自然语言处理NLP
情感分析作为自然语言处理的一个部分,让我们首先看一下自然语言处理。
相关技术及运用
自动问答(Question Answering,QA):它是一套可以理解复杂问题,并以充分的准确度、可信度和速度给出答案的计算系统,以IBM‘s Waston为代表;
信息抽取(Information Extraction,IE):其目的是将非结构化或半结构化的自然语言描述文本转化结构化的数据,如自动根据邮件内容生成Calendar;
情感分析(Sentiment Analysis,SA):又称倾向性分析和意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,如从大量网页文本中分析用户对“数码相机”的“变焦、价格、大小、重量、闪光、易用性”等属性的情感倾向;
机器翻译(Machine Translation,MT):将文本从一种语言转成另一种语言,如中英机器翻译。
发展现状
基本解决:词性标注、命名实体识别、Spam识别
取得长足进展:情感分析、共指消解、词义消歧、句法分析、机器翻译、信息抽取
挑战:自动问答、复述、文摘、会话机器人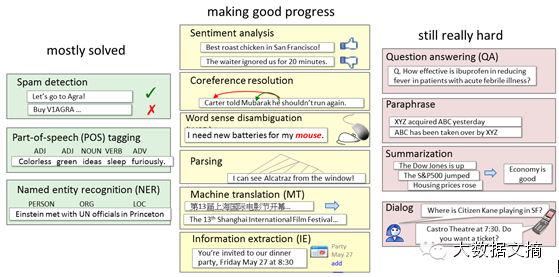
NLP主要难点——歧义问题
- 词法分析歧义:
1)分词, 如“严守一把手机关了”,可能的分词结果“严守一/ 把/ 手机/ 关/ 了” 和“严守/ 一把手/ 机关/ 了”。2)词性标注, 如“计划”在不同上下文中有不同的词性:“我/ 计划/v 考/ 研/”和“我/ 完成/ 了/ 计划/n” - 语法分析歧义:
“那只狼咬死了猎人的狗”。 ”咬死了猎人的狗失踪了”。 - 语义分析歧义:
计算机会像你的母亲那样很好的理解你(的语言): 1)计算机理解你喜欢你的母亲。2)计算机会像很好的理解你的母亲那样理解你 - NLP应用中的歧义:
音字转换:拼音串“ji qi fan yi ji qi ying yong ji qi le ren men ji qi nong hou de xing qu”中的“ji qi”如何转换成正确的词条为什么自然语言理解如此困难?
- 用户生成内容中存在大量口语化、成语、方言等非标准的语言描述
- 分词问题
- 新词不断产生
- 基本常识与上下文知识
- 各式各样的实体词
为了解决以上难题,我们需要掌握较多的语言学知识,构建知识库资源,并找到一种融合各种知识、资源的方法,目前使用较多是概率模型 (probabilistic model)或称为统计模型(statistical model),或者称为“经验主义模型”,其建模过程基于大规模真实语料库,从中各级语言单位上的统计信息,并且,依据较低级语言单位上的统计信息,运行 相关的统计、推理等技术计算较高级语言单位上的统计信息。与其相对的“理想主义模型”,即基于Chomsky形式语言的确定性语言模型,它建立在人脑中先 天存在语法规则这一假设基础上,认为语言是人脑语言能力推导出来的,建立语言模型就是通过建立人工编辑的语言规则集来模拟这种先天的语言能力。
情感分析概念
