本文对$AlphaZero$论文中的几个问题进行研究,对$AlphaZero$算法进行设计,并使用$Pytorch$实现$AlphaZero$五子棋应用。
几个问题的研究
残差网络的构造
对导师提出的几个问题进行研究。
a) 要确定残差网络的输入和输出
输入
残差网络的输入是从棋盘(Board) 构建棋面特征(Position/State Feature Plane)。这个特征构建方法可能需要考虑领域知识(Domain Knowledge),例如游戏规则等。在我的五子棋应用中,我构建的棋面特征有4个,每个棋面特征的规格和棋盘的规格一样,包括:
- 黑方所下棋子。二元值。1代表该位置为黑子,0代表其它(白子或为空)。
- 白方所下棋子。二元值。1代表该位置为白子,0代表其它(黑子或为空)。
- 上一步棋子。二元值。1代表该位置是上一步所下的棋子位置,0代表其它。这个特征平面主要是考虑到五子棋的局部特性,一般下一步棋所在位置就在上一步棋的附近,因此加入该特征能加快收敛。(体现领域知识)
- 当前下棋方。全为1或全为0。全为1代表当前下棋方是黑方,全为0代表当前下棋方是白方。
因此构造的一个样本输入是四通道的特征平面。(in_channels, board_width, board_height),其中,in_channels=4。
具体可参见Board类的current_state()方法。
对于围棋,根据论文,构造的特征平面总共只有上述的3类,即黑方所下棋子、白方所下棋子、当前下棋方。其中,黑方和白方所下棋子特征面都构建了8步历史走棋,加上当前下棋方,总共有17个特征平面。
更一般的,输入考察的主要是状态空间(State Space)的设计。对于棋类应用,每个时刻的棋盘就能直接表征状态空间的转移。而对于其他应用,例如无人机对抗、星际争霸等,一种方法是直接使用图像的方式采集每个时刻的状态,例如采集无人机双方历史8个时刻的图像(这里的问题是如何分离开双方,对于棋类应用直接用黑白棋颜色区分开,分别构建双方的特征平面)。这方面需要进一步研究。
输出
根据论文,输出分成:Policy Head和Value Head。 Policy Head是下一步棋的动作概率分布$\pi$; Value Head是当前棋面对应下棋方获胜的估计值$z$。这两个输出都用于MCTS模拟过程。
更一般的,输出考察的主要是动作空间(Action Space)的设计。Policy Head需要输出下一步动作的概率分布$\pi$。对于棋类应用,动作很简单,直接使用下棋的位置来表征动作。而对于其他应用,例如无人机对抗,动作考察的因素很多,这里面要重点调研一下飞机作战是如何控制的。每个动作要考察多种因素,例如方向盘、是否发射子弹、发射角度等等。我觉得动作空间的设计是不同应用需要定制最多的地方,也是最难、最关键的地方。其余因素基本都是通用、类似的。
b) 要确定残差网络的组成(层数和每一层的结构)。不指望一口气搭个80层,能不能从3层搭起(例如:包含一个全连接层、一个Softmax层,还有什么?),构造一个原型系统?
残差网络的组成仍然根据论文来构造。核心部分包括如下几个:
Common Layers: Policy Head和Value Head所共用的层。
A residual tower that consists of a single convolutional block followed by either 19 or 39 residual blocks 4,即1个卷积块后跟19个或39个残差块,卷积块和残差块结构如下:
- Convolutional Block: 卷积块
- Conv2d卷积层:A convolution of 256 filters of kernel size 3 × 3 with stride 1.
- BatchNorm2d标准化层:Batch normalization.
- Relu激活函数:A rectifier nonlinearity.
- Residual Block: 残差块
- Conv2d卷积层:A convolution of 256 filters of kernel size 3 × 3 with stride 1.
- BatchNorm2d标准化层:Batch normalization.
- Relu激活函数:A rectifier nonlinearity.
- Conv2d卷积层:A convolution of 256 filters of kernel size 3 × 3 with stride 1.
- BatchNorm2d标准化层:Batch normalization.
