这篇文章是观看李宏毅老师Youtube上的GAN教学视频的笔记,主要涉及到对GAN的理解。
Introduction
Basic Idea
生成对抗网络(GAN,Generative Adversarial Network)是一种生成模型,由Generator和Discriminator构成。首先需要明确,虽然GAN是一种生成模型,理论上能针对特定的领域生成任何东西。但是随机生成不是我们想要的(即使生成的东西很逼真)。重要的是,我们能够控制生成control what to generate,这也是生成的意义所在。这种方式的生成,我们称作Conditional Generation。
Generator:实际上是一个neural network or a function。input: vector -> Generator -> output: image(matrix)
其中,input向量每个维度代表了某些特定的特征。比如第一维数值代表头发的长短;第二维数值代表头发的颜色;第三维代表嘴巴张开还是闭合。output的图像,实际就是Generator最后一层隐藏层输出的高维向量(reshape一下就成matrix)。
Discriminator:实际上也是一个neural network or function。input: image -> Discriminator -> scalar。
其中,output数值越大代表输入的图像越真实,越小代表输入的图像越假。
Adversarial的理解:多种多样的方式。
适者生存:Generator像是一种普通的生物(e.g., 枯叶蝶),Discriminator是Generator的天敌(e.g., 鸟)。Generator为了生存,不能轻易被天敌发现,故在自然选择的条件下,不断进化(e.g, 自身颜色变化),使得自己外表有更好的隐蔽性,能够迷惑天敌。Discriminator同样需要生存(e.g., 捕食),需要不断进化。使得自己有更好的辨别目标的能力。
作为类比,为了Fool Discriminator,Generator不断进化,生成更加真实的fake image。这些fake image作为Discriminator的输入,Discriminator要能识别出这些输入是fake的,不管Generator生成的多真实。
名师出高徒:Generator像是学生,Discriminator像是老师,我们希望学生不断进步。学生一年级时,画画较差,画的图没有眼睛,一年级老师不满意;到二年级时,该学生学会画眼睛,但是没有画嘴巴,二年级的老师更严格,也不满意。随着年级的增长,在老师的指导下,学生的能力不断增强,画画越来越好。
可以说,Discriminator leads the Generator。Discriminator有大局观,会懂得鉴赏,而不会亲手动笔画;而Generator会一笔一画,落到细处,但缺少大局观。
GAN:Generative Adversarial Network。从名称上,不言而喻,目的是希望得到一个生成网络。为了能够很好的生成目标对象,例如,image/sentence等,引入了对抗(adversarial)学习的概念,使用Discriminator承担对抗的任务,引导着Generator不断学习和进步。Discriminator体现着top-down的思想,能够从全局上对一个完整的输入图片进行真假判断,但自己生成目标对象较困难(穷举);Generator体现着bottom-up的思想,从细粒度的组成单元(pixel/word)的级别,one-by-one的生成目标对象(image/sentence),但是无法把握组成单元之间的依赖关系(pixel之间,word之间,实际上是结构化预测的核心问题),没有大局观。二者结合,迭代学习,能够发挥二者的长处,同时互相弥补二者的短处。
Question
1. When can I use GAN ?
结构化学习(Structured Learning):是machine learning中有别于分类/回归之外的另外一种问题。主要区别在于其输出的是结构化的对象,如序列,矩阵,图,树等,且结构化输出每个components之间是存在依赖关系的。
常见的结构化学习问题包括:Seq2Seq机器翻译(输出序列)、Image to Image图像变换/上色(输出矩阵)、Text to Image/Image to Text图像描述(输出矩阵或序列)、连续决策或控制(输出是决策序列)。关键点在于,上述结构化学习的输出的组成成分之间是有明显的依赖关系的(例如句子中word-by- word关系,图像中pixel-by-pixel关系,决策中action-by-action关系)。
结构化学习的难点还在于,输出空间是巨大无比的,如果把每个可能的输出都看做一个类别的话,大部分类别缺乏足够的训练样本,因此在测试的阶段,模型需要具备创造能力/泛化能力,这种问题实际上就是one-shot/zero-shot learning的体现。其次,结构化学习需要模型学会计划。也就是说,模型可以按照component-by-component的方式来生成目标对象,但是需要模型在脑海里有一个大局观在指导。因为components之间有很强的依赖关系,需要全局的进行考虑(比如说,前一个是主语类型的单词,接下来生成的更可能是谓语类型的单词,这是大局观)。
GAN是一种用于做Structured Learning的具体方法。其中,Generator能够在component-level来component-by-component的生成目标对象(Bottom Up);Discriminator能够学会计划,从全局上评估整个目标对象(Top Down),不断引导(Leads)Generator的学习。
