max_\text{DCG}}$,对于给定的文档列表,$G_i$是个常数 (和排序无关,$G_i$公式中分子只和标签$y_i$有关, 分母是最优的DCG值,是个常数。所以可以直接加到损失函数中);第二项其实就是NDCG($D_i=log_2(1+i)$, $\text{NDCG}=\sum_{i=1}^n \frac{G_i}{D_i}$),这么定义是因为下文推导方便。
因为:$D_i − 1 = \log_2 (1 + i) − 1 ≤ i − 1$,有:
$$
\begin{aligned}
\text{NDCG}_{\text{cost}} &=\sum_{i=1}^n \frac{G_i}{D_i}(D_i-1)\\
& \leq \sum_{i=1}^n \frac{G_i}{D_i}(i-1) \\
& \leq \sum_{i=1}^n \frac{G_i}{D_i}\sum_{j=1}^n\mathcal{I}_{s_i < s_j} \\
& \leq \sum_{i=1}^n \frac{G_i}{D_i} \log_2(1+e^{-\sigma \cdot (s_i-s_j)})
\end{aligned}
$$
同理可得,LmabdaLoss损失为:
$$
l(\boldsymbol{y},\boldsymbol{s})=-\sum_{i=1}^n\sum_{j=1}^n \log_2 \sum_{\pi}(\frac{1}{1+e^{-\sigma \cdot (s_i-s_j)}})^{\frac{G_i}{D_i}} H(\pi|\boldsymbol{s})
$$
上述问题是$i$太大时,上界太松了。因此,作者又提出了另一种损失,利用了性质(这个性质有待证明)$1-\frac{1}{D_i}=\sum_{j=1}^{i-1}|\frac{1}{D_{|i-j|}}-\frac{1}{D_{|i-j|}+1}|=\sum_{j=1}^{i-1} \delta_{ij}$。最后可以推导出NDCG第二种形式的损失(关键):
$$
l(\boldsymbol{y},\boldsymbol{s})=-\sum_{y_i>y_j} \log_2 \sum_{\pi}(\frac{1}{1+e^{-\sigma \cdot (s_i-s_j)}})^{\delta_{ij}|G_i-G_j|} H(\pi|\boldsymbol{s})
$$
上式的好处在于,可以通过重新定义$G_i$和$D_i$来扩展出很多NDCG-like metrics的LambdaLoss。也可以用来优化binary情况下的,MRR-like metrics。
作者还推导出上述得到的LambdaRank Loss优化结果实际上是优化如下metric的上界,
$$
\text{Metric}_{\text{LambdaRank}}=\sum_{i=1}^n G_i \sum_{j=1}^{i-1}|\frac{1}{D_i}-\frac{1}{D_j}|
$$
可以证明,使用LambdaLoss优化该metric得到的$\text{NDCG}_{\text{cost}} \leq \text{Metric}_{\text{LambdaRank}}$,因此LambaLoss结果更好。
另外,上述讨论都基于hard assignment $\hat{\pi}$。作者也考虑了soft assignment,并作为下一步工作。
Unbiased Learning-to-Rank
先前的研究表明,受到排版的影响,给定排序的项目列表,无论其相关性如何,用户更有可能与前几个结果进行交互,这实际上是一种位置偏差(Position Bias),即,被交互和用户真正喜欢存在差距,因为靠前,人们更倾向于交互,而很多靠后未点击的物品,用户可能更感兴趣,倘若将这些靠后的物品挪到前面去,那用户交互的概率可能会更高。 这一观察激发了研究人员对无偏见的排序学习(Unbiased Learning-to-Rank)的兴趣。常见的解决途径包括,对训练实例重新赋权来缓解偏差;构造无偏差损失函数进行无偏排序学习;评估时使用无偏度量指标等。
这里介绍两篇近期研究无偏排序学习的论文:
在WSDM17的文章中,作者提到目前解决位置偏差的方法主要包括,考察相对偏差(点击和未点击之间的偏好差异),但是问题是也只能针对已经展示的物品列表构建偏序对,仍然存在偏差;显示建模概率点击模型(把位置和上下文偏差考虑了,例如使用latent变量),但问题是为了估计模型参数,同样的查询需要进行很多次(数据充足)才行准确估计,和实际情况不相符,不够使用;在实际展示过程中,引入随机探索机制(exploration),例如使用bandit feedback,这样可以解决偏差问题,但是这可能降低模型的推荐质量。
在本文中,作者提出了一个有理论指导,又有经验保障的方法,从观测的隐式反馈中进行排序学习,可以克服上述限制。本文借鉴了因果推理中反事实估计技术(可参考这个回答IPS:inverse propensity scoring),开发了一种可被证实的、无偏的估计器,可以从有偏差的反馈数据中进行学习并评估排序性能。基于该估计器,作者提出了一种针对LTR的倾向加权经验风险最小化(Propensity-Weighted Empirical Risk Minimization,ERM)方法,作者将该方法应用到一种新的排序学习算法中,称为Propensity SVM-Rank。