情感分析(Sentiment analysis),又称倾向性分析,意见抽取(Opinion extraction),意见挖掘(Opinion mining),情感挖掘(Sentiment mining),主观分析(Subjectivity analysis),它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,如从评论文本中分析用户对“数码相机”的“变焦、价格、大小、重 量、闪光、易用性”等属性的情感倾向。
示例
从电影评论中识别用户对电影的褒贬评价

Google Product Search识别用户对产品各种属性的评价,并从评论中选择代表性评论展示给用户
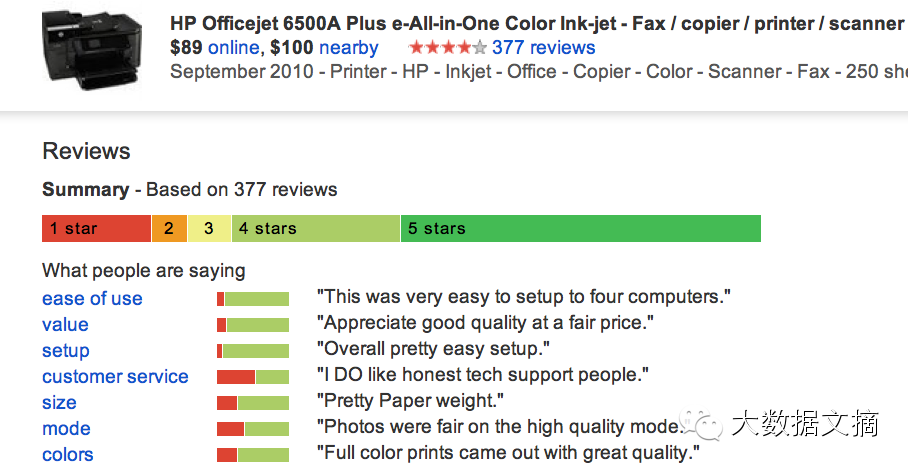
微信新闻识别用户对新闻的各种评价,并从评论中选择代表性评论展示给用户
Twitter sentiment versus Gallup Poll of Consumer Confidence:挖掘Twitter中的用户情感发现,其与传统的调查、投票等方法结果有高度的一致性。
下图中2008年到2009年初,网民情绪低谷是金融危机导致,从2009年5月份开始慢慢恢复。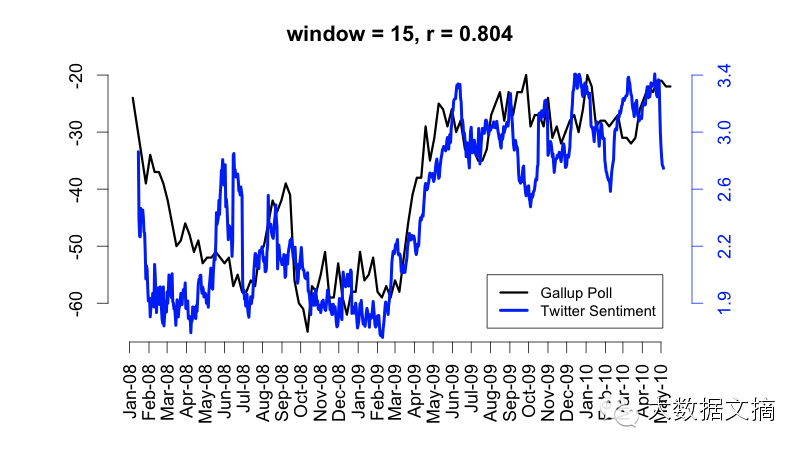
Twitter sentiment: 通过Twitter用户情感预测股票走势。
2012年5月,世界首家基于社交媒体的对冲基金 Derwent Capital Markets 在屡次跳票后终于上线。它会即时关注Twitter 中的公众情绪指导投资。正如基金创始人保罗•郝汀(Paul Hawtin)表示:“长期以来,投资者已经广泛地认可金融市场由恐惧和贪婪驱使,但我们从未拥有一种技术或数据来量化人们的情感。”一直为金融市场非理性举动所困惑的投资者,终于有了一扇可以了解心灵世界的窗户——那便是 Twitter 每天浩如烟海的推文,在一份八月份的报道中显示,利用 Twitter 的对冲基金 Derwent Capital Markets 在首月的交易中已经盈利,它以1.85%的收益率,让平均数只有0.76%的其他对冲基金相形见绌。类似的工作还有预测电影票房、选举结果等,均是将公众 情绪与社会事件对比,发现一致性,并用于预测,如将“冷静CLAM”情绪指数后移3天后和道琼斯工业平均指数DIJA惊人一致。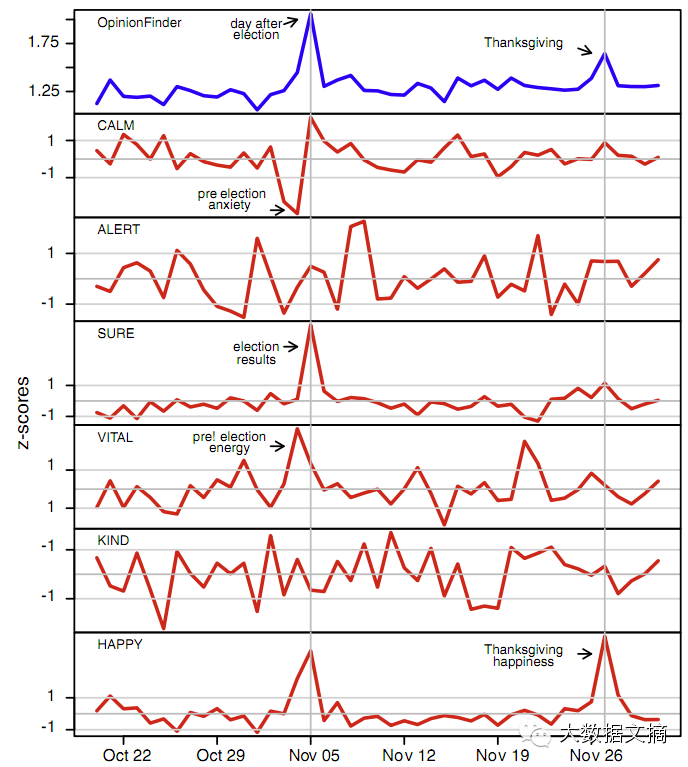
Target Sentiment on Twitter(Twitter Sentiment App):对Twitter中包含给定query的tweets进行情感分类。对于公司了解用户对公司、产品的喜好,用于指导改善产品和服务,公司还可以 据此发现竞争对手的优劣势,用户也可以根据网友甚至亲友评价决定是否购买特定产品。详细见论文:Alec Go, Richa Bhayani, Lei Huang. 2009. Twitter Sentiment Classification using Distant Supervision.
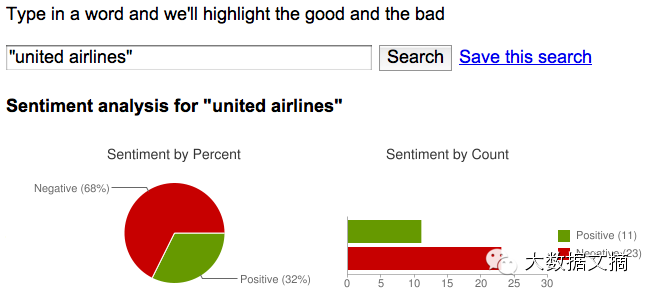
情感分析内容
任务
情感分析主要目的就是识别用户对事物或人的看法、态度。
参与主体主要包括:
- Holder (source) of attitude:观点持有者
