神经网络的入门知识参见神经网络(系列1)
本文主要对神经网络进行深入,探讨神经网络模型的学习。
代价函数
首先引入一些便于稍后讨论的新标记方法:
假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络层数,\(S_l\)表示每层的neuron个数(\(S_L\)表示输出层神经元个数),(\(S_L\)代表最后一层中处理单元的个数。
将神经网络的分类定义为两种情况:二类分类和多类分类:
二类分类:\(S_L=1\), y=0 or 1表示哪一类;
K类分类:\(S_L=K\), \(y_i = 1\)表示分到第i类;(K>2)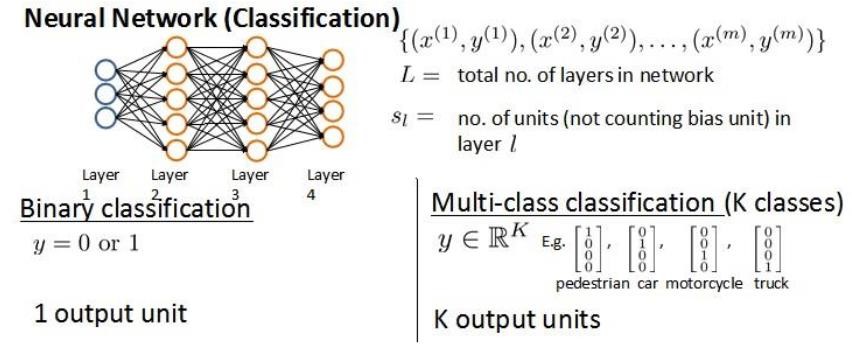
我们回顾逻辑回归问题中我们的代价函数为:
$$J(θ)=-\frac{1}{m}\sum_{i=1}^m\left(y^{(i)}log(h_θ(x^{(i)}))+(1-y^{(i)})log(1-h_θ(x^{(i)}))\right)+\frac{\lambda}{2m}\sum_{j=1}^nθ_j^2$$
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量y,但是在神经网络中,我们可以有很多输出变量,我们的\(h_θ(x)\)是一个维度为K的向量,并且训练集中的因变量也是同样维度的一个向量,因此代价函数会比逻辑回归更加复杂一些,为:
$$J(\Theta)=-\frac{1}{m}\Big[\sum_{i=1}^m\sum_{k=1}^K\left(y_k^{(i)}log((h_\Theta(x^{(i)}))_k)+(1-y_k^{(i)})log(1-(h_\Theta(x^{(i)}))_k)\right)\Big] \\\ + \frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{l+1}}(\Theta_{ji}^{(l)})^2$$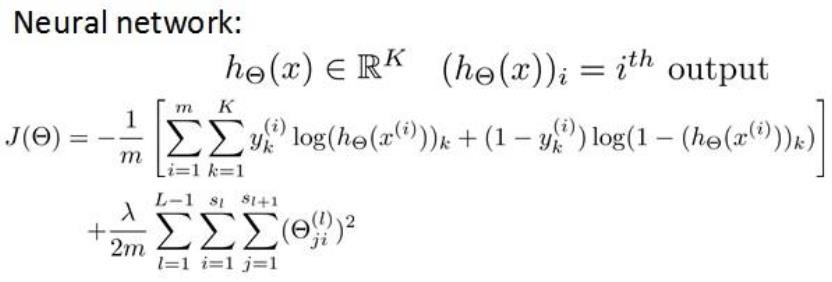
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出K个预测,基本上我们可以利用循环,对每一行特征都预测K个不同结果,然后在利用循环在K个预测中选择可能性最高的一个。
注意:j循环所有的行(由\(s_{l+1}\)层的激活单元数决定,l+1整体是下标),循环i则循环所有的列,由该层(\(s_l\)层)的激活单元数所决定。
反向传播算法
之前我们在计算神经网络预测结果的时候我们采用了一种正向传播方法,我们从第一层开始正向一层一层进行计算,直到最后一层的\(h_θ(x)\)。
现在,为了计算代价函数的偏导数\(\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)\),我们需要采用新的方法。
传统方法
机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定一些样本点,用合适的曲线揭示这些样本点随着自变量的变化关系。
深度学习同样也是为了这个目的,只不过此时,样本点不再限定为(x, y)点对,而可以是由向量、矩阵等等组成的广义点对(X,Y)。而此时,(X,Y)之间的关系也变得十分复杂,不太可能用一个简单函数表示。然而,人们发现可以用多层神经网络来表示这样的关系,而多层神经网络的本质就是一个多层复合的函数。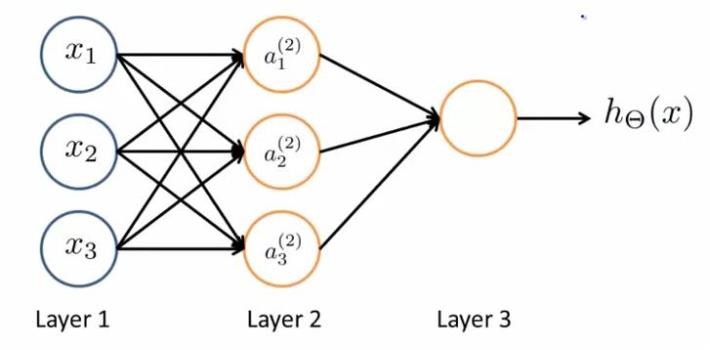
对应的表达式如下:
$$a_1^{(2)}=g(\Theta_{10}^{(1)}x_0+\Theta_{11}^{(1)}x_1+\Theta_{12}^{(1)}x_2+\Theta_{13}^{(1)}x_3) \\\\
a_2^{(2)}=g(\Theta_{20}^{(1)}x_0+\Theta_{21}^{(1)}x_1+\Theta_{22}^{(1)}x_2+\Theta_{23}^{(1)}x_3) \\\\
a_3^{(2)}=g(\Theta_{30}^{(1)}x_0+\Theta_{31}^{(1)}x_1+\Theta_{32}^{(1)}x_2+\Theta_{33}^{(1)}x_3)$$
$$h_{\Theta}(x)=a_1^{(3)}=g(\Theta_{10}^{(2)}a_0^{(2)}+\Theta_{11}^{(2)}a_1^{(2)}+\Theta_{12}^{(2)}a_2^{(2)}+\Theta_{13}^{(2)}a_3^{(2)})$$
和直线拟合一样,深度学习的训练也有一个目标函数,这个目标函数定义了什么样的参数才算一组“好参数”,不过在机器学习中,一般是采用成本函数(cost function),然后,训练目标就是通过调整每一个权值\(\Theta_{ij}\)来使得cost达到最小。cost函数也可以看成是由所有待求权值\(\Theta_{ij}\)为自变量的复合函数,而且基本上是非凸的,即含有许多局部最小值。但实际中发现,采用我们常用的梯度下降法就可以有效的求解最小化cost函数的问题。
梯度下降法需要给定一个初始点,并求出该点的梯度向量,然后以负梯度方向为搜索方向,以一定的步长进行搜索,从而确定下一个迭代点,再计算该新的梯度方向,如此重复直到cost收敛。那么如何计算梯度呢?