- Identity Mapping自映射层:A skip connection that adds the input to the block.
- Relu激活函数:A rectifier nonlinearity.
上述输出需要经过两个Heads,分别输出下一步棋的动作概率分布和当前棋面下棋方获胜的概率。
The output of the residual tower is passed into two separate ‘heads’ for computing the policy and value.
- Convolutional Block: 卷积块
Policy Head
- Conv2d卷积层: A convolution of 2 filters of kernel size 1 × 1 with stride 1
- BatchNorm2d标准化层:Batch normalization.
- Relu激活函数:A rectifier nonlinearity.
- Full-Connected全连接层:A fully connected linear layer that outputs a vector of size 19 2 + 1 = 362, corresponding to logit probabilities for all intersections and the pass move.
- Softmax激活函数:输出动作概率分布。
Value Head
- Conv2d卷积层: A convolution of 1 filters of kernel size 1 × 1 with stride 1
- BatchNorm2d标准化层:Batch normalization.
- Relu激活函数:A rectifier nonlinearity.
- Full-Connected全连接层:A fully connected linear layer to a hidden layer of size 256.
- Relu激活函数:A rectifier nonlinearity.
- Full-Connected全连接层:A fully connected linear layer to a scalar.
- Tanh激活函数:outputting a scalar in the range [−1, 1],输出获胜估计值。
因此问题中所说的全连接层、Softmax层等都体现在上述组件当中。
c) 利用TensorFlow或者Keras 的API,构造残差网络
目前我使用Pytorch可以很方便的搭建上述残差网络。但是实际肯定运行不起来。故实际运行时,我搭建了个简单的残差网络,网络结构完全一致,只不过只使用1个残差块,可以在腾讯云1核 1GB的普通机器上跑起来。
具体可参见代码PolicyValueNet。
TensorFlow搭建残差网络也挺方便。
d) 对残差网络的参数进行调优
残差网络的参数,我的理解主要是不同层的参数,比如卷积层的卷积核数量、全连接层隐藏神经元数量以及正则化系数等。目前这块还做的不够,主要是凭感觉,同时也受限于机器性能瓶颈。并且论文中给出的参数只是适用于围棋比赛,对于其他游戏还需要实际进行调优。
博弈框架的构造
蒙特卡罗搜索树算法根据论文实现。MCTS主要需要考察两个核心要素:状态空间(State Space)、动作空间(Action Space)。状态空间用于表示树节点,动作空间用于表示边。这两个核心要素实际上是上述构建残差网络输入输出时需要考察的,蒙特卡罗树使用该残差网络来指导模拟过程。因此除了残差网络不同以外,MCTS算法框架基本是一致的,都是分成Select、Expand、Evaluate、Backup、Play几个阶段。
a) 在下围棋上,如何实现蒙特卡洛搜索树?
下围棋中蒙特卡罗搜索树需要定制设计通用蒙特卡罗搜索树中的残差网络,具体而言就是残差网络输入(状态空间)和输出(动作空间)。
b) 在星际争霸(StarCraft)上,如何实现蒙特卡洛搜索树?
星际争霸中蒙特卡罗搜索树需要定制设计通用蒙特卡罗搜索树中的残差网络,具体而言就是残差网络输入(状态空间)和输出(动作空间)。
实际上,不管是下围棋还是星际争霸,残差网络都相当于是事先设计好的黑箱,只需要借助它指导蒙特卡罗搜索过程即可,MCTS搜索过程对所有应用几乎都是通用的,除了个别参数需要针对不同应用调优。
c) 如何构造通用的博弈框架?