因此回到问题本身,GAN可以用于做结构化学习。
2. Why Generator cannot learn by itself ?
Generator的任务是给定输入向量(我们称之为code,通常是低维的),生成目标对象,如图片,句子等(高维向量)。这里有了输入输出pair,实际上就变成了回归问题。我们知道,输出就是具体的目标对象,如图片/句子。因此,这里的关键是输入code如何选取?code的每一维实际上都隐含着描述目标对象的特征信息。如果为每个目标对象随机地选择code,那么训练就会存在很大的困难。因为,可能两个目标对象很像,但是随机生成的code差异很大,这样的话,想让网络生成很像的两个目标对象是比较困难的。我们希望,两个code比较相似的时候,生成的两个目标对象也有很多相似之处。这个问题可以借助Auto-Encoder或Variation Auto-Encoder,通过最小化重构误差,学习目标对象的低维表示。顺便提一下,Auto-Encoder的假设是,即使目标对象的向量维度数是很高的,但是实际上存在一个低维的表示就能够很好的描述它(流形假设)。
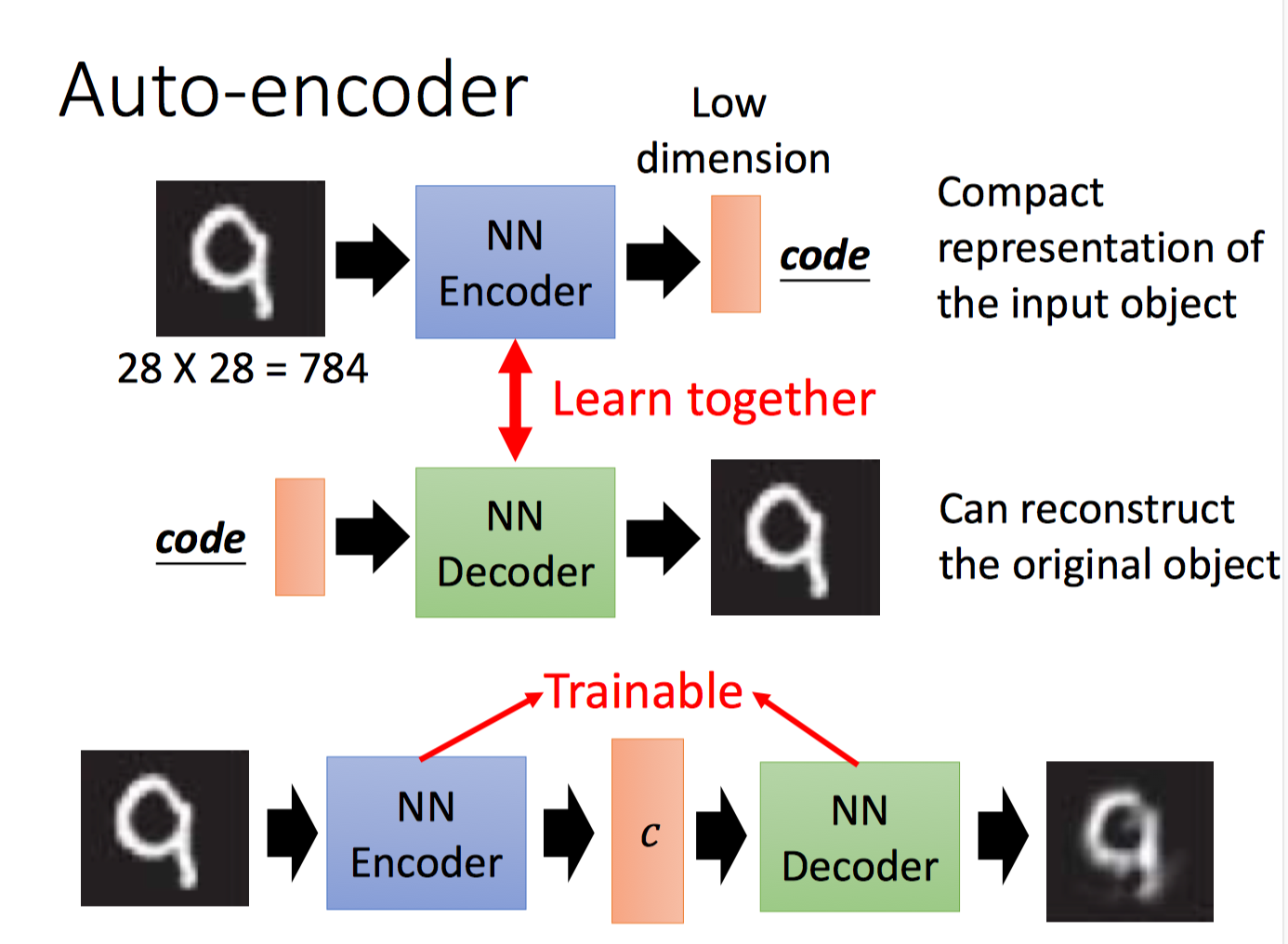
目标对象经过NN Encoder提取到的$c$就是此处的code。而Code -> Decoder -> Image这三部分就可以看做是一个generator。
但问题在于,NN Decoder输出的时候,没有考虑目标对象组成单元之间的依赖关系(虽然这种依赖关系可以通过多层网络间接考虑到,但是还是比较弱)。这会导致诸多问题,例如,不同生成的图片和实际的目标图片同样是相差1个像素点,但是重要性却不同,有些像素点缺少无所谓,有些像素点却不能缺少。比如下图:
![]()
第一幅图多了个像素点,第二幅图少了个像素点,影响都非常大;第三幅和第四幅尽管相差了6个像素点的误差,但是仍然影响不大。像素直接的依赖关系非常重要,对于第一幅图,我们不是说一定不能够多出图中的那个像素点,但关键是没有考虑该像素点周围的像素点的影响,如果改成下图,把多出来的那个像素点周围的像素点都填充了,那么也OK。
![]()
也就是说,像素点之间的关系是非常重要的。但是,generator最后一层是独立地生成各个像素点,无法从全局上把握不同像素点的依赖关系(虽然通过深度网络架构能够在一定程度上间接捕捉依赖关系,但仍然不够)。因此,回到问题本身,这也是不能单独使用generator进行自我学习且期望生成较高质量的目标对象的原因。
3. Why discriminator don’t generate object itself ?