- Target (aspect) of attitude:评价对象
- Type of attitude:评价观点
- From a set of types:观点类型:Like, love, hate, value, desire, etc.
Or (more commonly) simple weighted polarity: positive, negative, neutral,together with strength - Text containing the attitude:评价文本,一般是句子或整篇文档。
- 更细更深入的还包括评价属性,情感词/极性词,评价搭配等。
通常,我们面临的情感分析任务包括如下几类:
- 是正面还是反面情绪?
Simplest task: Is the attitude of this text positive or negative? - 排序态度:
More complex: Rank the attitude of this text from 1 to 5 - 检测目的、观点等:
Advanced: Detect the target, source, or complex attitude types
词典匹配VS机器学习
不是有词典匹配的方法了吗?怎么还搞多个机器学习方法。因为词典方法和机器学习方法各有千秋。
机器学习的方法精确度更高,因为词典匹配会由于语义表达的丰富性而出现很大误差,而机器学习方法不会。而且它可使用的场景更多样。无论是主客观分类还是正负面情感分类,机器学习都可以完成任务。而无需像词典匹配那样要深入到词语、句子、语法这些层面。
而词典方法适用的语料范围更广,无论是手机、电脑这些商品,还是书评、影评这些语料,都可以适用。但机器学习则极度依赖语料,把手机语料训练出来的的分类器拿去给书评分类,那是注定要失败的。
使用机器学习进行情感分析,可以换一个相同意思的说法,就是用有监督的(需要人工标注类别)机器学习方法来对文本进行分类。
这点与词典匹配有着本质的区别。词典匹配是直接计算文本中的情感词,得出它们的情感倾向分值。而机器学习方法的思路是先选出一部分表达积极情感的文本和一部分表达消极情感的文本,用机器学习方法进行训练,获得一个情感分类器。再通过这个情感分类器对所有文本进行积极和消极的二分分类。最终的分类可以为文本给出0或1这样的类别,也可以给出一个概率值,比如”这个文本的积极概率是90%,消极概率是10%“。
NLTK
Python 有良好的程序包可以进行情感分类,那就是Python 自然语言处理包,Natural Language Toolkit ,简称NLTK 。NLTK 当然不只是处理情感分析,NLTK 有着整套自然语言处理的工具,从分词到实体识别,从情感分类到句法分析,完整而丰富,功能强大。实乃居家旅行,越货杀人之必备良药。
另外,NLTK 新增的scikit-learn 的接口,使得它的分类功能更为强大好用了,可以用很多高端冷艳的分类算法了。
有了scikit-learn 的接口,NLTK 做分类变得比之前更简单快捷,但是相关的结合NLTK 和 sciki-learn 的文章实在少。
构建情感分析工具流程
人工标注