通用博弈框架依赖于通用MCTS搜索过程,使用MCTS进行走棋,不断自我对弈就是一个博弈的过程。根据上述讨论,MCTS搜索过程是通用的,因此就我目前理解,博弈框架构造也是通用的。
MCTS搜索模拟过程:使用神经网络$f_\theta$来指导模拟过程。搜索树的每条边存放该边所对应的动作的先验概率$P(s,a)$,访问次数$N(s,a)$、累积动作估计值$W(s,a)$, 平均动作估计值$Q(s,a)$。
- Select: 每次模拟从当前棋面对应的根节点s开始,不断迭代的选择置信上界$Q(s,a)+U(s,a)$最大的动作$a$进行搜索,一直搜索到遇到叶子节点。其中,$U(s,a)=c_{puct}P(s,a)\frac{\sqrt{\sum_b N(s,b)}}{1+N(s,a)}$, $c_{puct}$用于控制Exploration程度。
- Expand and Evaluate: 访问到叶子节点时,进行扩展并评估。使用神经网络产生每个动作(隐含着此前对动作状态空间的设计)的先验概率和当前局势的评估值。$(P(s’, \dot{}), V(s’) )=f_\theta(s’)$。此处体现了神经网络是如何指导蒙特卡罗搜索的。扩展节点初始化信息:$N(s’, a) = 0,W(s’,a)=0, Q(s’,a)=0, P(s’,a) = p_a$, 其中$p_a$是神经网络产生的先验概率。
- Backup: 更新到达叶子节点所经过的边的访问次数、W值、Q值等。$N(s,a)=N(s,a)+1$, $W(s,a)=W(s,a)+v$, $Q(s,a)=\frac{W(s,a)}{N(s,a)}$, 其中$v$是神经网络对叶子节点的评估值。
- Play: 多次模拟过程结束后,得到搜索概率分布$\pi=\alpha_\theta(s)$, 搜索概率正比于访问次数的某次方$\pi_a \propto N(s,a)^{1/ \tau}$, $\tau$称为温度参数(temperature parameter)。那么最终的走棋Play,可以使用该分布$\pi$来抽样动作$a$。
上述前3个步骤是一个线程所执行的单次模拟过程。MCTS我个人觉得最难的地方在于多线程并行,每个线程单独执行一次模拟,最后再在Play阶段综合所有的模拟过程,得到概率分布。
对于多线程并行,论文中引入虚拟损失virtual loss来实现并行。基本思想是,引入虚拟损失确保每一个线程评估不同的节点。实现方法概括为:把节点的动作估计值减去一个很大的值,避免其他搜索线程走相同的路。具体而言,每个线程执行1次模拟过程,并引入虚拟损失$n_{vl}$, 在每次模拟的开始,假设已经输了$n_{vl}$局,则$N(s,a) = N(s,a)+n_{vl}$, $W(s,a) = W(s,a) - n_{vl}$。这样处理后,其他线程在Select阶段倾向于不选该路径。模拟到Backup时,需要把虚拟损失扣除,即$N(s,a)=N(s,a)-n_{vl}+1, $$W(s,a)=W(s,a)+n_{vl}+v$。
Q算法的实现
AlphaZero中的强化学习算法使用的是Policy Iteration。Policy Iteration核心步骤分成Policy Evaluation和Policy Improvement。AlphaZero中MCTS模拟搜索过程相当于Policy Improvement过程,将残差网络的输出动作概率借助MCTS进行提升,最终得到提升后的搜索概率,进行实际走棋。自我对弈最终的获胜者相当于Policy Evaluation过程,得到训练样本,更新残差神经网络,调整输出策略,用于下一步继续Policy Improvement。Policy Evaluation和Policy Improvement不断迭代进行。这个算法借助上述讨论的MCTS和Pytorch构建的残差网络就可快速实现。
运行已有的开源软件
(例如:https://github.com/tensorflow/minigo),看看别人是如何实现的,特别是:
a) 运行代码
MiniGo分布式版本运行需要使用Google Cloud作为存储系统。目前由于无法申请google cloud以及需要翻墙等原因,因此只能使用本地文件系统存储。相应的运行方法和github上给出的略微有些出路。现记录个人实践步骤:(python3.6)
首先git clone下载代码 git clone git@github.com:tensorflow/minigo.git
创建Python虚拟环境
- 安装virtualenv、virtualenvwrapper:
pip install virtualenv; pip install virtualenvwrapper - 创建虚拟环境:cd minigo;
virtualenv minigo_env(python虚拟环境放在工程文件夹下) - 激活虚拟环境:
source minigo_env/bin/activate
- 安装virtualenv、virtualenvwrapper:
安装项目依赖
pip install -r requirements.txt- Tensorflow: CPU:
pip install "tensorflow>=1.5,<1.6"; GPU:pip3 install "tensorflow-gpu>=1.5,<1.6"
设置环境
PROJECT=foo-projectsource cluster/common.sh
运行单元测试
BOARD_SIZE=9 python3 -m unittest discover tests
运行代码
设置中间数据存储文件夹名称:
export BUCKET_NAME=minigo_bucket;Google Cloud作为存储系统
安装google cloud SDK,官网可以下载到安装包,然后运行。之后命令行才能使用gcloud命令。
登录认证:
gcloud auth application-default login --no-launch-browser, 此时会打开网页,输入用户名密码登录后,会得到一个认证code,将此认证code复制到终端运行。但是此时报错了,原因一者是没有google cloud账号,另一个原因是需要翻墙。错误信息如下:1
2
3ERROR: There was a problem with web authentication.