假设我们把cost函数表示为\(J(\Theta_{11},\Theta_{12},\Theta_{13},\Theta_{ij},…,\Theta_{mn})\), 那么它的梯度向量就等于\(\nabla J = \frac{\partial J}{\partial \Theta_{11}}e_{11}+…+\frac{\partial J}{\partial \Theta_{mn}}e_{mn}\), 其中\(e_{ij}\)表示正交单位向量。为此,我们需求出cost函数J对每一个权值\(\Theta_{ij}\)的偏导数。而BP算法正是用来求解这种多层复合函数的所有变量的偏导数的利器。
我们以求e=(a+b)*(b+1)的偏导为例。
它的复合关系画出图可以表示如下: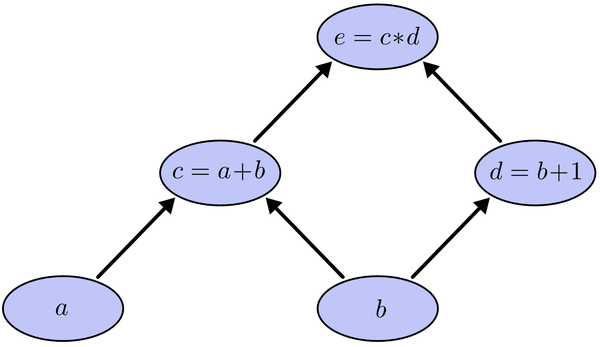
为了求出a=2,b=1时,e的梯度,我们可以先利用偏导数求出不同层之间的邻节点的偏导关系,如下图所示: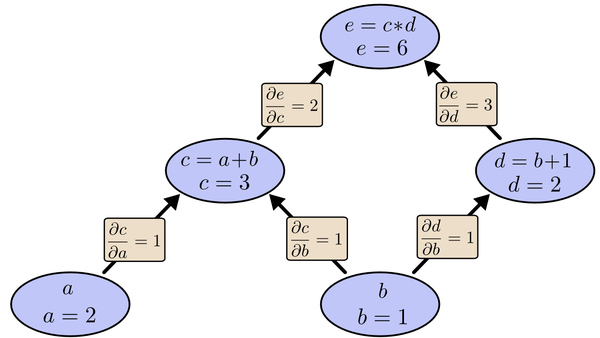
利用链式法则我们知道:
$$\frac{\partial e}{\partial a}=\frac{\partial e}{\partial c}\frac{\partial c}{\partial a}$$
$$\frac{\partial e}{\partial b}=\frac{\partial e}{\partial c}\frac{\partial c}{\partial b}+\frac{\partial e}{\partial d}\frac{\partial d}{\partial b}$$
链式法则在上图中的意义是什么呢?其实不难发现,\(\frac{\partial e}{\partial a}\)的值等于从a到e的路径上的偏导值的乘积,而\(\frac{\partial e}{\partial b}\)的值等于从b到e的路径1(b-c-e)上的偏导值的乘积加上路径2(b-d-e)上的偏导值的乘积。也就是说,对于上层节点p和下层节点q,要求得,需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到的值。
大家也许已经注意到,这样做是十分冗余的,因为很多路径被重复访问了。比如上图中,a-c-e和b-c-e就都走了路径c-e。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。
同样是利用链式法则,BP算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。
正如反向传播(BP)算法的名字说的那样,BP算法是反向(自上往下)来寻找路径的。
从最上层的节点e开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以e到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等e所在的层按照这样传播完毕后,第二层的每一个节点都“堆放”些值,然后我们针对每个节点,把它里面所有“堆放”的值求和,就得到了顶点e对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点e对它们的偏导值,以”层”为单位重复上述传播过程,即可求出顶点e对每一层节点的偏导数。
