LDA主题模型
LDA(Latent Dirichlet Allocation)是基于贝叶斯模型的,涉及到贝叶斯模型离不开“先验分布”,“数据(似然)”和”后验分布”。在贝叶斯学派这里:P(θ|X)∝P(X|θ)P(θ), 两边取对数,lnP(θ|X)=lnP(X|θ)+lnP(θ), 可以简单理解为:先验分布 + 数据(似然)= 后验分布 。先验分布是我们在观察数据之前对模型的先验知识,通过观察数据之后,我们会对先验模型进行调整优化,使得更加符合真实模型,调整后就得到后验分布。
数据似然是指数据服从的分布,通常是以条件概率密度函数的形式给出。对于先验分布,我们要引出共轭先验的概念。我们考虑增量更新模型的参数。我们的目的是,在不断更新模型的过程中,模型的先验分布形式不会改变。也就是说观察到某个数据,按照贝叶斯公式计算了后验分布,并使得后验分布最大化;在下一次新的数据到来时,前面得到的后验分布能够作为此次更新的先验分布,也就是说先验分布和后验分布的形式应该是一样的,这样的先验分布就叫做共轭先验分布。
二项分布和Beta分布
对于二项分布:
Binom(k|n,p)=(nk)pk(1−p)n−k
这个分布可以理解为,在给定事件出现的概率p和试验的次数n,求该事件出现k次的概率。这里的核心参数是p。n,k可以理解为样本数据,即每次实验n次,观察事件出现的次数k, 得到一个样本。可以对照数据似然理解P(X|θ)。可以通过大量的实验样本和似然估计,来估计p,E[p]=kn。
二项分布的共轭先验是Beta分布,参数p的Beta先验分布如下:
Beta(p|α,β)=Γ(α+β)Γ(α)Γ(β)pα−1(1−p)β−1
仔细观察Beta分布和二项分布,可以发现两者的密度函数很相似,区别仅仅在前面的归一化的阶乘项。另外有,E[p]=αα+β, α、β可以认为是伪计数,α是事件发生的次数,β是事件不发生的次数。注意,这里的参数和正常讲的beta分布的参数不一样,这里的参数p实际上是我们的应用需要求解的参数,而对于beta分布而言,参数实际上是α,β,而p实际上是样本X,即定义域,取值为(0,1)。对于我们的应用,我们需要根据Beta分布来采样样本p(对我们的应用而言, p是参数)。
参数p的后验分布的推导如下:
P(p|n,k,α,β)∝P(k|n,p)P(p|α,β)=P(k|n,p)P(p|α,β)=Binom(k|n,p)Beta(p|α,β)=(nk)pk(1−p)n−k×Γ(α+β)Γ(α)Γ(β)pα−1(1−p)β−1∝pk+α−1(1−p)n−k+β−1
将上式归一化,得到关于参数p的后验概率分布,可以看出服从Beta分布。
P(p|n,k,α,β)=Γ(α+β+n)Γ(α+k)Γ(β+n−k)pk+α−1(1−p)n−k+β−1
两边取对数,则可以概括为:
Beta(p|α,β)+BinomCount(k,n−k)=Beta(p|α+k,β+n−k)
这个后验分布很符合直觉。先验分布基础上,实验了n次,事件发生的次数共为k次,那么相当于现在事件发生的次数为α+k,不发生的次数为β+(n−k).