Discriminator又称作Evaluation Function或Potential Function,是一个函数,将高维输入对象映射成一个scalar值,该数值代表了输入对象“多好”。Discriminator的好处在于能够以top-down全局的评估方式来考察componets之间的依赖关系。例如以上文的例子为例,使用下述右侧的1个CNN filter,如果提取到了游离像素点特征,那么就能够很方便的从全局上分析该输入不是2(左侧第一个2)。
![]()
那么Discriminator既然这么会分析输入对象的好坏,那么能否用于生成呢?答案是可以。
假设我们已经有个一个足够好的Discriminator $D(\boldsymbol{x})$,那么生成目标对象$\tilde{x}$的任务为:
$$
\tilde{\boldsymbol{x}} = \arg \max_{\boldsymbol{x} \in \boldsymbol{X}} D(\boldsymbol{x})
$$
上述任务就是穷举所有可能的$\boldsymbol{x}$,选出模型认为好的作为生成的目标对象。
关键问题转成了如何训练处一个足够好的Discriminator以及如何求$\arg \max$。
对于第一个问题,Discriminator实际上就是一个二分类判别模型,因此需要正样本和负样本。其中,正样本由我们的数据集提供,我们需要考虑负样本的生成。负样本是问题的关键所在,那我们应该如何生成realistic negative examples呢?我们可以采取迭代学习的方式来训练判别模型,每轮迭代完,使用判别模型本身来产生negative examples,再接着下一轮迭代。使用Discriminator来解Generation问题的通用算法如下:

首先给定正样本以及随机抽取的负样本,训练模型来最大化区分正负样本(如二分类交叉熵损失);接着使用上一轮训练好的模型通过解$\arg \max$生成负样本,然后作为下一轮训练的输入。
学习的过程可以使用下述图来形象刻画:
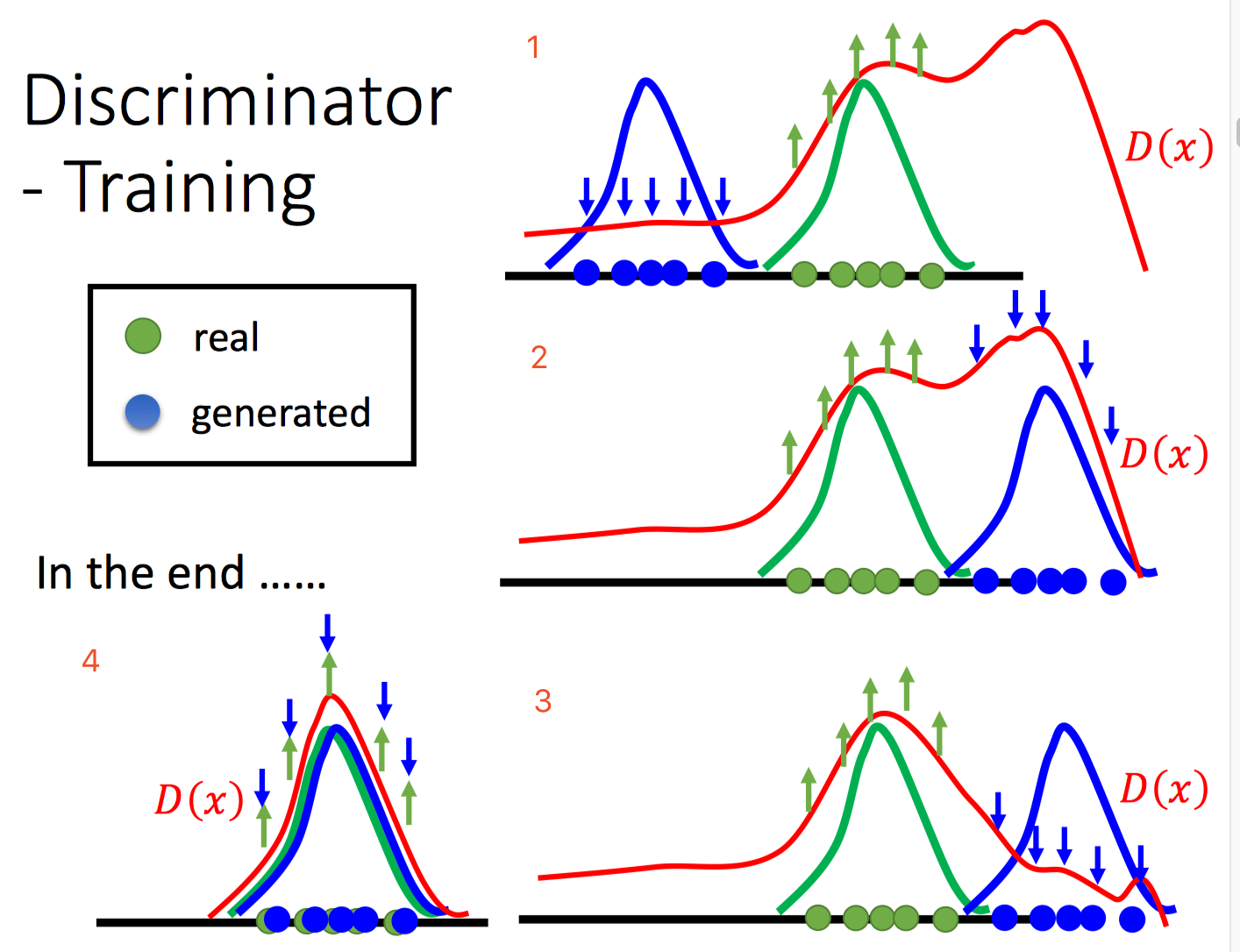
上述假设输入$\boldsymbol{x}$是一维的。1图中,假设最开始正样本是绿色球区域,随机抽取的负样本是蓝色球区域,第一轮迭代完,$D(x)$曲线在绿色样本区域预测得分高,在蓝色样本区域预测得分低,但是在最右侧大部分区域,模型还不得而知是该预测得分高还是低,图中可以看出右侧还有更高得分区域(实际上除了绿色球区域,其他区域都是负样本,得分都应该低,但是目前来看右侧高了,说明模型存在弱点);第二轮迭代前,通过求解arg max(通常通过采样来近似求解,如Gibbs Sampling)生成了目前模型认为高置信的样本(模型当前弱点所在)作为负样本,也就是图2中右侧蓝色球部分,第二轮迭代后,如图3所示,$D(x)$曲线在右侧区域得分值降低,也就是说纠错了当前的弱点。