概述
本文是搭建hadoop分布式集群的一个详细说明,旨在通过本文,快速入手hadoop
部署方案
hadoop部署方案包括:单机模式、伪分布模式、完全分布模式
本文将使用完全分布模式进行集群搭建
准备工作
- 64位centos7服务器3台
- master:172.16.21.121
- node1:172.16.21.129
- node2:172.16.21.130
- hadoop-2.7.3.tar.gz
- jdk-8u73-linux-x64.tar.gz
- 关闭防火墙
service firewalld stop或systemctl stop firewalld.service 关闭selinux
1
setenforce 0临时关闭,sestatus查看状态:current mode变成permissive
纠正系统时间
设置时区
1
2timedatectl查看时区
timedatactl set-timezone Asia/Shanghai安装ntp并启动
1
2
3yum -y install ntp
systemctl enable ntpd
start ntpd
安装jdk
1
2
3
4
5
6
7
8
9
10解压tar -zxvf jdk-8u73-linux-x64.tar.gz到/usr/local/java
vim /etc/profile
添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_73
export JRE_HOME=/$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source /etc/profile配置生效
java -version查看配置主机域名
配置hostname
1
2
3
4
5
6
7
8
9
10
11172.16.21.121(master)主机上:
先输入命令:hostname master,临时修改主机名
编辑 vim /etc/hostname 输入master,永久修改主机名
172.16.21.129(node1)节点1上:
输入 hostname node1
编辑 vim /etc/hostname 输入node1
172.16.21.130(node2)节点2上:
输入hostname node2
编辑vim /etc/hostname 输入node2配置host(3台服务器同时输入) 增加ip到name的映射,在/etc/hosts文件中。
编辑该文件,输入如下三句:1
2
3172.16.21.121 master
172.16.21.129 node1
172.16.21.130 node2
ssh免密码登录
master上操作:
1
2ssh-keygen -t rsa 一直回车,信息中会看到.ssh/id_rsa.pub的路径
复制:cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keysnode1和node2上操作:
1
创建node1和node2上root/.ssh目录:mkdir /root/.ssh
master上操作:
1
2
3复制authorized_keys到node1和node2节点:
scp /root/.ssh/authorized_keys root@172.16.21.129:/root/.ssh/
scp /root/.ssh/authorized_keys root@172.16.21.130:/root/.ssh/master,node1,node2都操作:
1
chmod 700 /root/.ssh
master上验证:
1
2
3ssh master
ssh node1
ssh node2
配置Hadoop集群
- 解压 tar -zxvf hadoop-2.7.3.tar.gz, 到/usr/local/hadoop
配置环境变量:
1
2
3
4
5
6vim /etc/profile
添加:
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效:source /etc/profile
查看版本: hadoop version修改hadoop配置添加JAVA_HOME
1
2
3vim /usr/local/hadoop/hadoop-2.7.3/etc/hadoop hadoop-env.sh
vim /usr/local/hadoop/hadoop-2.7.3/etc/hadoop yarn-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_73创建目录
1
2
3mkdir -p /usr/local/hadoop/hdfs/data
mkdir -p /usr/local/hadoop/hdfs/name
mkdir -p /usr/local/tmp配置core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
</configuration>
- 配置hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
复制mapred-site.xml.template为mapred-site.xml,并修改
cp mapred-site.xml.template mapred-site.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>master:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://master:9001</value>
</property>
</configuration>修改yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>将以上步骤操作在node1和node2上重复
可将修改的文件拷贝至node1和node2节点修改master上的slaves文件
$HADOOP_HOME/etc/hadoop/slaves
删除localhost
添加:1
2node1
node2启动
只在master上操作
1
2
3
4
5
6master上格式化:
cd $HADOOP_HOME/bin/
./hadoop namenode -format
master上启动:
cd $HADOOP_HOME/sbin/
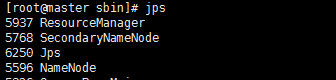
./start-all.sh查看jps:
jps
master: ResourceManager SecondaryNameNode NameNode
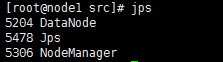
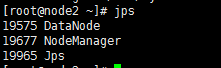
node1/node2: DataNode NodeManager
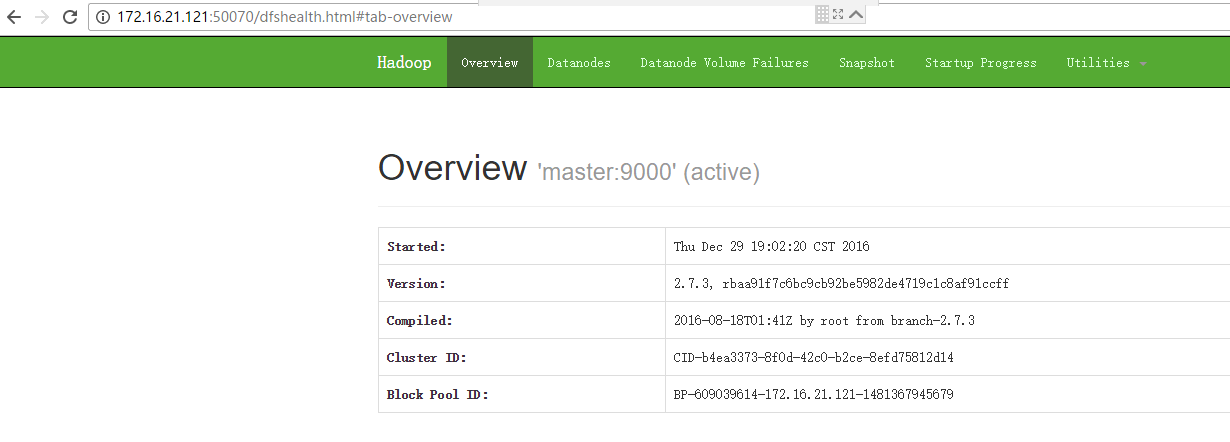
访问master的50070:
http://172.16.21.121:50070
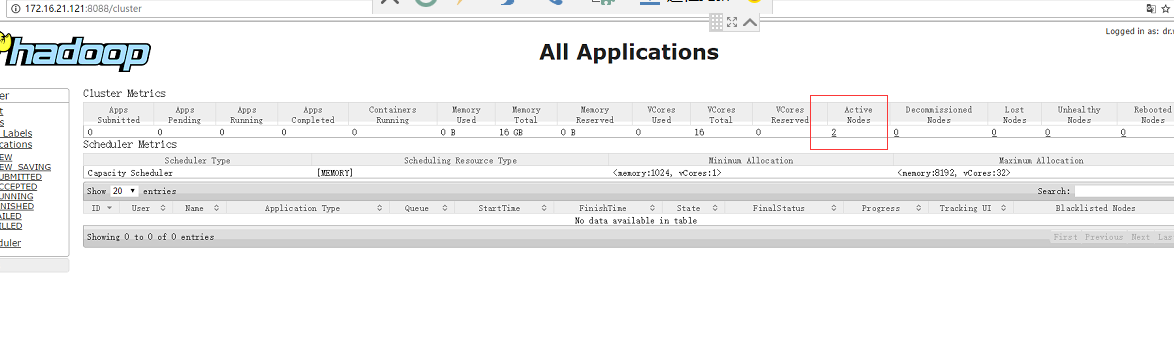
- 访问master的8088:
http://172.16.21.121:8088
参考
http://www.voidcn.com/blog/dream_broken/article/p-6319288.html