以上图为例,节点c接受e发送的1*2并堆放起来,节点d接受e发送的1*3并堆放起来,至此第二层完毕,求出各节点总堆放量并继续向下一层发送。节点c向a发送2*1并对堆放起来,节点c向b发送2*1并堆放起来,节点d向b发送3*1并堆放起来,至此第三层完毕,节点a堆放起来的量为2,节点b堆放起来的量为2*1+3*1=5, 即顶点e对b的偏导数为5.
举个不太恰当的例子,如果把上图中的箭头表示欠钱的关系,即c→e表示e欠c的钱。以a, b为例,直接计算e对它们俩的偏导相当于a, b各自去讨薪。a向c讨薪,c说e欠我钱,你向他要。于是a又跨过c去找e。b先向c讨薪,同样又转向e,b又向d讨薪,再次转向e。可以看到,追款之路,充满艰辛,而且还有重复,即a, b 都从c转向e。
而BP算法就是主动还款。e把所欠之钱还给c,d。c,d收到钱,乐呵地把钱转发给了a,b,皆大欢喜。
路径合并
将所有路径累加的问题在于,在可能的路径数中,很容易陷入爆炸式组合增长。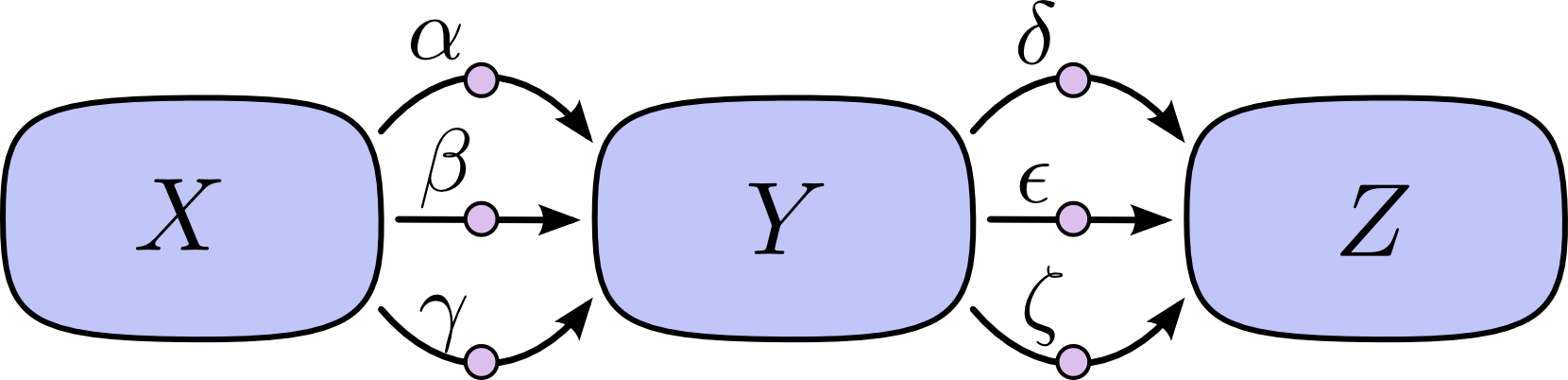
在上图中,从X到Y有3条路径,从Y到Z也有3条路径。如果要求\(\frac{\partial Z}{\partial X}\),我们需要把所有路径累加起来,也就是共9条路径。
$$\frac{\partial Z}{\partial X} = \alpha\delta + \alpha\epsilon + \alpha\zeta + \beta\delta + \beta\epsilon + \beta\zeta + \gamma\delta + \gamma\epsilon + \gamma\zeta$$
上图只有9条路径,但是随着图复杂程度的增加,路径数很容易呈现爆炸式增长。
和直接将所有路径累加相反,更好的方法是合并路径:
$$\frac{\partial Z}{\partial X} = (\alpha + \beta + \gamma)(\delta + \epsilon + \zeta)$$
这就是前向传播(forward-mode differentiation)和后向传播(reverse-mode differentiation)。它们都是通过合并路径的方法来更有效的计算路径和。和直接显示地把所有路径加起来不同,它们通过在每个节点上,向后合并路径的方式来更有效的计算路径和。实际上,两个方法每条边都只计算了一次。
前向传播起始于图的输入节点,一直向前直到最后一个节点。在每个节点上,它将传入(feed in)的每一条路径累加。每一条路径都代表了输入对该节点的影响。通过将它们累加起来,我们获得了不同输入对该节点总的影响。这就是导数的定义。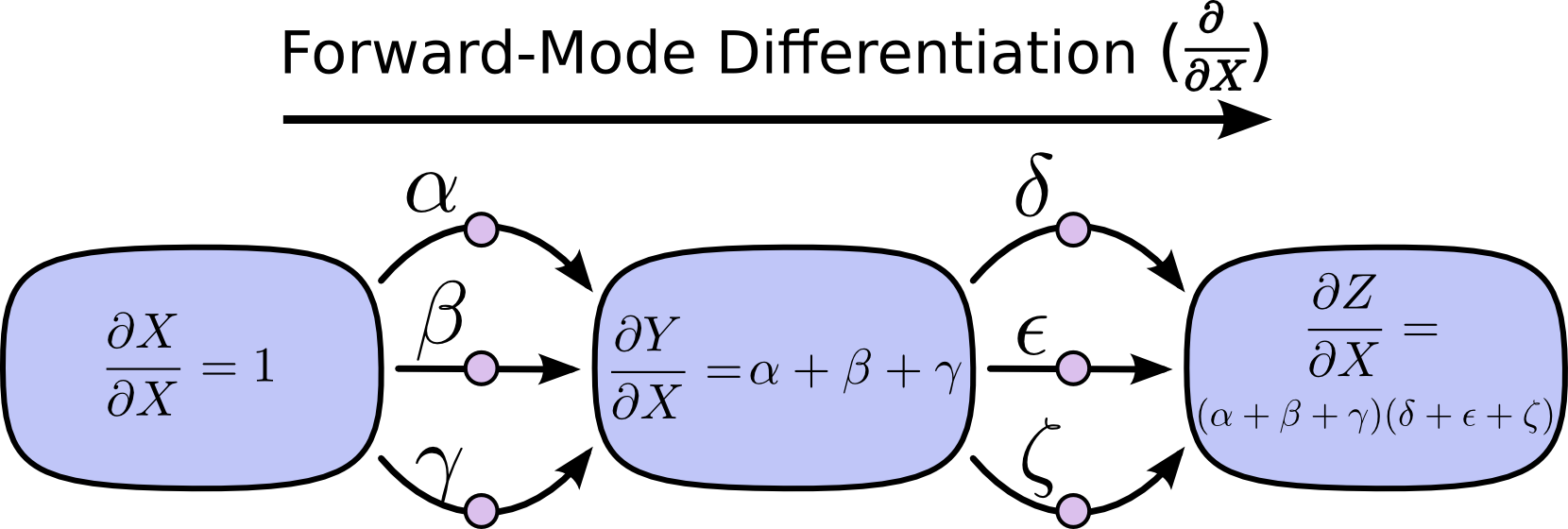
前向传播就像你刚刚入门微积分课程时学到的方法。而后向传播,起始于图的输出节点,一直向后直到第一个节点。在每一个节点上,将起源于(originated at)该节点的所有路径合并。
前向传播跟踪一个输入如何影响每一个节点。反向传播跟踪每一个节点如何影响一个输出节点。即,前向传播将\(\frac{\partial}{\partial X}\)应用到每一个节点(每个节点对输入求导),而后向传播将\(\frac{\partial Z}{\partial}\)应用到每一个节点(输出对每个节点求导)。
反向传播优势
现在,我们可能会疑问,为什么人们更关心后向传播,它看起来似乎和前向传播差不多,那它的优势在哪?