一直不断迭代,不断纠错后,最终模型采样的结果和真实的样本会非常接近,如图4所示。因此,$D(x)$本身学习到了数据某种潜在的分布,可以通过采样等方式,泛化到未知的数据上。实际上,很多结构化学习/无监督学习都是采用这种方式进行生成学习的,其学习后的模型本身是可以用于生成新样本的,也就是说学习到数据潜在的真实分布。
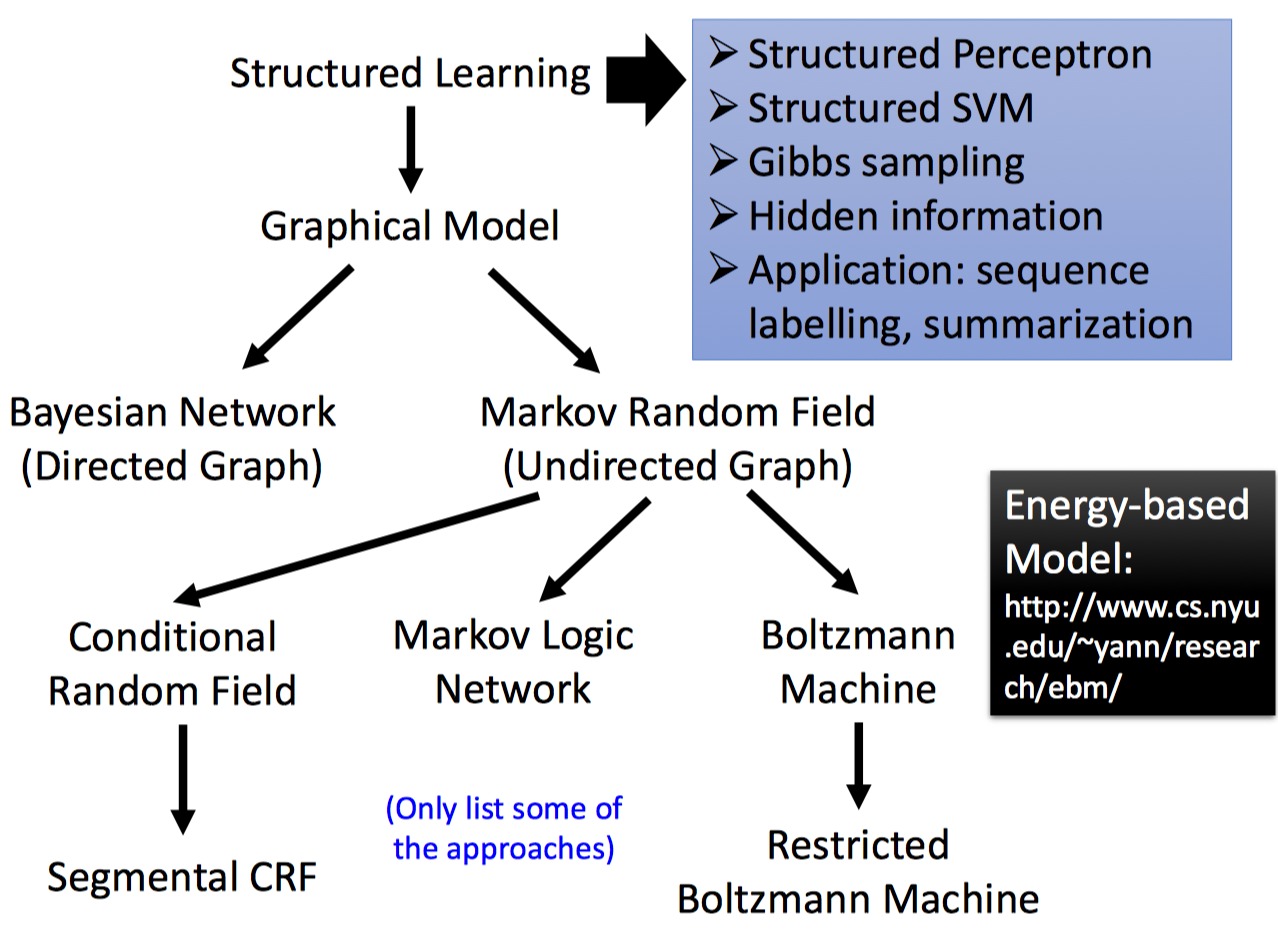
如上图,我们熟悉的很多图模型都是根据上述方式进行学习的,即不断根据$\arg \max$进行负采样,来纠错并更新模型,提高模型的生成能力,只不过有的模型$\arg \max$可以显示精确求解,有的模型$\arg \max$需要使用Gibbs采样等方式近似求解。例如,RBM只使用无标签的样本本身进行无监督学习,使用基于能量的方式来构建似然损失,每步迭代时,都需要RBM模型本身进行负采样(Gibbs Sampling),并进行模型参数的学习。在CRF中 ,当要预测给定输入序列的标签序列时,需要求解$\arg \max$,即给定$X$,求似然(X和Y联合概率)最大的$Y$,$\arg \max\limits_{Y} P(Y,X)$(等价于$P(Y|X)$最大,使用维特比算法或Beam-Search近似算法;注意CRF训练时不需要求argmax,因为是监督学习,用了下一时刻真实的标签y即可)。
Discriminator生成目标对象的问题在于复杂度较高,需要求解$\arg \max$问题。
总结一下:
- Generator
- 优点:容易生成结构化对象
- 缺点:容易模仿/拷贝输入,过拟合;难以学习components之间的依赖关系。
- Discriminator
- 优点:从全局上考虑和计划。
- 缺点:生成结构化对象较困难,尤其是模型很深的时候;负采样是关键,有的模型难以采样。
4. How discriminator and generator interact ?
集大成,取长补短。使用Generator进行负采样,产生负样本;使用Discriminator根据真实样本和产生的负样本进行学习,从全局上把握components之间的关系,指导Generator不断进化,生成更逼真的目标对象。