作者首先在文章中提出了基于Inverse Propensity Scoring(IPS)的Partial-Info Learning-to-Rank。这部分内容其实并没有太多的新意,不过是把从Multi-armed Bandit领域用IPS来做Unbiased Offline Evaluation的思路借鉴过来。不过文章指出了一个核心问题,那就是如何来估计这些Propensity Probability,也就是当前系统(推荐系统、搜索引擎)选择各个文档的概率。传统上,特别是以前的Unbiased Offline Evaluation基于随机产生文档顺序,因此这些Propensity Probability都是Uniform分布的。但这样的设计在现实中是不可能的,因为Uniform分布的文档,用户体验会变得很差。这篇文章采取了这样一个思路,文章假设现在系统的“偏差”可以通过一个Position-based Click Model with Click Noise(PCMCN)来解释。简单说来PCMCN就是来对用户查看一个排序文档进行建模,从而达到Propensity Probability能够被方便预测,这么一个目的。为了能够PCMCN,作者们还提出了一个基于交换两个位置文档的实验方法,用于收集数据。值得肯定的是,仅仅交换两个位置文档的方法,相比于以前的Uniform的方法,要更加注重用户体验。文章的实验部分展示了在人工数据以及真实系统中的表现。总体说来,能够对“有偏差”的用户数据建模,比直接利用这些数据,训练的模型效果要来的好得多。
WSDM2018这篇文章指出传统解决位置偏差的方法都是在查询结果上添加随机扰动因素,然后展示给用户,根据收集到的用户反馈估计学习点击偏差模型,这样的问题是用户体验较差。作者在文中提出了一种不需要依赖这种随机化,只从常规的反馈数据中学习点击偏差模型的方法,该方法是基于回归的EM算法(regression-based Expectation-Maximization (EM) algorithm)。
简单来说,先使用伯努利变量$O$来表示一个相关的文档是否被观测到(通俗点就是,能不能判断一个文档和查询是不是相关的;能确定相关或者不相关,那么就代表被观测到了;不能确定就代表没观测到),$O$受到很多因素影响,如位置,整个文档列表等,使用$P(O_i=1)$表示被观测的倾向性(Propensity)。然后作者利用我们在上文提到的IPS或IPW(Inverse Propensity Weighting)对不同文档赋权重$w_i=\frac{1}{P(O_i=1)}$,即越不容易被展示,其权重越大(这是因果推理中的思想,即一个事件发生概率很低,结果却发生了,那这个事件的信息量是很大的)。这样可以对ARP(上一小节提到的)损失进行加权:
$$
\begin{aligned}
\sum_{i \in \pi:o_i=1,r_i=1} w_i \cdot i &= \sum_{i \in \pi:o_i=1,r_i=1} w_i \cdot (\sum_{j \in \pi} \mathcal{I}_{s_j>s_i}+1) \\
&=\sum_{i \in \pi:o_i=1,r_i=1} \sum_{j\in \pi} w_i \cdot \mathcal{I}_{s_j>s_i} + const
\end{aligned}
$$
其中,$w_i$就是IPW。Logistic Loss或Hinge Loss是上述损失的上界,因此可以采用通常的pairwise损失来学习。这里的关键转成了估计倾向性(Propensity)$P(O_i=1)$。
作者在常规的隐式反馈数据集上($(c,q,d,k)$,$c$代表点击与否,$q$是查询,$d$是文档,$k$是位置),构建一个概率点击模型,
$$
P(C = 1|q,d,k) = P(E = 1|k) · P(R = 1|q,d)
$$
即给定查询、文档、位置条件下(某查询$q$返回的结果中排在某位置$k$的文档$d$),点击的概率受到两方面影响,对于某个位置$k$用户examine的概率$\theta_k=P(E=1|k)$以及该文档和查询相关的概率$\gamma_{q,d}=P(R=1|q,d)$。
并且可以证明,Propensity中的观测变量$O$和点击模型中Examine变量$E$是等价的(当用户examine了某个文档($E=1$),那么文档相关性与否完全可以根据用户是否点击来推测,点了说明相关,没点说明不相关,则$O=1$;$E=0$时,这个文档可能相关也可能不相关,则$O=0$)。
因此,思路就是可以利用实际的点击数据,最大化点击数据的似然,并且把相关性变量$R$、Examine变量$E$都看做是隐变量,使用EM算法求解,E步固定模型,估计隐变量后验分布$P(E,R|C,q,d,k)$;M步固定隐变量后验分布,最大化对数似然($\log P(\mathcal{L}) = c \log \theta_k \gamma_{q,d} + (1 − c) \log(1 − \theta_{k} \gamma_{q,d}), \mathcal{L}=\{(c,q,d,k)\}$)。
另外,作者提出了对标准的EM算法的改进,把文档和查询的特征融入到模型中,使用一个回归模型来估计文档和查询之间的相关性$\gamma_{q,d}=f(\boldsymbol{x}_{q,d})$。$f$可以使用任意回归模型(当相关性是多值时),也可以使用GBDT。如果是二值的,也可以使用任意的判别式模型,如逻辑回归。
通过上述方法,既可以学习$\theta_k=P(E=1|k)=P(O=1)$,还可以学习出相关性函数$f(\boldsymbol{x})$。这个过程是单独进行的。
接着,再使用估计到的Propensity$P(O_i=1)$代入到ARP损失(或其他NDCG-like、MRR-like),使用hinge pairwise loss或logistic pairwise loss进行学习。