有监督意味着需要人工标注,需要人为的给文本一个类标签。比如我有5000条商品评论,如果我要把这些评论分成积极和消极两类。那我就可以先从里面选2000条评论,然后对这2000条数据进行人工标注,把这2000条评论标为“积极”或“消极”。这“积极”和“消极”就是类标签。 假设有1000条评论被标为“积极”,有1000条评论被标为“消极”。(两者数量相同对训练分类器是有用的,如果实际中数量不相同,应该减少和增加数据以使得它们数量相同)
特征选择
特征就是分类对象所展现的部分特点,是实现分类的依据。我们经常会做出分类的行为,那我们依据些什么进行分类呢? 举个例子,如果我看到一个年轻人,穿着新的正装,提着崭新的公文包,快步行走,那我就会觉得他是一个刚入职的职场新人。在这里面,“崭新”,“正装”,“公文包”,“快步行走”都是这个人所展现出的特点,也是我用来判断这个人属于哪一类的依据。这些特点和依据就是特征。可能有些特征对我判断更有用,有些对我判断没什么用,有些可能会让我判断错误,但这些都是我分类的依据。
我们没办法发现一个人的所有特点,所以我们没办法客观的选择所有特点,我们只能主观的选择一部分特点来作为我分类的依据。这也是特征选择的特点,需要人为的进行一定选择。
而在情感分类中,一般从“词”这个层次来选择特征。
比如这句话“手机非常好用!”,我给了它一个类标签“Positive”。里面有四个词(把感叹号也算上),“手机”,“非常”,“好用”,“!”。我可以认为这4个词都对分类产生了影响,都是分类的依据。也就是无论什么地方出现了这四个词的其中之一,文本都可以被分类为“积极”。这个是把所有词都作为分类特征。
同样的,对这句话,我也可以选择它的双词搭配(Bigrams)作为特征。比如“手机 非常”,“非常 好用”,“好用 !”这三个搭配作为分类的特征。以此类推,三词搭配(Trigrams),四词搭配都是可以被作为特征的。
特征降维
特征降维说白了就是减少特征的数量。这有两个意义,一个是特征数量减少了之后可以加快算法计算的速度(数量少了当然计算就快了),另一个是如果用一定的方法选择信息量丰富的特征,可以减少噪音,有效提高分类的准确率。
所谓信息量丰富,可以看回上面这个例子“手机非常好用!”,很明显,其实不需要把“手机”,“非常”,“好用”,“!”这4个都当做特征,因为“好用”这么一个词,或者“非常 好用”这么一个双词搭配就已经决定了这个句子是“积极”的。这就是说,“好用”这个词的信息量非常丰富。
那要用什么方法来减少特征数量呢?
答案是通过一定的统计方法找到信息量丰富的特征。
统计方法包括:词频(Term Frequency)、文档频率(Document Frequency)、互信息(Pointwise Mutual Information)、信息熵(Information Entropy)、卡方统计(Chi-Square)等等。
在情感分类中,用词频选择特征,也就是选在语料库中出现频率高的词。比如我可以选择语料库中词频最高的2000个词作为特征。用文档频率选特征,是选在语料库的不同文档中出现频率最高的词。其他类似,都是要通过某个统计方法选择信息量丰富的特征。特征可以是词,可以是词组合。
文本特征化
在使用分类算法进行分类之前,第一步是要把所有原始的语料文本转化为特征表示的形式。
还是以上面那句话做例子,“手机非常好用!”