ERROR: (gcloud.auth.application-default.login) Could not reach the login server. A potential cause of this could be because you are behind a proxy. Please set the environment variables HTTPS_PROXY and HTTP_PROXY to the address of the proxy in the format "protocol://address:port" (without quotes) and try again.
Example: HTTPS_PROXY=https://192.168.0.1:8080若能登录成功:后续步骤可以查看远程云盘的文件列表:
gsutil ls gs://$BUCKET_NAME/models | tail -3; 然后可以将远程模型文件下载到本地文件夹中:首先设置并建立模型存储的本地文件夹所在位置:MINIGO_MODELS=$HOME/minigo-models;mkdir -p $MINIGO_MODELS;然后复制远程文件到本地,gsutil ls gs://$BUCKET_NAME/models | tail -3 | xargs -I{} gsutil cp "{}" $MINIGO_MODELS。上述下载完模型文件后,AlphaGo Zero就可以进行自我对弈或和人类对弈。首先设置MCTS模拟次数:
export READOUTS=400。其中自我对弈,运行:
python rl_loop.py selfplay --readouts=$READOUTS -v 2。和人类对弈,运行:
LATEST_MODEL=$(ls -d $MINIGO_MODELS/* | tail -1 | cut -f 1 -d '.')BOARD_SIZE=19 python3 main.py gtp -l $LATEST_MODEL -r $READOUTS -v 3即先查找最新的模型,然后再使用围棋gtp协议进行人机对决。(gtp协议简单来说是以命令方式来传递坐标位置、贴目数等,开发者不需要关注图形界面,图形端由第三方库负责,例如pygtp。)
本地文件作为存储系统
上述google cloud作为存储系统,目前还无法进行实践。故使用本地文件作为存储系统。下面是具体的训练流程。
在下述步骤之前,首先修改rl-loop.py文件的第31行代码,使用本地文件系统。
1
2
3BASE_DIR = "gs://{}".format(BUCKET_NAME)
改成
BASE_DIR = "{}".format(BUCKET_NAME)首先同样需要设置下变量,
export BUCKET_NAME=minigo_bucket; export MODEL_NAME=000000-bootstrapBootstrap:随机初始化神经网络模型:
python main.py bootstrap $BUCKET_NAME/models/$MODEL_NAME初始化完会在本地文件夹
$BUCKET_NAME/models/$MODEL_NAME中出现4个文件。Self-play:利用上述神经网络进行自我对弈,产生棋局数据。
1
2
3
4
5python main.py selfplay $BUCKET_NAME/models/$MODEL_NAME \
--readouts 10 \
-v 3 \
--output-dir=$BUCKET_NAME/data/selfplay/$MODEL_NAME \
--output-sgf=$BUCKET_NAME/sgf/$MODEL_NAME第一个参数是模型所在文件夹,—readouts是MCTS模拟次数,-v是输出信息程度,>=3每步都打印棋盘。—output-dir保存自我对弈数据,—output-sgf导出围棋sgf格式的数据。对弈完成后,会在上述两个文件夹中产生棋局数据。
Gather:从上述棋局数据构建训练数据。
1
2
3python main.py gather \
--input-directory=$BUCKET_NAME/data/selfplay \
--output-directory=$BUCKET_NAME/data/training_chunks—input-directory是上述产生的对弈数据存储的文件夹; –output-directory是输出的训练数据的存储位置。Gather后输出数据到training_chunks文件夹中。
Training:使用Gather到的数据进行训练。
训练既可以从随机初始化开始:
1
2
3
4python main.py train $BUCKET_NAME/data/training_chunks \
$BUCKET_NAME/models/000001-bootstrap \
--generation-num=1 \
--logdir=path/to/tensorboard/logs第一个参数是训练数据的位置,第二个参数是训练后保存该模型的位置。
也可以从上一轮迭代的模型基础上继续训练:增加–load-file参数。
1
2
3
4