上述两个过程是分离开的。个人认为第二个过程可以使用LambdaLoss中的方法进行改进,将LambdaLoss改进成Unbias Ranking Metric Optimization。
Summary
本文对实践中表现较好的排序学习模型进行了调研,包括Pointwise Ranker,Pairwise Ranker以及Listwise Ranker。最后,还讨论了关于排序学习的一些高级话题,例如排序学习的规模化工具、多物品联合打分、排序度量指标优化方法、无偏排序学习等。
未来的工作可以考虑实现其中的一些模型,并应用于实际项目中。针对项目的实际场景,可以进一步考虑对已有模型进行改进,例如可以对排序学习中的一些高级话题进行探索,并期望将解决方案融入到已有模型中,使得最终的排序学习模型产生的结果在实践中表现更好,能够既注重用户体验、又能够关注到不同物品之间的公平性、结果更加多样性等等。
Reference
WWW2008: Slides: Learning to Rank for Information Retrieval
SIGIR2016: Slides: Online Learning to Rank for Information Retrieval
基于排序学习的推荐算法研究综述
JMLR2011: FTRL: Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization
ADKDD14: Practical Lessons from Predicting Clicks on Ads at Facebook
ICDM2010: Factorization Machine
爱奇艺个性化推荐排序实践
RecSys2016: Deep Neural Networks for YouTube Recommendations
关于’Deep Neural Networks for YouTube Recommendations’的一些思考和实现
RecSys2016: Wide & Deep Learning for Recommender Systems
IJCAI2017: DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
ADKDD2017:Deep & Cross Network for Ad Click Predictions
SIGKDD2012: Optimizing Search Engines using Clickthrough Data
UAI2009: BPR: Bayesian Personalized Ranking from Implicit Feedback
IJCAI2011: WSABIE: Scaling Up To Large Vocabulary Image Annotation
ICLR2016: Session-based Recommendations with Recurrent Neural Networks
WWW2017: Collaborative Metric Learning
WWW2018: Latent Relational Metric Learning via Memory-based Attention for Collaborative Ranking
SIGIR2018: Adversarial Personalized Ranking for Recommendation
WSDM2018: Neural Personalized Ranking for Image Recommendation
ICML2005: RankNet: Learning to Rank using Gradient Descent
NIPS2006: LambdaRank: Learning to Rank with Non-Smooth Cost Functions
Inf Retrieval2010: LambdaMART: Adapting Boosting for Information Retrieval Measures
MSR-TR2010: From RankNet to LambdaRank toLambdaMART: An Overview
SIGIR2007: AdaRank: A Boosting Algorithm for Information Retrieval
TF-Ranking: Scalable TensorFlow Library for Learning-to-Rank
DAPA2019:Learning Groupwise Scoring Functions Using Deep Neural Networks
CIKM2018: The LambdaLoss Framework for Ranking Metric Optimization
WSDM2008:SoftRank: Optimizing Non-Smooth Rank Metrics
ICML2007:ListNet:Learning to Rank: From Pairwise Approach to Listwise Approach
WSDM2017: Unbiased Learning-to-Rank with Biased Feedback
WSDM2018: Position Bias Estimation for Unbiased Learning to Rank in Personal Search
最后,欢迎大家关注我的微信公众号,蘑菇先生学习记。会定期推送关于算法的前沿进展和学习实践感悟。

]]>