让我们回到前面的那个例子中:
我们可以使用前向传播算法从b自底向上。我们需要求每个节点对b的导数。(即b如何影响每一个节点)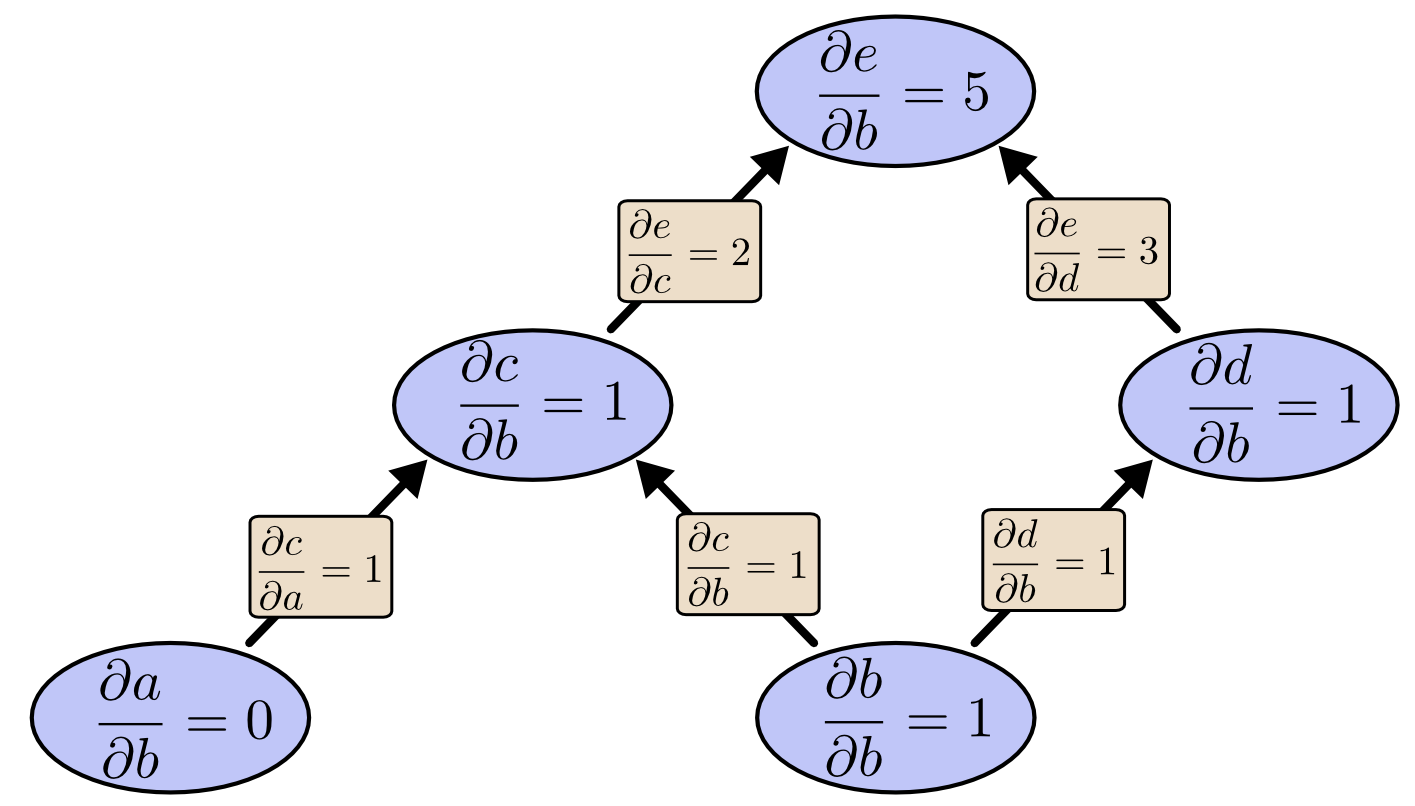
如果我们使用后向传播从e自顶向下,我们需要求e对每个节点的导数(即每个节点如何影响e)。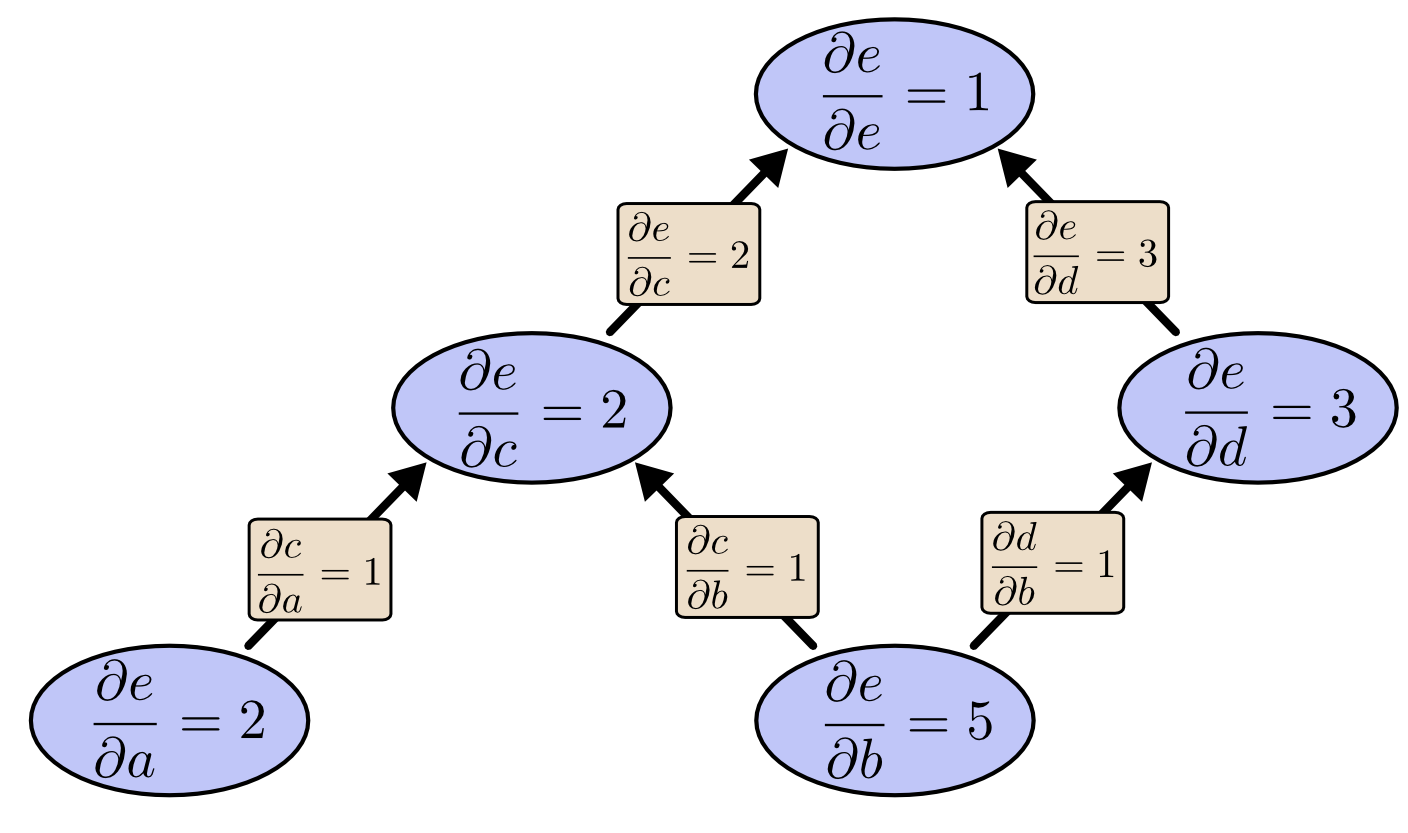
需要强调的是: 当我说反向传播给了我们e对每个节点的导数,需要强调的是确实是每个节点,我们得到了\(\frac{\partial e}{\partial a}\)和\(\frac{\partial e}{\partial b}\),即e对每一个输入的导数。前向传播只给了我们单独的一个b的导数,但是后向传播给了我们所有的输入的导数。
对这幅图而言,只得到了2倍的加速比,想象一下如果有上百万的输入节点和1个输出节点,前向传播需要我们遍历这个图上百万次才能得到导数,而后向传播只需要遍历1次即可,这就得到了上百万的加速比。
在神经网络中,我们的代价函数经常拥有上百万个参数,因此反向传播能够让我们训练的速度大大提高。
那前向传播什么时候适用呢?如果只有少量的输入,而拥有大量的输出,此时前向传播速度更快。
补充:对信息的处理,分为前向和反向两种,即从因到果和从果到因。前者适合人类的思考模式,但对机器而言,它需要的是运算,显然,反向运算更便捷(如上中所说,这是有前提的,即输入因子多于输出因子,这也符合逻辑,当我们要做出一个判断、得出一个结论,总会从方方面面进行思考,然后在提取、凝练,即归纳、总结),就像梳理头发时,我们都是从发根向发梢梳理——头皮为一个质点,向发梢逐渐发散,从一到多、从总到分的梳理、计算过程。所以反向运算比较普及,是因为运算成本更低。
反向传播算法
我们的目标是为了计算代价函数的偏导数:
$$\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)$$
我们需要采用一种反向传播算法,也就是首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。
以一个例子来说明反向传播算法。
假设我们的训练集只有一个实例\((x^{(1)},y^{(1)})\),我们的神经网络是一个四层的神经网络,其中 K=4,SL=4,L=4: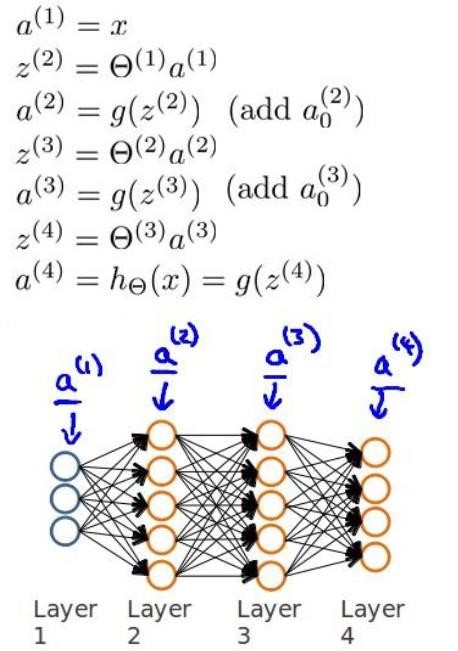
前向传播算法:
$$a^{(1)}=x \\\\
z^{(2)}=\Theta^{(1)}a^{(1)} \\\\
a^{(2)}=g(z^{(2)}) (add \ a_0^{(2)}) \\\\
z^{(3)}=\Theta^{(2)}a^{(2)} \\\\
a^{(3)}=g(z^{3}) (add \ a_0^{(3)}) \\\\
z^{(4)}=\Theta^{(3)}a^{(3)} \\\\
a^{(4)}=h_\Theta(x)=g(z^{(4)})
$$
我们从最后一层的误差开始计算,误差是激活单元的预测值(\(a_k^{(4)}\))与实际值(\(y^{k}\))之间的误差.(k=1:K)
我们用\(\delta\)来表示误差,则:
$$\delta^{(4)}=a^{(4)}-y$$
我们利用这个误差值来计算前一层的误差:
$$\delta^{(3)}=(\Theta^{(3)})^T\delta^{(4)}.*g’(z^{(3)})$$