5python main.py train $BUCKET_NAME/data/training_chunks \
$BUCKET_NAME/models/000001-bootstrap \
--load-file=$BUCKET_NAME/models/000000-bootstrap \
--generation-num=1 \
--logdir=path/to/tensorboard/logs训练时间过久,没有运行到结束。
Validate:验证模型。
1
2python main.py validate $BUCKET_NAME/data/holdout --load-file=$BUCKET_NAME/models/$MODEL_NAME \
--logdir=path/to/tb/logs --num-steps=100第一个参数是验证集的位置,这个是self-play阶段生成的,可以配置自我对弈保留作为验证集的比例大小。第二个参数是要验证的模型所在文件夹位置。验证后会输出损失情况。
b) 分布式的实现方式:如何支持多GPU?如何进行分布式训练?
分布式运行首先是代码中需要考虑并行的数据一致性等问题;其次是分布式运行的方案架构。
代码中的并行
- 总体上:三大并行过程Self-play、Optimize、Evaluate都是可以并行的。其中Self-play产生对局数据,Optimize会收集self-play对局数据并进行训练,Evaluate每隔一段时间评估模型。
- 细节上:self-play对弈:MCTS模拟过程引入Virtual Loss,并行模拟,收集所有到达的叶节点,统一使用残差网络进行评估。此处体现了GPU的用处,具体的GPU运行细节由TensorFlow实现。Optimize、Evaluate过程同样可以使用GPU,GPU都体现在残差神经网络实现中。
分布式架构
代码中支持GPU较容易。配置分布式架构相对麻烦。目前由于没有机器,所以未实践过。但我具体研究了下分布式架构的搭建和运行流程。
总体方案:
Google Cloud Platform + Kubernetes + Docker + Machine Learning Framework+ GPUs
其中,Google Cloud Platform是我们实际的服务器来源,所有的管理工具、容器、应用程序、GPUs都运行在Google Cloud Platform上,以远程命令的方式在Google Cloud上进行操作。Kubernetes是Docker容器管理工具,用于协同、配合和管理多个容器。Docker是一种容器技术,将应用程序的执行文件、命令都打包在一起,运行在宿主机或虚拟机上,有很强的隔离性,能够很方便的部署、迁移应用程序,这也是我们的程序实际部署和运行的地方,一个容器可以只负责一个并行过程的运行。而Machine Learning Framework是我们程序的核心工具,其封装了GPU运行细节,能够支持GPU运行代码。最后GPU通常使用nvidia等。
部署和运行:(详见工程cluster/README.md)
初始设置:安装命令行工具:gcloud、gsutil、kubectl、docker; 确保能够使用Google Container Engine(GKE)并授权部分权限;设置环境变量并生效,
source cluster/common.sh创建并推送Docker镜像文件:执行make命令(见
Makefile),创建Docker镜像并推送到Google Cloud上。具体命令分成CPU模式和GPU模式:1
2
3
4
5
6
7CPU worker:(见Dockerfile)
make cpu-image
make cpu-push
GPU worker:(见Dockerfile.gpu)
make gpu-image
make gpu-pushDockerfile中指定了使用到的python库以及该容器要负责的并行过程(示例是self-play并行过程,因此该Dockerfile指定了
player_wrapper.sh,该文件封装了对main.py中self-play函数的调用命令)。创建Kubernetes集群
首先有几个概念,Node:代表Kubernetes集群运行的宿主物理机或者虚拟机服务器,它为容器提供必要的计算资源如:CPU与内存。Pod:Kubernetes中最底层的抽象则是Pod。一个Pod中可以包含一个或者多个运行的容器,这些容器运行在同一个Node上,并且共享此Node的资源。Container:Docker Container运行在Pod上。
Kubernetes集群首先会初始化Node Pool,指定了哪些宿主物理机可以使用。Jobs任务运行在集群容器上,容器本身运行在Pod中,而Pod又运行在Node中。
1
2
3
4工程提供了3个集群文件,运行下述文件中的一个:
cluster-up-cpu
cluster-up-gpu
cluster-up-gpu-large上述文件执行的目标:
a. 创建Google容器引擎集群,配备一些虚拟机:Create a Google Container Engine cluster with some number of VMsb. 加载认证信息(这一步应该是之前通过gcloud auth登录后,认证信息保存在本地,现在加载即可)。Load its credentials locally.