多项分布与Dirichlet 分布
上述分布都是针对2种类别,因此只需要一个参数p。对于多种类别的情况,就需要将二维拓展到多维。对于二项分布,我们指定了事件的概率p,和发生的次数k。同理,对于多项式分布,我们可以指定不同事件发生的概率,以及各自对应的次数。例如对于三项分布:
multi(m1,m2,m3|n,p1,p2,p3)=n!m1!m2!m3!pm11pm22pm33
这里的参数就是p1,p2,p3, 且p1+p2+p3=1, 2个自由度,使用向量→p来表示。这里的m1,m2,m3,n就是样本,满足m1+m2+m3=n,如果指定了n,则为2个自由度,使用向量→m表示。整个三项分布可以理解为,共实验n次,则事件1出现m1次,事件2出现m2次,事件3出现m3次的概率。可以对照数据似然理解P(X|θ)。多维的多项式分布记做:multi(→m|n,→p)。
多项分布的共轭先验分布是狄利克雷(以下称为Dirichlet )分布。也可以说Beta分布是Dirichlet 分布在二维时的特殊形式。从二维的Beta分布表达式,我们很容易写出三维的Dirichlet分布如下:
Dirichlet(p1,p2,p3|α1,α2,α3)=Γ(α1+α2+α3)Γ(α1)Γ(α2)Γ(α3)pα1−11(p2)α2−1(p3)α3−1
上述就是三维参数向量→p的Dirichlet先验分布形式。
对于多维分布,写作Dirichlet(→p|→α)。
Dirichlet(→p|→α)=Γ(K∑k=1αk)∏Kk=1Γ(αk)K∏k=1pαk−1k
多项分布和Dirichlet分布也满足共轭关系:
Dirichlet(→p|→α)+MultiCount(→m)=Dirichlet(→p|→α+→m)
Dirichlet分布的期望:
E(→p)=(α1K∑k=1αk,α2K∑k=1αk,…,αKK∑k=1αk)
同样,对于通常的Dirichlet分布,其参数是→α, →p实际上是样本X, 定义域为(0,1)。而对于我们的应用而言,→p是要求解的参数(如文档主题的概率分布,后续会看到该参数不需要显示地进行求解,p只是中间产物,用于解释数据生成过程,优化的时候,还是求解→α的贝叶斯估计),我们需要根据Dirichlet分布采样样本→p。
LDA主题模型
我们的问题是, 有M篇文档,对应的第d个文档中有Nd个词。
我们的目标是找到每一篇文档的主题分布和每一个主题中词的分布。在LDA模型中,我们需要先假定一个主题数目K,这样所有的分布就都基于K个主题展开。模型结构如下:
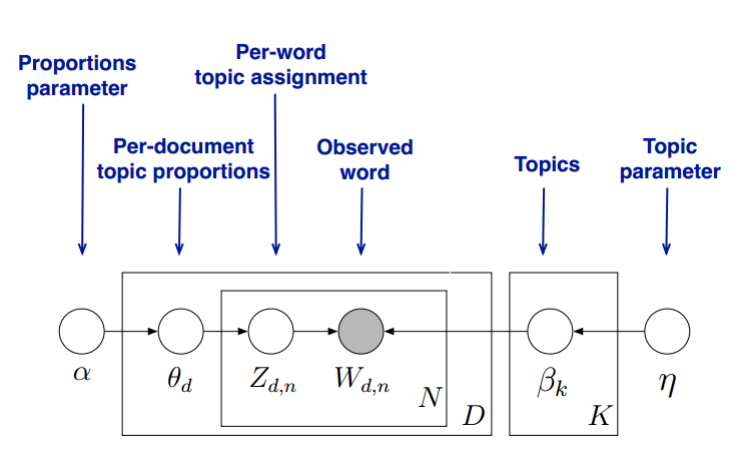
具体的生成数据过程如下:
对于每一篇文档d,重复如下过程:
- 首先确定生成该文档的主题分布(文档-主题分布)。
LDA假设文档主题的先验分布是Dirichlet分布,即对于任一文档d, 其主题分布θd为:
θd=Dirichlet(→α)
其中,α为分布的超参数,是一个K维向量。可以认为是该文档d中K个主题的伪计数。θd对应的是K个主题的概率向量,也就是上文中的→p,是需要根据Dirichlet分布,通过采样采到, 这个参数θd就是数据似然分布(多项式分布)中的参数。每个主题代表1个事件,共K个事件。
对文档d中的第n个词,需要确定生成该词的具体主题编号。
我们从主题分布θd中抽样主题编号zdn的分布为:
zdn=multi(θd)
也就是说,我们得到了该篇文档K个主题中每个主题(所有事件)的概率向量θd, 那么在生成该篇文档某一个词汇的时候,需要先确定具体使用哪一个主题来生成该词汇。可以根据多项式分布 multi(θd)抽样一个主题(1个事件)。
确定构成该主题的词汇分布(主题-词汇分布)。
上述得到了具体某个主题,我们需要确定该主题的词汇分布,主题使用词来刻画。LDA假设主题中词的先验分布也是Dirichlet分布,即对于任一主题k, 其词分布βk为:
βk=Dirichlet(→η)
其中,η为分布的超参数,是一个V维向量。V代表词汇表里所有词的个数,可以认为是表征该主题的所有词的伪计数,每个词代表1个事件,共|V|个事件。同样,根据Dirichlet分布,需要采样表征该主题的每个词的概率向量βk.