关键:也就是说除了min-max博弈方式来通俗的理解GANs之外,也能够按照上述方式理解,即:Generator是Discriminator的负采样器,功能上等价于arg max discriminator;Discriminator通过区分负采样的样本和真实样本,来不断提升Generator的负采样能力,直到负样本和真实样本几乎服从于同一个分布为止!此时,Generator能够用于生成新样本!!
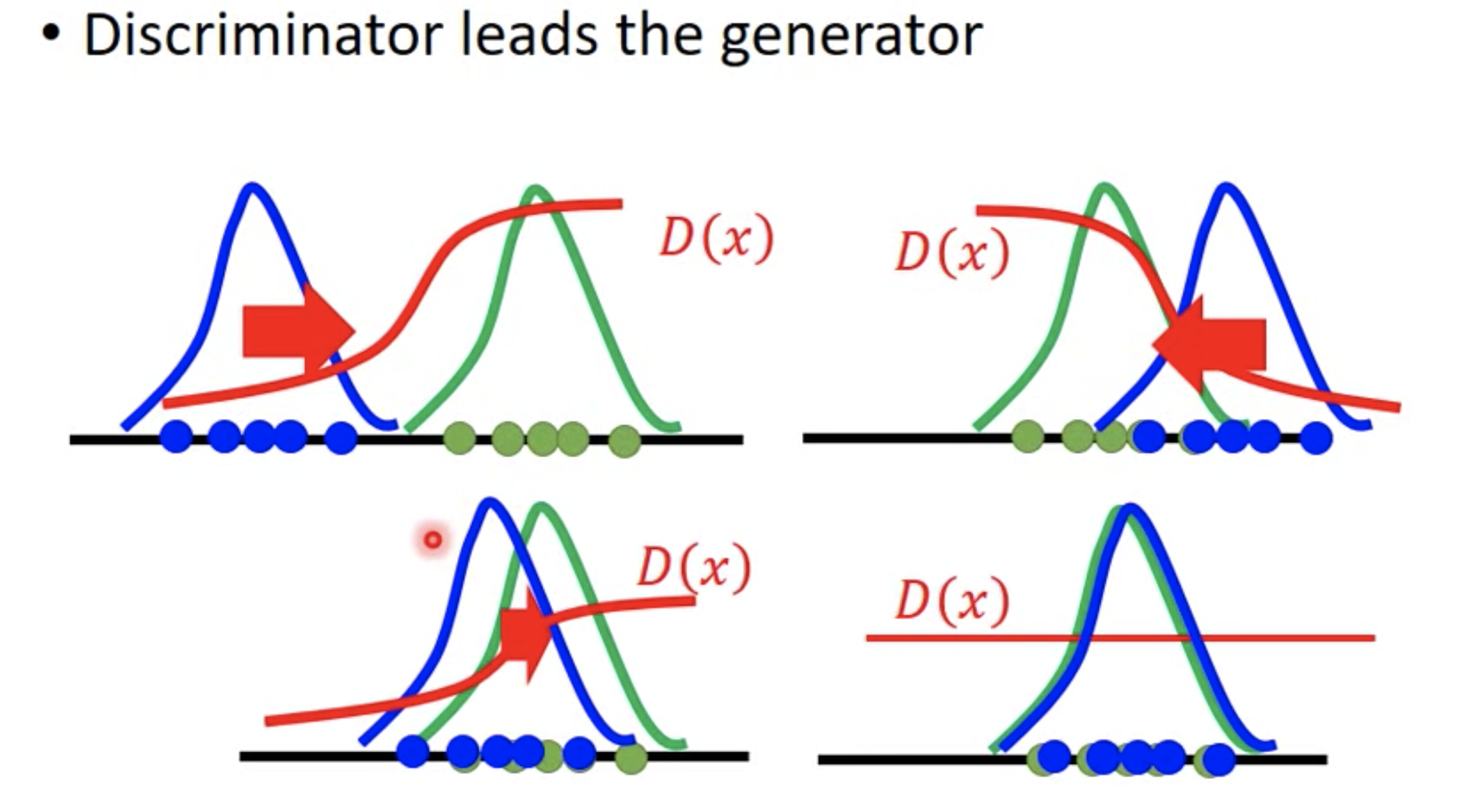
上图是两侧非真实样本所在区域的fake样本(D(x)很低),在Discriminator的指导下,都不断往真实的样本所在的区域靠(D(x)很高)。最终,Generator输出的Fake样本和Real样本几乎重叠,D(x)无法区分是真实样本还是假样本。
学习算法统一起来,如下:
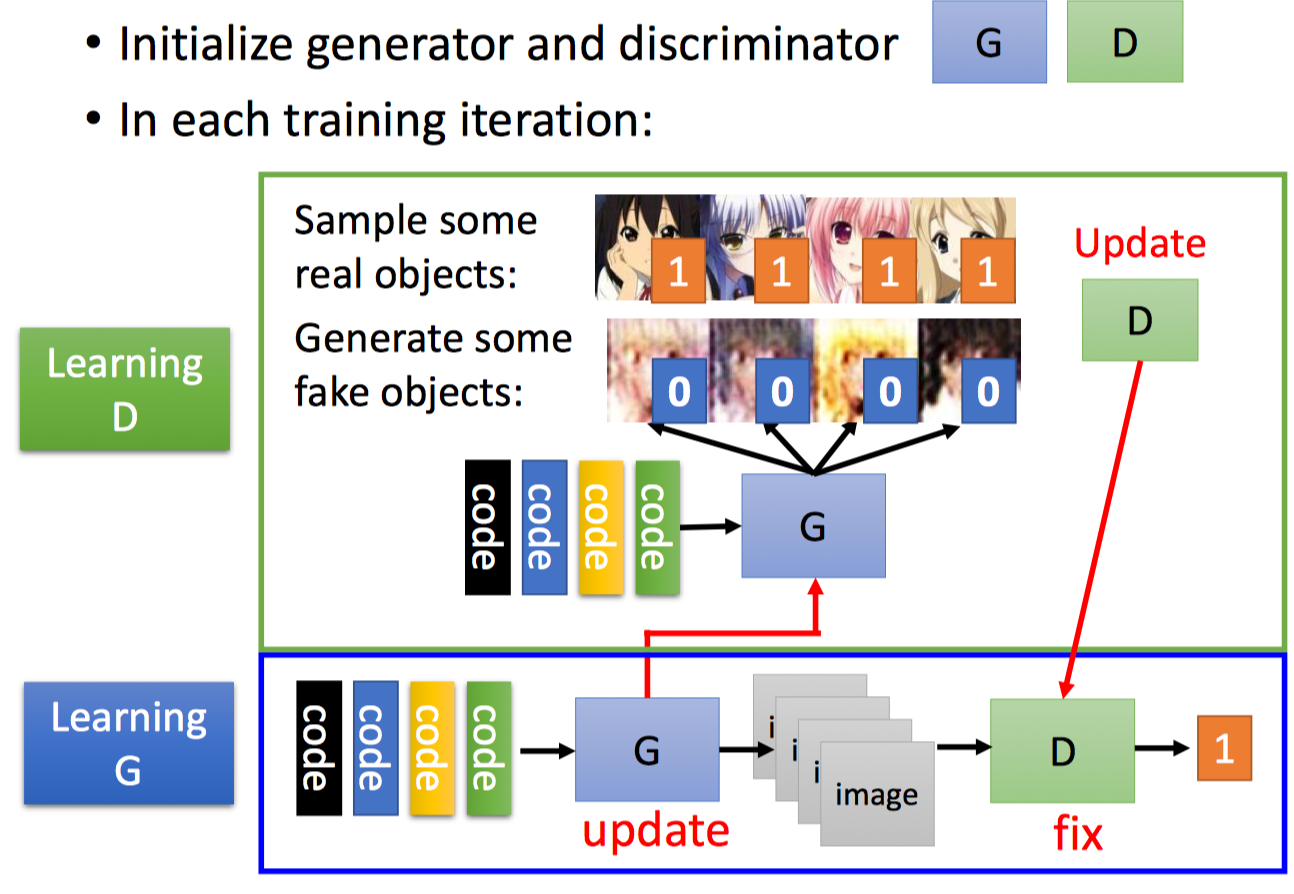
每次迭代,
- Learning D: 更新Discriminator,固定Generator。使用Generator生成fake objects(即Generator Layer的的输出),更新Discriminator参数,最大化real objects的得分值,最小化fake objects的得分值。
- Learning G: 更新Generator,固定Discriminator。最大化Generator生成的fake objects的得分值(由后面固定的Discriminator Layer打分的)。学习时,对Generator进行Gradient Ascent,即:固定住最后的Discriminator Layer,学习前面的Generator Layer)。
演算法如下:

GAN的好处在于:
From Discriminator’point of view
- Using generator to generate negative samples
$$
\underbrace{G \rightarrow \tilde{x}}_{\text{efficient}} \leftrightarrow \underbrace{\tilde{x}=\arg \max_{x \in X} D(x)}_{\text{complicated}}
$$
- Using generator to generate negative samples
- From Generator’s point of view
- Still generate the object component-by-component.
- But it is learned from the discriminator with global view.