其中,\(g’(z^{(3)})\)为sigmoid函数的导数,\(g’(z^{(3)})=a^{(3)}*(1-a^{(3)})\)。而\((\Theta^{(3)})^T\delta^{(4)}\)则是权重导致的误差的和。
注意到:\((\Theta^{(3)})^T\)取了转置,正常\(\Theta\)例如:
$$\Theta=\begin{bmatrix} \Theta_{10} \ \Theta_{11} \ \Theta_{12} \ \Theta_{13}\\\ \Theta_{20} \ \Theta_{21} \ \Theta_{22} \ \Theta_{23}\\\ \Theta_{30} \ \Theta_{31} \ \Theta_{32} \ \Theta_{33}\end{bmatrix}$$
每一行都代表第j层的所有神经元到第j+1层某一个神经元的连线(权重)。例如第一行就代表第j层的所有神经元到第j+1层的第一个神经元的连线。而转置\(\Theta\)后,每一行代表第j层某一个神经元到第j+1层的所有神经元的连线,可以理解成j层某一个神经元导致的j+1层总误差的情况。
另外,.*即点乘,代表矩阵对应位置的数字相乘。
下一步是继续计算第二层的误差:
$$\delta^{(2)}=(\Theta^{(2)})^T\delta^{(3)}.*g’(z^{(2)})$$
因为第一层为输入变量,不存在误差,我们有了所有的误差的表达式后,便可以计算代价函数的偏导数了,假设\(\lambda=0\),即我们不做任何归一化处理的话:
$$\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)=a_j^{(l)}\delta_i^{l+1}$$
重要的是清楚地知道上面式子中上下标的含义:
l代表目前所计算的是第几层
j代表目前计算层中的激活单元的下标,也将是下一层的第j个输入变量的下标。
i代表下一层中误差单元的下标,是受到权重矩阵中第i行影响的下一层中的误差单元的下标。
即:\(\frac{\partial}{\partial \Theta_{ij}^{(l)}}\)是对第l层的第j个神经元到第l+1层的第i个神经元的连线(权重)求偏导。
\(a_j^{(l)}\)是第l层第j个神经元经过sigmoid函数计算后的值。
\(\delta_i^{l+1}\)是第l+1层第i个神经元的误差。
例如: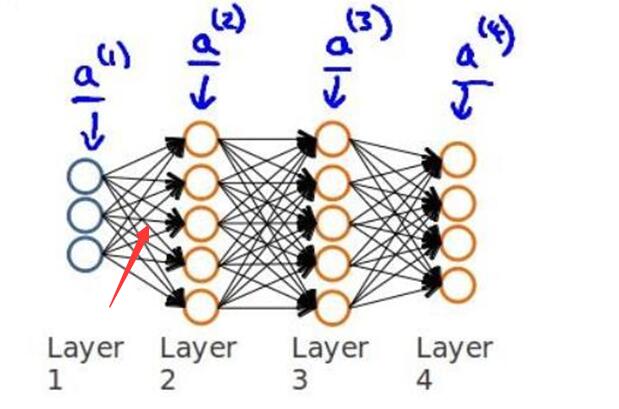
对图中红色的这条线求偏导:
$$\frac{\partial}{\partial \Theta_{41}^{(1)}}=a_1^{(1)}*\delta_4^{(2)}$$
如果我们考虑归一化处理,并且我们的训练集是一个特征矩阵而非向量。在上面的特殊情况中,我们需要计算每一层的误差单元来计算代价函数的偏导数。在更为一般的情况中,我们同样需要计算每一层的误差单元,但是我们需要为整个训练集计算误差单元,此时的误差单元也是一个矩阵,我们用\(\Delta_{ij}\)来表示这个误差矩阵。第l层的第i个激活单元受到第j个参数影响而导致的误差。
我们的算法:
即首先用正向传播方法计算出每一层的激活单元,利用训练集的结果与神经网络预测的结果求出最后一层的误差,然后利用该误差运用反向传播法计算出直至第二层的所有误差。
在求出\(\Delta_{ij}^{(l)}\)后,我们便可以计算代价函数的偏导数了,计算方法如下: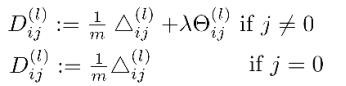
反向传播理解
疑问1:为什么输出层的\(\delta\)为\(\delta^{(L)}=a^{(L)}-y\)?