c. 导入认证信息到kubectl客户端环境。Load those credentials into our kubectl environment, which will let us control the cluster from the command line.
另外,使用gpu的集群还会安装NVIDIA驱动(见
gpu-provision-daemonset.yaml)到每个使用GPUs worker的Node上。现在可以使用
kubectl get nodes查看节点信息。运行Job
github中的配置文件只给出了self-play并行过程的配置文件,其余并行过程(optimize、evaluate)需要自己给出。每个Job都有一个对应的yaml文件,这个配置文件有一个配置项指定了要使用到的容器镜像文件位置。在我们的示例中,运行的是self-play Job,对应的yaml文件是
cpu-player.yaml或gpu-player.yaml, 该文件指定要使用上述创建并推送到Google Cloud上的镜像文件。在集群中启动Workers来运行Self-play Job
1
2deploy-gpu-player.sh 或
deploy-cpu-player.sh上述两个.sh文件里面都指定了要运行的Job所对应的yaml配置文件的位置。
在集群中启动Workers来运行Train Job、Evaluate Job
上述自我对弈一段时间后,就可以运行训练任务;并迭代一定轮次后,运行评估任务。github代码中没有给出具体配置文件,后续可以参照self-play配置文件来配置并运行。
c) 总结
分布式架构的实践需要实际计算资源的支持。整体开发过程如上述所示,首先借助深度学习框架TensorFlow或Pytorch等书写支持GPU的代码,代码中区分开不同的并行过程;然后配置Docker镜像文件,说明依赖的python库以及负责执行的并行过程;接着配置Kubernetes容器管理集群;最后为每个并行Job书写配置文件。当然,这里面有大量的细节,需要在实践中不断发现和纠错。
AlphaZero算法设计与实现
上述开源的MiniGo实践受限因素很多,目前无法实际训练出可用的东西。故个人参考其他代码库,并重新按照论文规范设计算法的类图结构。目前使用和论文相同的残差网络结构,只不过只使用1层残差块,在6*6规格的棋盘上训练四子棋(和五子棋类似,4联珠即可),大概训练3-5小时,得到的AlphaZero Gobang模型在实战中表现很好。和我本人对决,只要机器先手基本都能战胜我。
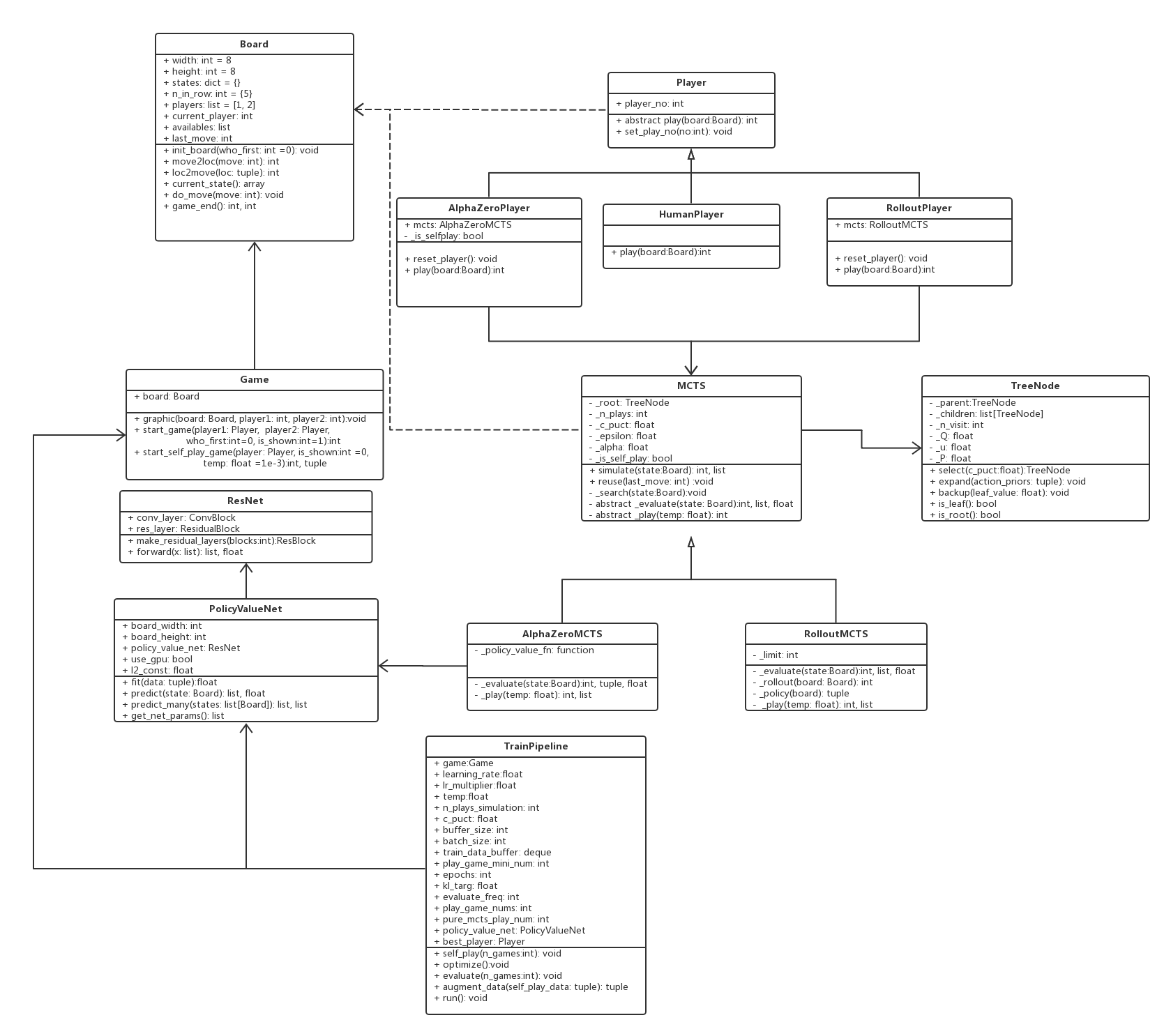
附上AlphaZero算法整体训练结构和设计的类图。
训练整体结构