Conditional GAN
前面我们喂给Generator的输入都是随机的噪声,这样产生的都是随机的东西。而在Conditional GAN当中,我们不仅要喂给Generator随机的噪声,还要喂Conditions,这样产生的东西是基于输入的条件的。比如Caption Generation,给定输入条件为图片,输出文字描述;Chat-bot中,给定输入条件是问题,输出回答;Image Generation中,给定输入条件是文字描述,输出图片;Video Generation中,给定输入条件是前几帧的画面,输出是下一帧的画面。此时,这些输出连同conditions作为Discriminator的输入,Discriminator判断时,不仅要判断输入的stuff是否逼真,同时还要判断输入的stuff是否和conditions相匹配。
Supervised Conditional GAN
有监督条件GAN是指用于训练的数据集中,包含了real stuff和其对应的condition,记做,$(c^{i}, x^{i})$,$c^{i}$是condition,$x^{i}$是real stuff。
首先训练Discriminator,固定Generator。Discriminator的学习目标不仅是判断输入图像是否真实,还要判断输入的stuff和condition相匹配。condition给定的前提下,前者的学习的目标是最小化(fake stuff, condition)得分;后者的学习目标是,最小化(not matched real stuff, condition)的得分,前后者共同的学习目标是,最大化(real stuff, condition)得分。具体而言,
前者根据最小化generator生成的样本$\tilde{x}^{i}$的得分$D(c^i, \tilde{x}^i)$,后者从数据集中真实的样本随机抽样部分样本$\hat{x}^{i}$,作为和condition不匹配的样本,最小化$\hat{x}^{i}$的得分$D(c^{i}, \hat{x}^i)$;二者共同目标是,最大化数据集中该condition对应的真实样本$x^{i}$的得分$D(c^i, x^i)$进行学习。