确定最终生成的词编号。
对于得到的主题编号,需要确定最终生成哪一个词,该词wdn满足如下多项式分布,βzdn是上述得到的主题zdn不同词的概率分布。
wdn=multi(βzdn)
同样需要根据上述多项式分布,采样一个词(1个事件),作为最终生成的词。
理解LDA主题模型的主要任务就是理解上面的这个模型。
这个模型里,我们有M个文档主题的Dirichlet分布,而对应的数据有M个主题编号的多项分布,这样(α→θd→→zd)就组成了Dirichlet-Multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的文档主题后验分布。
如果在第d个文档中,第k个主题(根据某个词,属于哪种主题权重最大确定)的个数为:n(k)d, 则对应的多项分布的计数可以表示为:
→nd=(n(1)d,n(2)d,…n(K)d)
利用Dirichlet-Multi共轭,得到θd的后验分布为:
Dirichlet(θd|→α+→nd)
同样的道理,对于主题词汇的分布,我们有K个主题词汇的Dirichlet分布,而对应的数据有K个主题编号的多项分布,这样(η→βk→→wk)就组成了Dirichlet-Multi共轭,可以使用前面提到的贝叶斯推断的方法得到基于Dirichlet分布的主题词的后验分布。
如果在第k个主题中,第v个词的个数为:n(v)k, 则对应的多项分布的计数可以表示为:
→nk=(n(1)k,n(2)k,…n(V)k)
利用Dirichlet-Multi共轭,得到βk的后验分布为:
Dirichlet(βk|→η+→nk)
由于主题产生词不依赖具体某一个文档,因此文档主题分布和主题词分布是独立的。理解了上面这M+K组Dirichlet-Multi共轭,就理解了LDA的基本原理了。总结起来,每篇文档的主题分布是各自独立的,M篇文档就有M个文档主题分布; 而主题的词汇分布是所有文档共享的,假设有K个主题,则主题的词汇分布就有K个。
算法求解
现在的问题是,基于这个LDA模型如何求解我们想要的每一篇文档的主题分布和每一个主题中词的分布呢?
一般有两种方法,第一种是基于Gibbs采样算法求解,第二种是基于变分推断EM算法求解。
问题的关键在于主题→z是未知的,无法确定某一个词所属的主题,也就无法确定一篇文档当中不同主题的计数情况,即文档的主题分布,也无法得到主题的词分布。因此问题的关键在于如何确定一个词所属的主题,即p(zi|wt),即主题与词的对应关系。
Gibbs采样
Gibbs采样的核心是求解某个词所属的主题的条件概率。为了求解该条件概率,可以考虑从词和主题的联合概率p(→w,→z)入手,假如该联合概率已知,则条件概率的求解很容易,除以常数p(w)即可。
更进一步,我们要求解的条件概率是某一个词wi所属的主题分布zi,即:p(zi=k|→w,→z¬i), →z¬i代表除wi之外的其它词的主题分布。我们只要能够求解出该主题分布的形式,我们就可以用Gibbs采样依次去采样所有词的主题,当Gibbs采样收敛后,即可得到所有词的采样主题,该主题作为该词的最终所属主题。最后,利用所有采样得到的词和主题的对应关系,我们就可以得到每个文档词主题的分布θd和每个主题中所有词的分布βk,具体而言,根据词和主题的对应关系,统计一篇文档中不同词所属主题的计数,就能计算出该篇文档的主题分布;同样,对于某个主题,统计属于该主题不同词的计数,就能计算出该主题的词分布。
这里忽略具体推导,首先得到除去词wi之外,两个Dirichlet分布的参数在贝叶斯框架下的参数估计:(对参数求积分得到)
ˆθdk=nkd,¬i+αkK∑s=1nsd,¬i+αsˆβkt=ntk,¬i+ηtV∑f=1nfk,¬i+ηf
推导条件概率公式:
p(zi=k|→w,→z¬i)∝p(zi=k,wi=t|→w¬i,→z¬i)=∫p(zi=k,wi=t,→θd,→βk|→w¬i,→z¬i)d→θdd→βk=∫p(zi=k,→θd|→w¬i,→z¬i)p(wi=t,→βk|→w¬i,→z¬i)d→θdd→βk=∫p(zi=k|→θd)p(→θd|→w¬i,→z¬i)p(wi=t|→βk)p(→βk|→w¬i,→z¬i)d→θdd→βk=∫p(zi=k|→θd)Dirichlet(→θd|→nd,¬i+→α)d→θd×∫p(wi=t|→βk)Dirichlet(→βk|→nk,¬i+→η)d→βk=∫θdkDirichlet(→θd|→nd,¬i+→α)d→θd×∫βktDirichlet(→βk|→nk,¬i+→η)d→βk=EDirichlet(θd)(θdk)EDirichlet(βk)(βkt)
推导得到的最终的条件概率公式如下:
p(zi=k|→w,→z¬i)∝EDirichlet(θd)(θdk)×EDirichlet(βk)(βkt)=nkd,¬i+αkK∑s=1nsd,¬i+αs×ntk,¬i+ηtV∑f=1nfk,¬i+ηf
上述公式是求d文档第i个词wi=t的主题zi为k的条件概率。nkd,¬i是文档d中词汇除了wi=t外,属于主题k的次数,αk是文档主题k的Dirichlet先验参数(伪计数)。ntk,¬i是主题k中,除了词汇wi之外,第t个词的次数;ηt是主题词汇t的Dirichlet先验参数(伪计数)。Gibbs采样与初始状态无关,因此α,η合适初始化即可(可能会影响收敛速度)。每次采样更新条件概率后,下一次采样时,nsd,¬i和nfk,¬i都是会变化的,条件概率也都会随之变化,一直到采样稳定。
这个公式很漂亮,右边实际上是p(topic|doc)×p(word|topic),这个概率实际上是doc→topic→word的路径概率,由于Topic有K个,所以Gibbs采样的物理意义就是在K条路径中进行采样。
总结下LDA Gibbs采样算法流程。首先是训练流程:
- 选择合适的主题数K, 选择合适的超参数向量→α、→η
- 对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号z
- 重新扫描语料库,对于每一个词,利用Gibbs采样公式更新它的topic编号,并更新语料库中该词的编号。
- 重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
- 统计语料库中的各个文档各个词的主题,得到文档主题分布θd,统计语料库中各个主题词的分布,得到LDA的主题与词的分布βk。
下面我们再来看看当新文档出现时,如何统计该文档的主题。此时我们的模型已定,也就是LDA的各个主题的词分布βk已经确定,我们需要得到的是该文档的主题分布。
总结下LDA Gibbs采样算法的预测流程:
- 对应当前文档的每一个词,随机的赋予一个主题编号z
- 重新扫描当前文档,对于每一个词,利用Gibbs采样公式更新它的topic编号。
- 重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
- 统计文档中各个词的主题,得到该文档主题分布。
变分推断EM算法
变分推断EM算法希望通过“变分推断(Variational Inference)”和EM算法来得到LDA模型的文档主题分布和主题词分布。首先来看EM算法在这里的使用,我们的模型里面有隐藏变量θ,β,z,模型的参数是α,η。为了求出模型参数和对应的隐藏变量分布,EM算法需要在E步先求出隐藏变量θ,β,z的基于条件概率分布的期望,接着在M步极大化这个期望,得到更新的后验模型参数α,η。