- Training Pipeline 训练包括三个核心过程:【下述三个过程嵌套在while循环中】
- Self-play 自我对弈产生训练数据
- Initialize Game 初始化游戏
- Play Loop 对弈
- current player get MCTS search probabilities of actions 获取当前玩家下一步动作及对应概率
- Save 保存棋面状态,走棋动作,搜索概率,当前玩家,方便下面构建训练数据
- Do move 走棋,更新棋局状态:交换当前玩家、合法位置、上一步棋、保存{move:player}字典集(用于构建棋面状态数据,需要为双方各自构建feature plane)
- Decide Game End 判断游戏是否结束,获取获胜方
- 若结束,根据上述保存的数据来构建训练数据$(s, \pi, z)$,根据获胜方是否是当前玩家设置相应的$z=1或z=-1$
- 若未结束则继续对弈。
- Augment 增广数据:旋转、翻转【Option可选】
- Optimization 神经网络优化,更新参数(上述自我对弈若干局且达到mini-batch size时进行更新)
- Sample 抽样数据:从上述对弈中随机抽取mini-batch size个数据
- Gradient Descent: 梯度下降, 进行多轮更新。
- Adjust Learning rate 调整学习速率:评估新旧模型,动态调整学习速率(例如可以根据KL散度变化情况调整,或根据损失变化调整)
- Output Loss 输出损失,观察损失变化情况。
- Save best Model: 对比损失,保存最佳模型。【Option可选】
- Evaluator 每隔一段时间,评估当前模型
- Evaluate current model。评估当前模型性能。当前模型和保存的历史最佳模型,或者事先设计好的对比模型进行对决,看看胜率情况。
- Self-play 自我对弈产生训练数据
UML类图设计
UML设计图如下,核心类包括如下几大类:
- Board: 棋盘类,表征棋类游戏棋盘。更一般的话,代表游戏所在场地。对于空间类游戏,Board可代表三维空间。Board承担主要的游戏规则。
- 核心属性包括棋盘规格、当前玩家编号、历史走棋和玩家对应关系、可走棋子集合、上一次走棋等。
- 核心方法包括:初始化棋盘init_board;动作move和位置location的互相转化:move2loc和loc2move;从棋盘构建特征:current_state;走棋更新棋局状态:do_move;判断游戏是否结束game_end。
- Game: 游戏类,表征一局对决。通常是双人游戏。
- 核心属性包括:棋盘board。