接着训练Generator,固定最后几层的Discriminator。目标是最大化Generator输出的得分(Discriminator打分的)。Generator输入是(noise, condition) pair(noise的含义见下文理论部分),输出是fake stuff,$G(c^i, z^i)$。
演算法如下:

Unsupervised Conditional GAN
前面有监督条件GAN使用的训练集是(real stuff, condition) pairs,二者是一一对应的。无监督条件GAN使用的训练集,real stuff和condition不是一一对应的。相反,使用的数据集是x domain(conditions)和y domain(real stuffs)两个分开的集合,没有对应关系。希望实现由x domain直接转成y domain。例如,图像风格转换,x domain是原始图,y domain是梵高的图,训练集中只包含一堆原始图,一堆梵高的图作,二者没有对应关系,目标是将原始图转成梵高的画作风格,例如将日月潭转成梵高的图,显然日月潭和梵高画作不能对应,因为梵高没有画过日月潭,但我们希望模型能够将原始日月潭渲染成梵高的画作风格类型。
学习时要考虑两个因素,x domain通过Generator转化成的fake y domain能够符合y domain,使用Discriminator来判断是否符合y domain;还要考虑约束fake y domain必须和输入x domain存在一定的相似性,否则fake y domain每次都输出固定的某张y domain,完全无视input x domain的话,Discriminator会认为fake y domain很逼真,但是完全没达到我们的目的,因为fake y domain和输入x domain完全不相关了。
因此,有大量的研究工作是针对如何使得fake y domain和x domain产生关联,即依赖于条件x domain的条件生成模型。
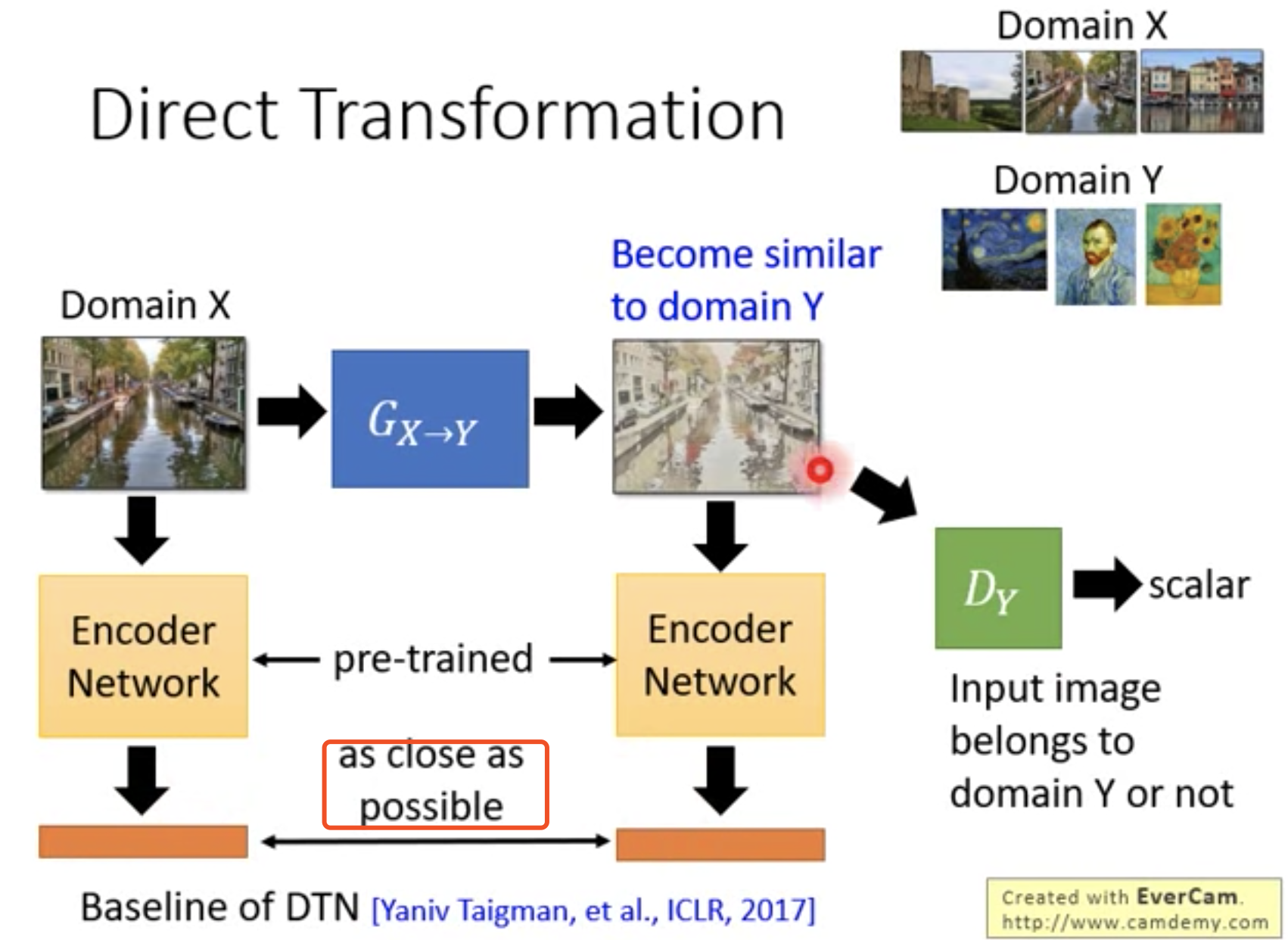