很多人认为输出层的偏差量就是计算值减实际值这么简单,又或者认为是线性回归代价函数求导的结果,即\(J(\Theta)=\frac{1}{2}(h_\Theta(x)-y)^2\),求导得到:\(\frac{\partial}{\partial a^{(L)}}J(\Theta)=a^{(L)}-y\)。其实不然,要知道我们的代价函数是逻辑回归的代价函数。详细见下面分析。
疑问2:\((\Theta^{(l)})^T\delta^{(l+1)}\)怎么理解?
所谓“偏差”应该这么理解:对于后一层某一个结点上出现的偏差,前一层的每一个结点都要承担一部分责任,所以我们可以把后一层结点的偏差量按照系数比例分配给前一层的结点。同时,前一层的某一个结点,对后一层的每一个节点都承担着责任,那么它的“总责任”就是这些所有的小责任之和。因此这里面矩阵的转置,我们前面也有提到,转置后的每一行实际上代表l层的某一个神经元到l+1层的每一个神经元的连线(权重)。和后一层的\(\delta^{(l+1)}\)进行矩阵乘后,实际上相当于l层的这个神经元分担掉l+1层所有神经元的这些小的误差,将这些小的误差之和作为自己的责任承担下来。如果你仔细想想这个矩阵乘法的计算过程,会发现正好就是上面说的这个责任分配与求和的过程。这就是【疑问2】的答案。
疑问3:为什么前一层的\(\delta^{(l)}\)和后一层的\(\delta^{(l+1)}\)的关系是\(\delta^{(l)}=(\Theta^{(l)})^T\delta^{(l+1)}.*g’(z^{(l)})\)?
可以发现,在疑问2的基础上,该式子还多了个因子\(.*g’(z^{(l)})\)。为什么呢?详细见下面分析。
疑问4:为什么\(\delta_i^{(l+1)}\)计算完后,还要乘以前一层的\(a_j^{(l)}\)后,才是偏导\(\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)\)的结果?
即,\(\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)=a_j^{(l)}\delta_i^{l+1}\)详见下面。
详细推导
我们的目标是证明:
$$\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)=a_j^{(l)}\delta_i^{l+1} \\\\
其中,\delta^{(l)}=(\Theta^{(l)})^T\delta^{(l+1)}.*g’(z^{(l)}), \\\\可以取l=l+1,求得\delta^{(l+1)},\delta_i^{l+1}为\delta^{(l+1)}的第i个元素,即l+1层误差向量的第i个元素。
$$
是对第\(l\)层的第\(j\)个神经元到第\(l+1\)层的第\(i\)个神经元的连线(权重)求偏导。
首先回顾一下前面的一些定义:
$$a^{(l+1)}=g(z^{(l+1)}) \\\\
g(z)=\frac{1}{1+e^{-z}} \\\\
z^{(l+1)}=\Theta^{(l)}a^{(l)} \\\\
其中,g(z)为sigmoid函数 \\\\
z^{(l+1)}代表l+1层经过l层权重加权后的结果 \\\\
a^{(l+1)}代表z^{(l+1)}经过sigmoid函数后的输出值 \\\\
$$
为了使用这些定义,我们可以将上面的偏微分式子使用链式法则展开:
$$\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)=\frac{\partial J(\Theta)}{\partial a_i^{(l+1)}}\frac{\partial a_i^{(l+1)}}{\partial z_i^{(l+1)}}\frac{\partial z_i^{(l+1)}}{\partial \Theta_{i,j}^{(l)}}$$
- 首先看最后一项:
$$z_i^{(l+1)}=\Theta_{1,i}^{(l)}a_1^{(l)}+\Theta_{2,i}^{(l)}a_2^{(l)}+…$$
所以:
$$\frac{\partial z_i^{(l+1)}}{\partial \Theta_{i,j}^{(l)}}=a_j^{(l)}$$