如果在NLTK 中,如果选择所有词作为特征,其形式是这样的:[ {“手机”: True, “非常”: True, “好用”: True, “!”: True} , positive]
如果选择双词作为特征,其形式是这样的:[ {“手机 非常”: True, “非常 好用”: True, “好用 !”: True} , positive ]
如果选择信息量丰富的词作为特征,其形式是这样的:[ {“好用”: True} , positive ]
无论使用什么特征选择方法,其形式都是一样的。都是[ {“特征1”: True, “特征2”: True, “特征N”: True, }, 类标签 ]
划分数据集
把用特征表示之后的文本分成开发集和测试集,把开发集分成训练集和验证集。机器学习分类必须有数据给分类算法训练,这样才能得到一个(基于训练数据的)分类器。有了分类器之后,就需要检测这个分类器的准确度。
分类算法学习
这个时候终于可以使用各种高端冷艳的机器学习算法啦!
我们的目标是:找到最佳的机器学习算法。
可以使用朴素贝叶斯(NaiveBayes),决策树(Decision Tree)等NLTK 自带的机器学习方法。也可以更进一步,使用NLTK 的scikit-learn 接口,这样就可以调用scikit-learn 里面的所有。
预测
在终于得到最佳分类算法和特征维度(数量)之后,就可以动用测试集。
直接用最优的分类算法对测试集进行分类,得出分类结果。对比分类器的分类结果和人工标注的正确结果,给出分类器的最终准确度。
开发实践
本次实践只是简单的进行文本评论正反面的预测。选取的材料是京东商城酒类商品的评论。
准备工作
准备人工标注好的好评和差评文本. good.txt bad.txt
- 好评

- 差评
- 停用词(上网查找的)
特征提取和选择
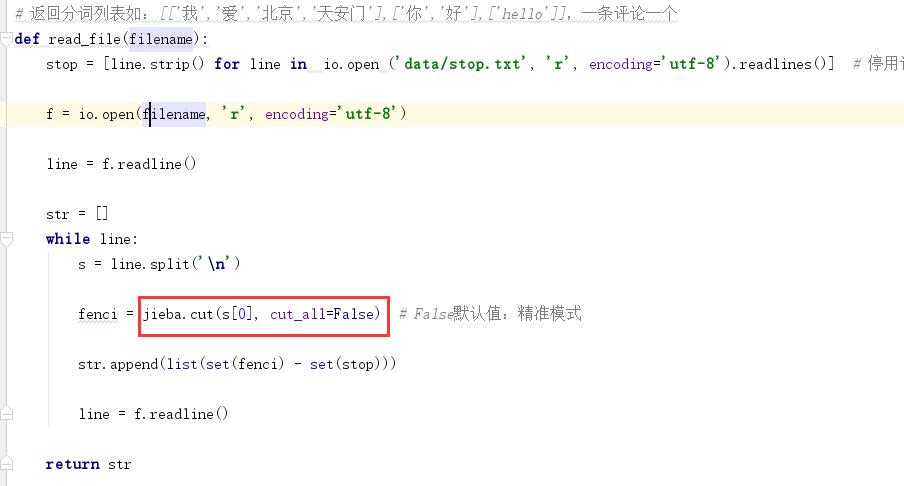
- 使用jieba分词对文本进行分词
- 构建特征
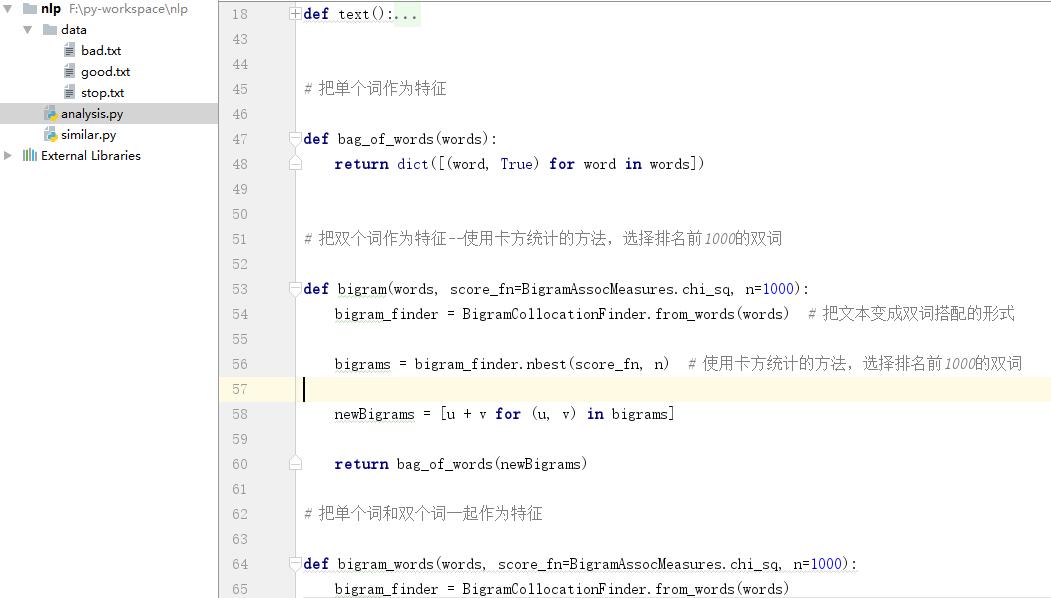
- 选择特征
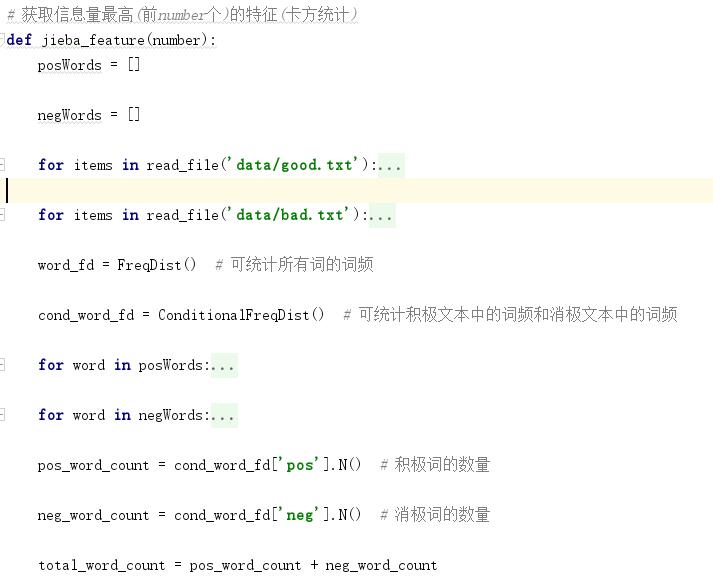

划分数据集

构建分类器


预测
下图是朴素贝叶斯得到的结果:可以看到正确率达到了90%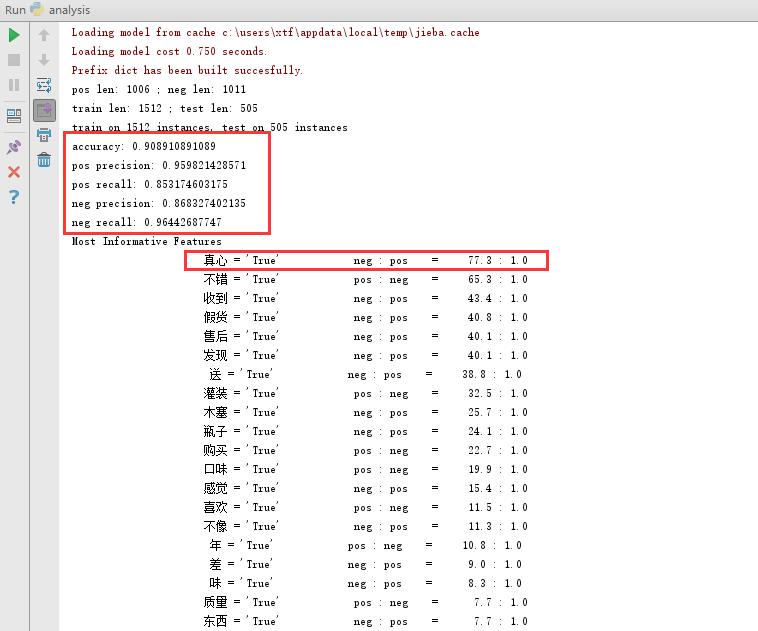
下图是其他算法得到的结果:可以看到逻辑回归和线性SVM正确率都在96%以上,效果不错。