问题是在EM算法的E步,由于θ,β,z的耦合,我们难以求出隐藏变量θ,β,z的条件概率分布,也难以求出对应的期望,需要“变分推断“来帮忙,这里所谓的变分推断,也就是在隐藏变量存在耦合的情况下,我们通过变分假设,即假设所有的隐藏变量都是通过各自的独立分布形成的,这样就去掉了隐藏变量之间的耦合关系。我们用各个独立分布形成的变分分布来模拟近似隐藏变量的条件分布,这样就可以顺利的使用EM算法了。
当进行若干轮的E步和M步的迭代更新之后,我们可以得到合适的近似隐藏变量分布θ,β,z和模型后验参数α,η,进就能够轻易得到我们需要的LDA文档主题分布和主题词汇分布。
要使用EM算法,我们需要求出隐藏变量的条件概率分布如下:
p(θ,β,z|w,α,η)=p(θ,β,z,w|α,η)p(w|α,η)
前面讲到由于θ,β,z之间的耦合,这个条件概率是没法直接求的,但是如果不求它就不能用EM算法了。我们引入变分推断,具体就是引入基于mean field assumption的变分推断,这个推断假设所有的隐藏变量都是通过各自的独立分布形成的,如下图所示:
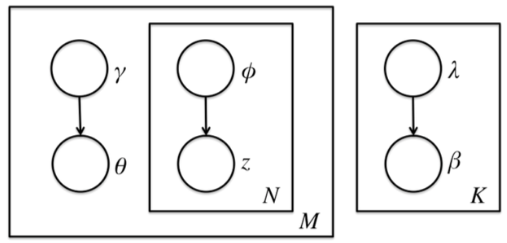
将q(Z)因子化为:
q(Z)=M∏i=1qi(Zi)
我们假设隐藏变量θ是由独立分布γ形成的,隐藏变量z是由独立分布ϕ形成的,隐藏变量β是由独立分布λ形成的。这样我们得到了三个隐藏变量联合的变分分布Q为:
Q(β,z,θ|λ,ϕ,γ)=K∏k=1q(βk|λk)M∏d=1q(θd,zd|γd,ϕd)=K∏k=1q(βk|λk)M∏d=1(q(θd|γd)Nd∏n=1q(zdn|ϕdn))
Mean Field对联合分布做了独立性假设,而没有对单个的q分布做任何假设(传统EM当中,直接假设隐变量的分布形式,转成参数优化)。这里面存在疑惑的一点是,看网上的资料以PLSA和LDA为例总结EM和变分推断,这里对q的形式是有做假设的,即q(βk|λk)和q(θd|γd)是服从Dirichlet分布,和q(zdn|ϕdn)服从多项式分布。这几个因子具体分布也有可能是通过平均场理论推导而来的。
我们希望用变分分布Q来近似p(θ,β,z|w,α,η) , 利用KL散度:
(λ∗,ϕ∗,γ∗)=argmin⏟λ,ϕ,γKL(Q(β,z,θ|λ,ϕ,γ)||p(θ,β,z|w,α,η))
我们的目的就是找到合适的λ∗,ϕ∗,γ∗,然后用Q(β,z,θ|λ∗,ϕ∗,γ∗)来近似隐藏变量的条件分布p(θ,β,z|w,α,η),进而使用EM算法迭代。
推导文档的对数似然如下:
log(w|α,η)=log∫∫∑zp(θ,β,z,w|α,η)dθdβ=log∫∫∑zp(θ,β,z,w|α,η)Q(β,z,θ|λ,ϕ,γ)Q(β,z,θ|λ,ϕ,γ)dθdβ=logEQp(θ,β,z,w|α,η)Q(β,z,θ|λ,ϕ,γ)≥EQlogp(θ,β,z,w|α,η)Q(β,z,θ|λ,ϕ,γ)=EQlogp(θ,β,z,w|α,η)−EQlogQ(β,z,θ|λ,ϕ,γ)=L(λ,ϕ,γ;α,η)
上述用到Jense不等式(推导EM的时候也用到过,不再累赘),这个下界L称为ELBO(Evidence Lower Bound)。为了最大化数据对数似然,我们只需要不断优化下界,使下界不断增大。
换一个角度理解,这个ELBO和我们需要优化的的KL散度关系:
KL(Q(β,z,θ|λ,ϕ,γ)||p(θ,β,z|w,α,η))=EQlogQ(β,z,θ|λ,ϕ,γ)−EQlogp(θ,β,z|w,α,η)=EQlogQ(β,z,θ|λ,ϕ,γ)−EQlogp(θ,β,z,w|α,η)p(w|α,η)=−L(λ,ϕ,γ;α,η)+log(w|α,η)
在上式中,由于对数似然部分和我们的KL散度中要优化的参数无关,可以看做常量,因此我们希望最小化KL散度等价于最大化ELBO。那么我们的变分推断最终等价的转化为要求ELBO的最大值。现在我们开始关注于极大化ELBO并求出极值对应的变分参数λ,ϕ,γ。
先将L展开:
L(λ,ϕ,γ;α,η)=Eq[logp(β|η)]+Eq[logp(z|θ)]+Eq[logp(θ|α)]+Eq[logp(w|z,β)]−Eq[logq(β|λ)]−Eq[logq(z|ϕ)]−Eq[logq(θ|γ)]
上述分解出了7个式子,这7个项可归为2类:狄利克雷分布相对于variational distribution的期望(关于β和θ的,共4个)、多项分布相对于variational distribution的期望(关于z和w的,共3个)。
接下来的问题就是极大化ELBO,来求解变分参数λ,ϕ,γ。目标是如何把L转成只关于λ,ϕ,γ的形式,而不包含β、z、θ,利用指数分布族的性质:
p(x|θ)=h(x)exp(η(θ)∗T(x)−A(θ))ddη(θ)A(θ)=Ep(x|θ)[T(x)]
我们的常见分布比如Gamma分布,Beta分布,Dirichlet分布、多项式分布都是指数分布族。这个性质中,对T(x)的期望转成了对η(θ)的导数。有了这个性质,意味着我们在ELBO里面一大堆包含β、z、θ(服从Dirichlet或多项式分布)的期望表达式可以转化为对目标参数λ、ϕ、γ的导数,这样就都约掉了中间变量β、z、θ。
最后,对ELBO各个参数求偏导,并令导数为0,就可以得到各个参数在E-step的解析解,3个参数的解析解互相依赖,因此要反复迭代,直到该步稳定。另外,该解析解中包含了实际要求的参数α,η,这些参数要在M-step计算。在M-step中,对α,η求导,此时没有解析解,使用梯度下降法或牛顿法迭代求解,直至该步稳定。
E-step:
ϕnk∝exp(V∑i=1win(Ψ(λki)−Ψ(V∑j=1λkj))+Ψ(γk)−Ψ(K∑h=1γh))
γk=αk+N∑n=1ϕnk
λki=ηi+M∑d=1Nd∑n=1ϕdnkwidn
M-step:
αk+1=αk+∇αkL∇αkαjL
ηi+1=ηi+∇ηiL∇ηiηjL
其中, ∇αkL,∇αkαjL分别是α的一阶导数和二阶导数。∇ηiL和∇ηiηjL分别是η的一阶导数和二阶导数。
∇αkL=M(Ψ(K∑i=1αi)−Ψ(αk))+M∑d=1(Ψ(γdk)−Ψ(K∑j=1γdj))∇αkαjL=M(Ψ′(K∑i=1αi)−δ(k,j)Ψ′(αk))∇ηiL=K(Ψ(V∑j=1ηj)−Ψ(ηi))+K∑k=1(Ψ(λki)−Ψ(V∑j=1λkj))∇ηiηjL=K(Ψ′(V∑h=1ηh)−δ(i,j)Ψ′(ηi))
其中,当且仅当i=j时,δ(i,j)=1,否则δ(i,j)=0。
总结该算法步骤:
输入:主题数K,M个文档与对应的词。
1) 初始化α,η向量。
2)开始EM算法迭代循环直到收敛。
a) 初始化所有的ϕ,γ,λ,进行LDA的E步迭代循环,直到λ,ϕ,γ收敛。
(i) for d from 1 to M:
for n from 1 to Nd:
for k from 1 to K:
更新ϕnk。
标准化ϕnk使该向量各项的和为1。
更新γk。
(ii) for k from 1 to K:
for i from 1 to V:
更新λki。
(iii)如果ϕ,γ,λ均已收敛,则跳出a)步,否则回到(i)步。
b) 进行LDA的M步迭代循环, 直到α,η收敛。
(i) 用牛顿法迭代更新α,η直到收敛。
c) 如果所有的参数均收敛,则算法结束,否则回到第2)步。
算法结束后,我们可以得到模型的后验参数α,η以及我们需要的近似模型主题词汇分布λ, 以及近似训练文档主题分布γ。
λki是语料层面的参数,每遍历一遍全量的训练文档只需要更新一次;γk 和 ϕnk 是文档层面的参数,每“见到”一篇文档都会对该文档对应的参数进行优化。
若是要对一篇新文档的主题分布作推断,只需要执行 γk 和 ϕnk的更新部分。
上述只是一种极大化ELBO的方法,还有其他方法可以参见变分推断与LDA。
引用
LDA数学八卦