- 核心方法包括:渲染棋盘graphic、双方对决start_game、自我对决start_self_play_game。
- Player: 玩家基类。表征玩家。
- 核心属性包括玩家编号。
- 核心方法包括:抽象方法play进行对弈走棋,子类需要重载;设置玩家编号。
- 子类包括:
- AlphaZeroPlayer: 使用AlphaZero算法进行游戏的玩家。核心属性是AlphaZeroMCTS类型的mcts。
- HumanPlayer: 人类玩家,由人类输入实际走棋。
- RolloutPlayer: 使用rollout快速随机走棋进行MCTS搜索的玩家,核心属性是RolloutMCTS类型的mcts。
- MCTS: 蒙特卡罗搜索树。
- 核心属性:树的根节点root、模拟次数n_plays、扩展程度因子c_puct、Dirichlet噪声参数alpha以及所占比例epsilon、是否用于自我对弈is_self_play。
- 核心方法:蒙特卡罗模拟simulate、MCTS搜索树复用reuse、从根节点搜索到叶子节点search、抽象方法evaluate评估叶节点棋面局势、play计算动作概率分布。
- 子类:
- AlphaZeroMCTS: 使用AlphaZero算法中的神经网络指导下的MCTS。
- RolloutMCTS: 快速走棋、随机策略MCTS。
- TreeNode: 蒙特卡罗搜索树节点。
- 核心属性:父节点、子节点、访问次数、Q值、置信上界u、先验概率P。
- 核心方法:MCTS的select、MCTS的expand、MCTS的backup。之所以把MCTS这三个阶段放在这里,主要是因为这三个方法简单、统一,不涉及复杂的算法,每个节点都拥有。当然为了和论文阐述的一致性,这三个方法也可以放在MCTS类中。
- ResNet: 残差神经网络(目前使用Pytorch实现)
- 核心属性包括:卷积层conv_layer(可以包括多个卷积块ConvBlock)、残差层res_layer(可以包括多个残差块ResidualBlock)
- 核心方法:构建多个残差块make_residual_layers、前向传播forward。
- PolicyValueNet: ResNet Wrapper包装类
- 核心属性:policy_value_net : ResNet。
- 核心方法:包括训练方法fit、预测方法predict(用于AlphaZeroMCTS的evaluate阶段)、预测方法predict_many(用于训练时评估模型)、获取模型参数(用于保存模型)
- TrainPipeline: 训练管道。包括上节3个核心的过程。
代码参见我的github仓库:AlphaZero Gobang
其中一局人机对决参见:人机对决