顺便说一下,右边前两项的乘积,就是课程中引入的\(\delta\)的值。这就解释了【疑问4】中,为什么\(\delta_i^{(l+1)}\)计算完后,还要乘以前一层的\(a_j^{(l)}\)后,才是偏导\(\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)\)的结果,即\(\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)=a_j^{(l)}\delta_i^{l+1}\) 接下来第二项
这就是sigmoid函数的求导:
$$g’(z)=\frac{e^{-z}}{(1+e^{-z})^2}=\frac{1}{1+e^{-z}}*\frac{e^{-z}}{(1+e^{-z})}=g(z)(1-g(z))$$
根据定义:\(g(z^{(l)})=a^{(l)}\)
因此,我们\(\delta^{(l)}=(\Theta^{(l)})^T\delta^{(l+1)}.*g’(z^{(l)})\)改写成:
$$\delta^{(l)}=(\Theta^{(l)})^T\delta^{(l+1)}.*a^{(l)}.*(1-a^{(l)})$$
这个式子留在下面【疑问1】的证明。第一项
首先回顾下代价函数:
$$J(\Theta)=-ylog(h_\Theta(x))-(1-y)log(1-h_\Theta(x))$$
对输出层\(a^{(L)}\)求导:
$$\frac{\partial}{\partial a^{(L)}}J(\Theta)=\frac{a^{(L)}-y}{a^{(L)}-(a^{(L)})^2} \\\\
注意对于输出层,h_\Theta(x)=a^{(L)}$$
因此根据前面定义:\(\delta\)为前两项偏导的乘积,即
$$\delta^{(L)}=\frac{a^{(L)}-y}{a^{(L)}-(a^{(L)})^2}a^{(L)}(1-a^{(L)})=a^{(L)}-y$$
这就解决了【疑问1】中的疑惑。实际上并不是简单的相减,而只是凑巧结果是这样。
对于【疑问1】【疑问2】的推导,即
$$\delta^{(l)}=(\Theta^{(l)})^T\delta^{(l+1)}.*g’(z^{(l)})$$
根据前面定义:\(\delta\)为前两项偏导的乘积,
我们来看下面式子的前两项偏导,
$$\frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)=\frac{\partial J(\Theta)}{\partial a_i^{(l+1)}}\frac{\partial a_i^{(l+1)}}{\partial z_i^{(l+1)}}\frac{\partial z_i^{(l+1)}}{\partial \Theta_{i,j}^{(l)}}$$
实际上前两项偏导结果就是:
$$\frac{\partial}{\partial z_{i}^{(l+1)}}J(\Theta)=\frac{\partial J(\Theta)}{\partial a_i^{(l+1)}}\frac{\partial a_i^{(l+1)}}{\partial z_i^{(l+1)}}$$
令\(l=l-1\),得到:
$$\frac{\partial}{\partial z_{i}^{(l)}}J(\Theta)=\frac{\partial J(\Theta)}{\partial a_i^{(l)}}\frac{\partial a_i^{(l)}}{\partial z_i^{(l)}}$$
利用链式法则得到:
$$\delta_{j}^{(l)}=\frac{\partial}{\partial z_{j}^{(l)}}J(\Theta)=\sum_k \frac{\partial J(\Theta)}{\partial z_k^{(l+1)}}\frac{\partial z_k^{(l+1)}}{\partial a_j^{(l)}}\frac{\partial a_j^{(l)}}{\partial z_{j}^{(l)}} \\\\
=\sum_k \delta_k^{(l+1)} \frac{\partial (\Theta_{kj}^{(l)}a_j^{(l)})}{\partial a_j^{(l)}}g’(z_j^{(l)}) \\\\
=\sum_k \delta_k^{(l+1)}\Theta_{kj}^{(l)}g’(z_j^{(l)})$$
1)上式是针对\(l\)层某一个神经元的求导,\(i\)(在这里k实际上就是l+1层神经元)代表\(l+1\)层神经元,\(j\)代表\(l\)层神经元。
2)求和相当于不同路径累加。
所以有:
$$\delta^{(l)}=(\Theta^{(l)})^T\delta^{(l+1)}.*g’(z^{(l)})$$
1)上式是求\(l\)层所有神经元误差的矩阵形式。
2)仔细看\(\Theta_{kj}^{(l)}\)的下标变换,从1开始\(\Theta_{1j}^{(l)}\),\(\Theta_{2j}^{(l)}\),\(\Theta_{3j}^{(l)}\)…,实际上就代表\(l\)层的第\(j\)个神经元到\(l+1\)层的所有神经元的连线(权重)。因为\(l+1\)层的神经元代表的是行,即下标中的第一个数字。实际上和\((\Theta^{(l)})^T\delta^{(l+1)}\)矩阵形式是一样的。
这就解决了【疑问2】【疑问3】
结论:
还有很多人说为什么这个值和很多别的网站,包括维基百科上说的不一样啊?因为很多别的网站包括维基百科,cost函数用的是线性回归的那种,它的偏微分就和逻辑回归的cost函数有差别了。具体地说,就差在分母的那一项上\(a^{(L)}-(a^{(L)})^2\)
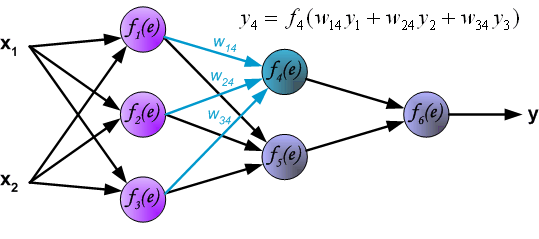
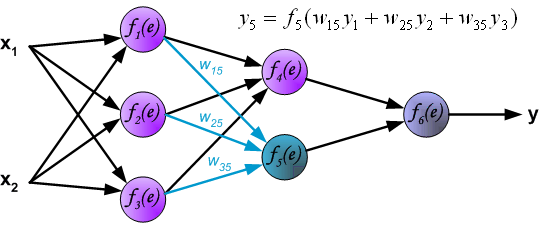
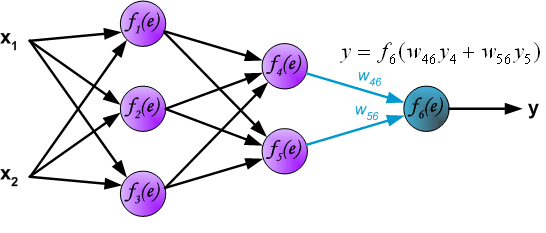
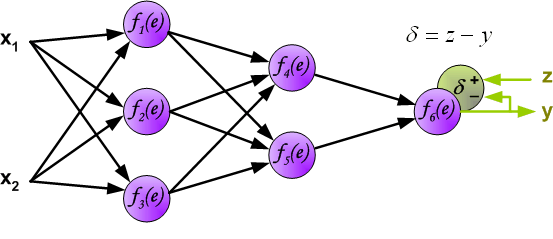
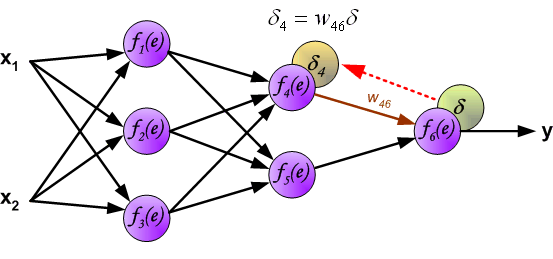
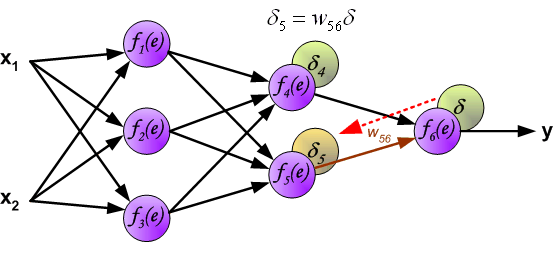
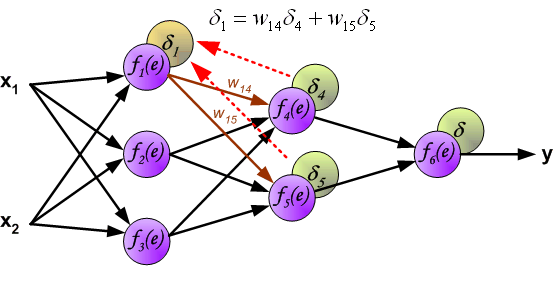
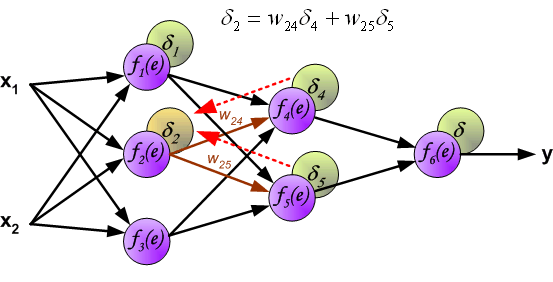
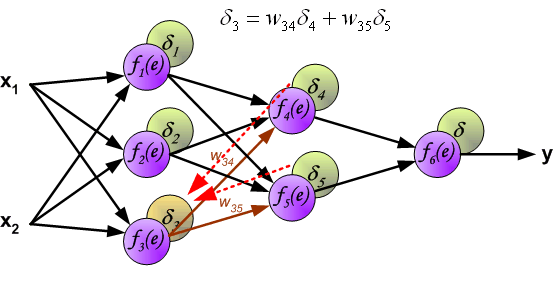
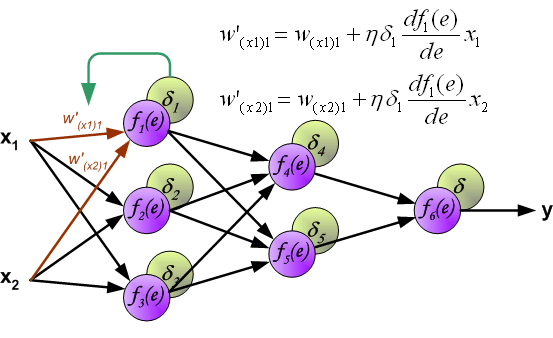
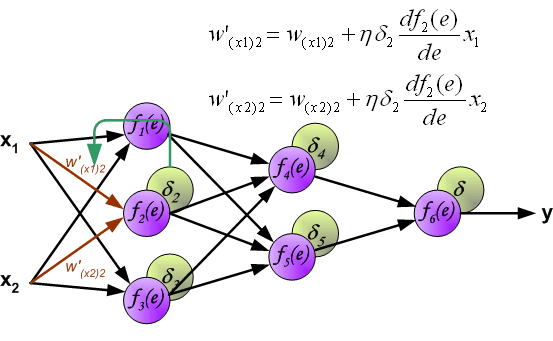
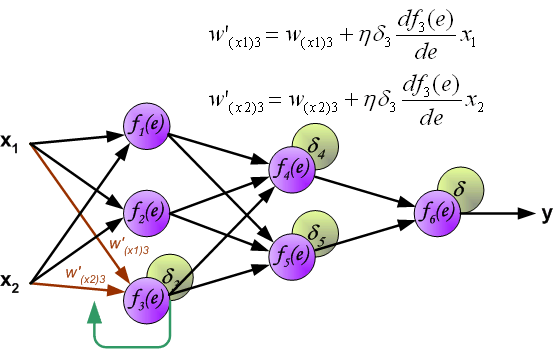
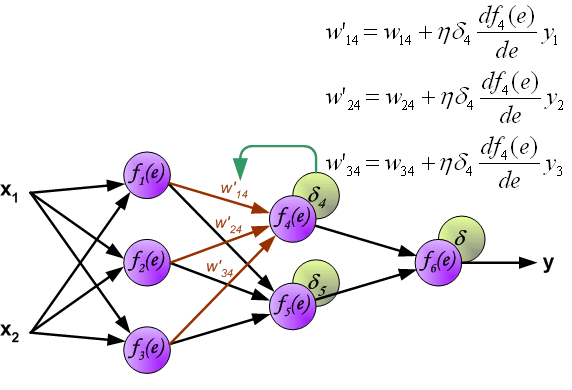
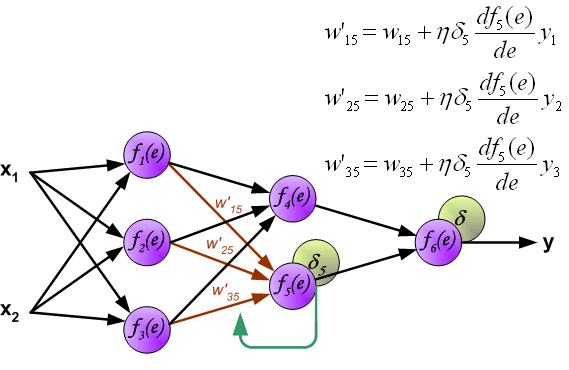
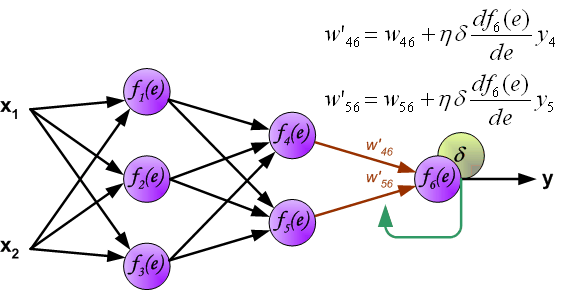
反向传播演示
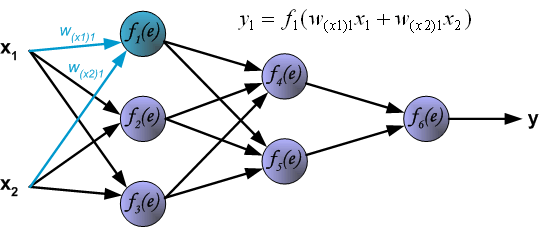
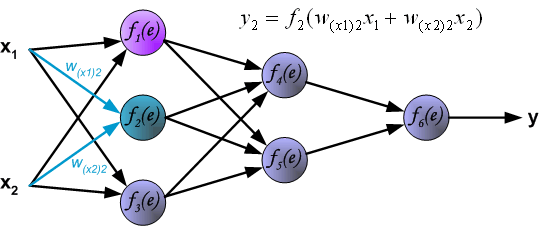
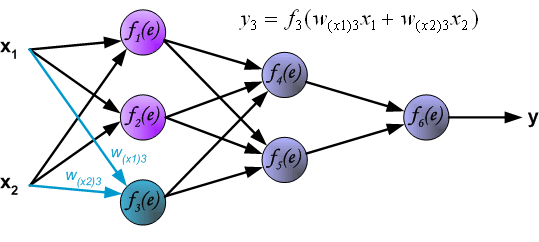
说明:图片摘自网上,存在一定的偏差,实际上是一样的,只不过是写法的不同,重点在于整个过程以及箭头。首先进行前向传播计算,这里的\(w\)对应\(\Theta\),\(f\)对应\(g\),即sigmoid函数,\(y\)对应\(a\),即sigmod的输出,\(e\)对应\(z\),即权重的线性组合结果。 \(\delta\)的计算式里的\(g’(z)\)项,图片中是放在最后梯度下降的时候求得导,即\(\frac{d_f}{d_e}\)。最后梯度下降公式中,不要忘记\(\delta\)还要乘以\(y\),即我们上文讲到的\(a\)。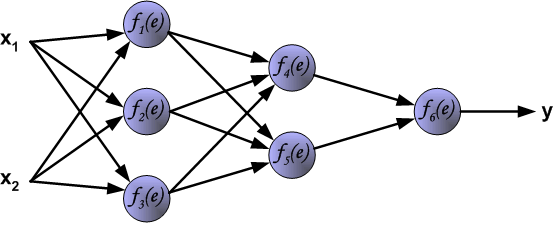
参考
Calculus on Computational Graphs: Backpropagation
Principles of training multi-layer neural network using backpropagation
A Step by Step Backpropagation Example
Learning representation by back-propagating errors
反向传播算法(过程及公式推导)
斯坦福机器学习
反向传播算法的一些争论与思考
知乎:如何直观的解释back propagation算法?