Direct Transformation
添加输入x domain stuff和输出fake y domain stuff之间的相似性约束。
最粗暴的方法,不考虑相似性约束,但必须保证Generator的网络是Shallow的,这样不会改变太多,间接的达到x domain stuff和fake y domain stuff相似的目的。
DTN
x Domain 和 Generator生成的 fake y domain 都经过Encoder Network提取特征后,约束二者之间的相似性。
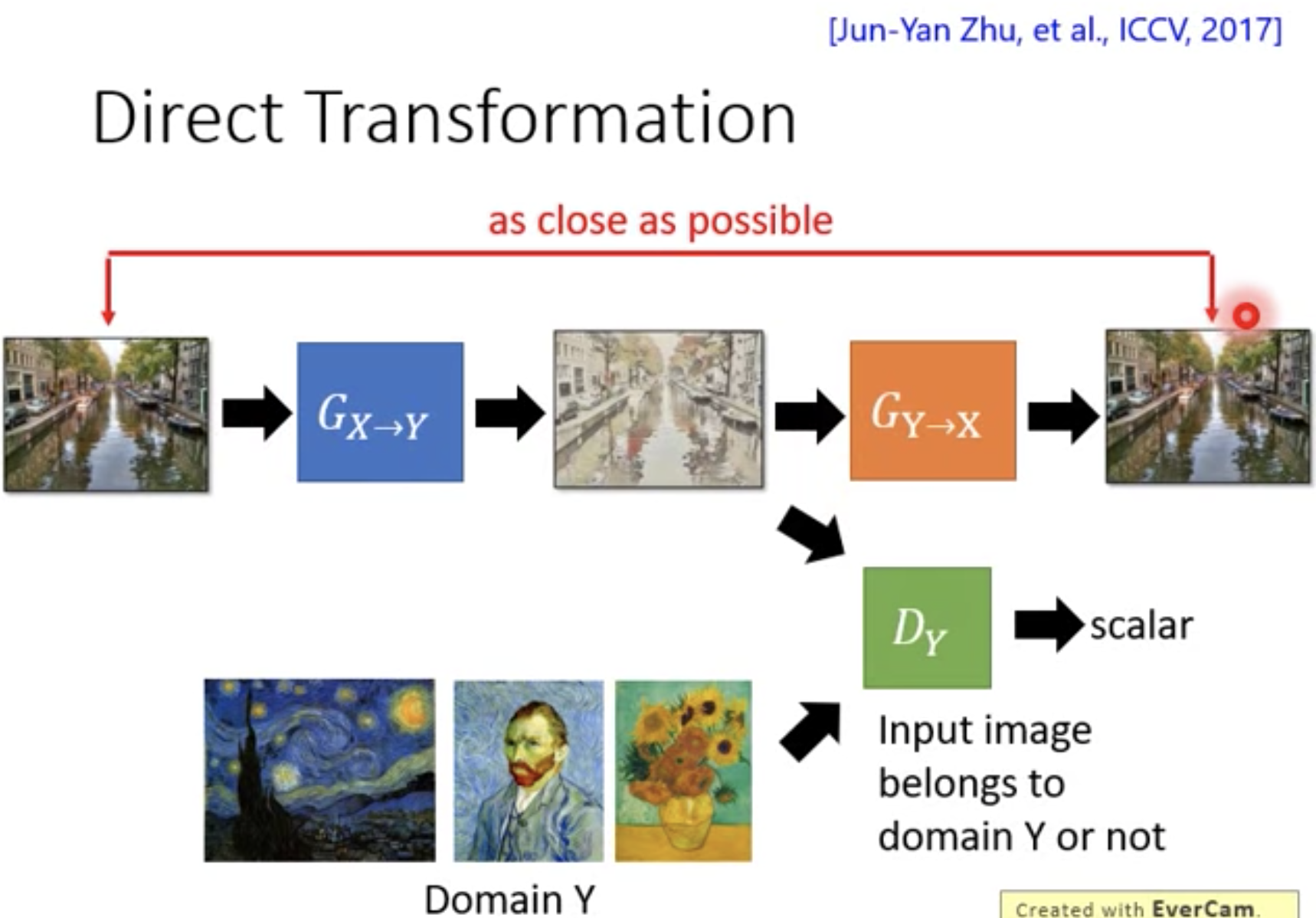
Cycle GAN
添加俩Generator,正反向,domain x -> fake y domain -> recovered domain x。反向恢复后的domain x和原始的domain x越近越好(cycle consistency loss)。
double cycle gan:
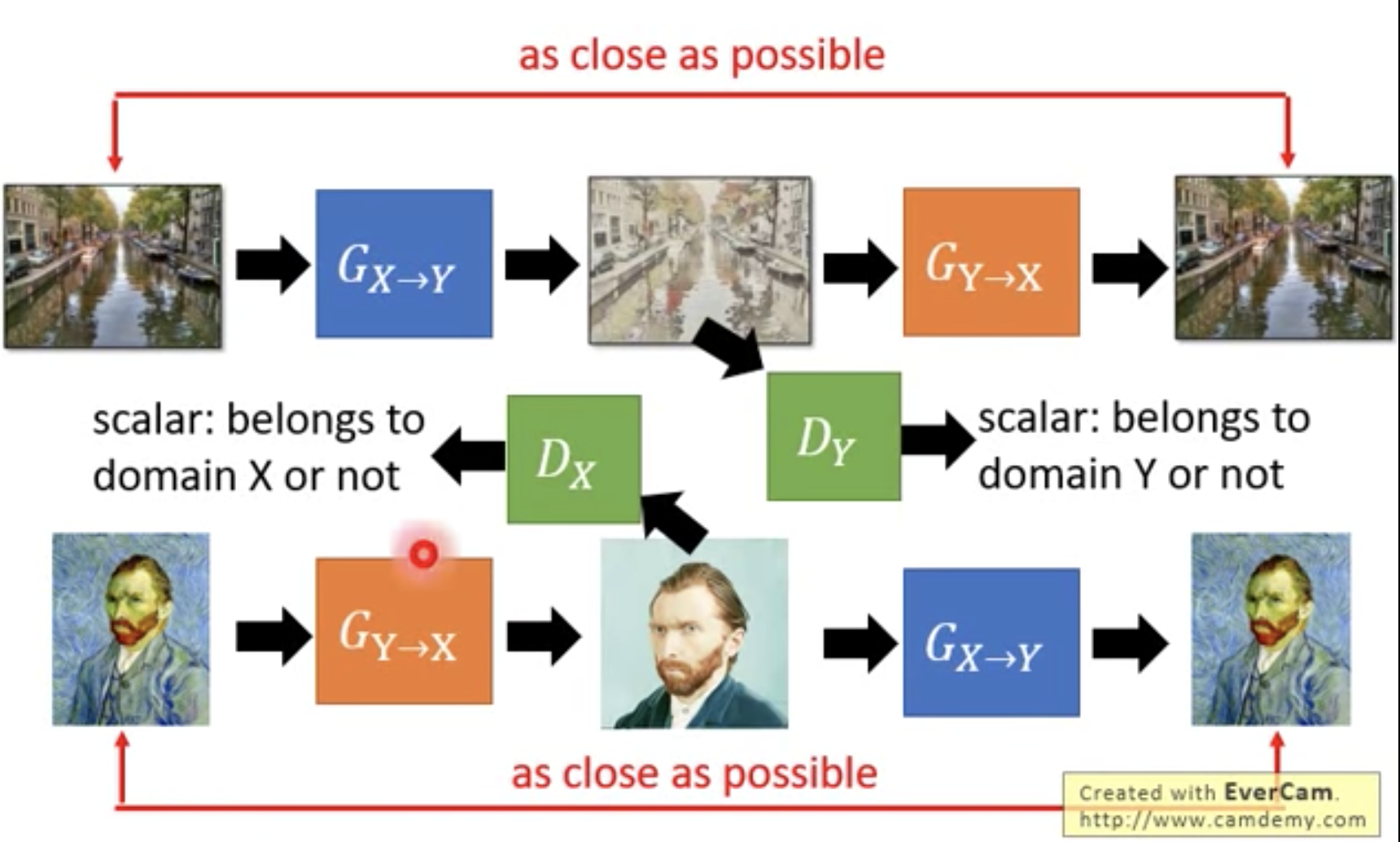
问题是,存在隐藏信息的可能(隐写术);generator出来的fake y domain存在问题,但是recovered domain x没问题,这说明模型通过其他方式绕过了cycle consistency loss,generator会隐藏信息,且善于恢复(cycle consistency loss很小),但是generator输出的stuff可能就和原始stuff差距很大了,这不是我们想要的。
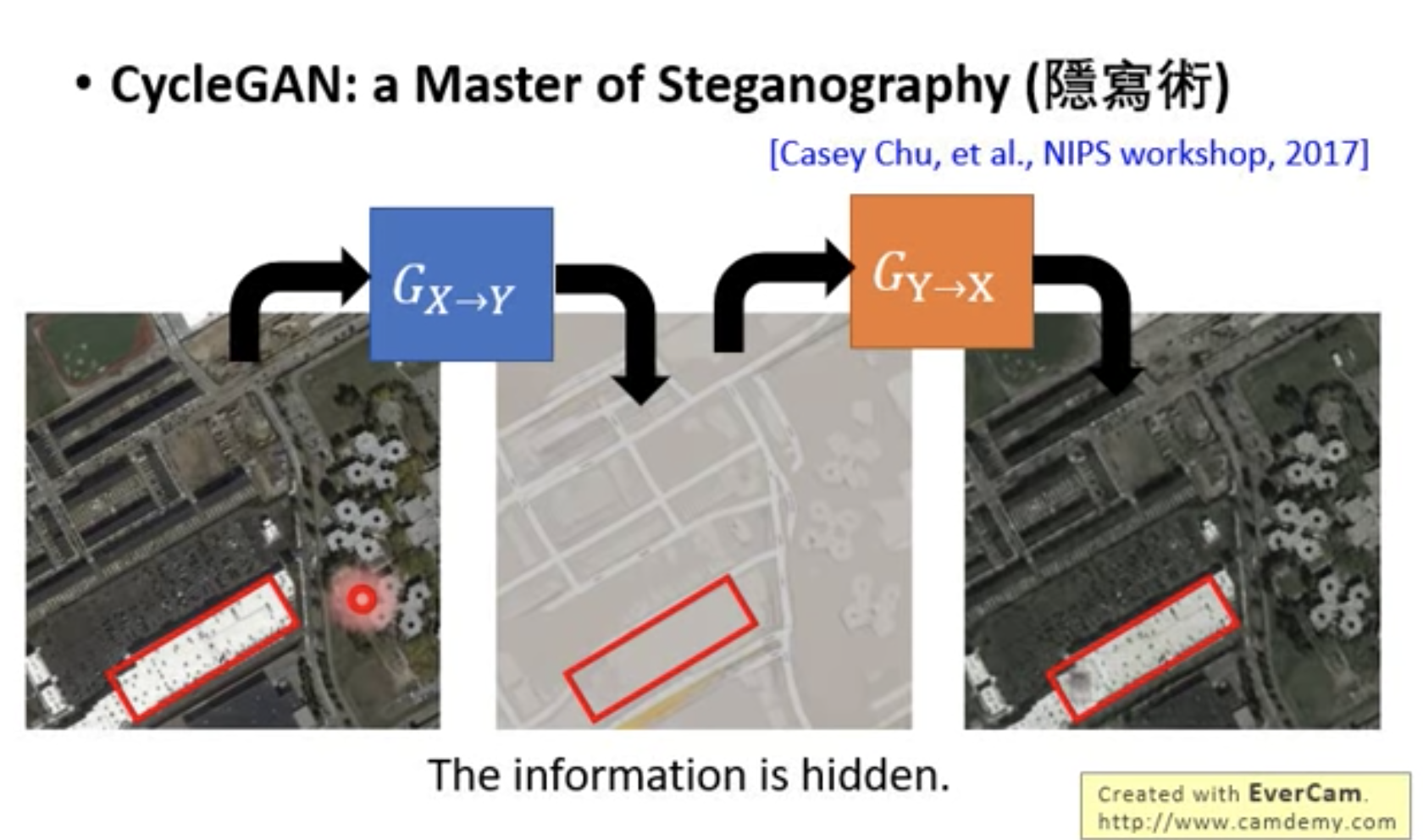
如上图所示:中间generator输出的fake y domain的质量很差,但是generator却比较擅长恢复x domain,导致虽然cycle consistency loss很小,但是fake y domain却达不到我们的预期。
StarGAN
多个domain间互相转换,正常需要$C_n^2$个generator,但StarGAN只需要1个generator。
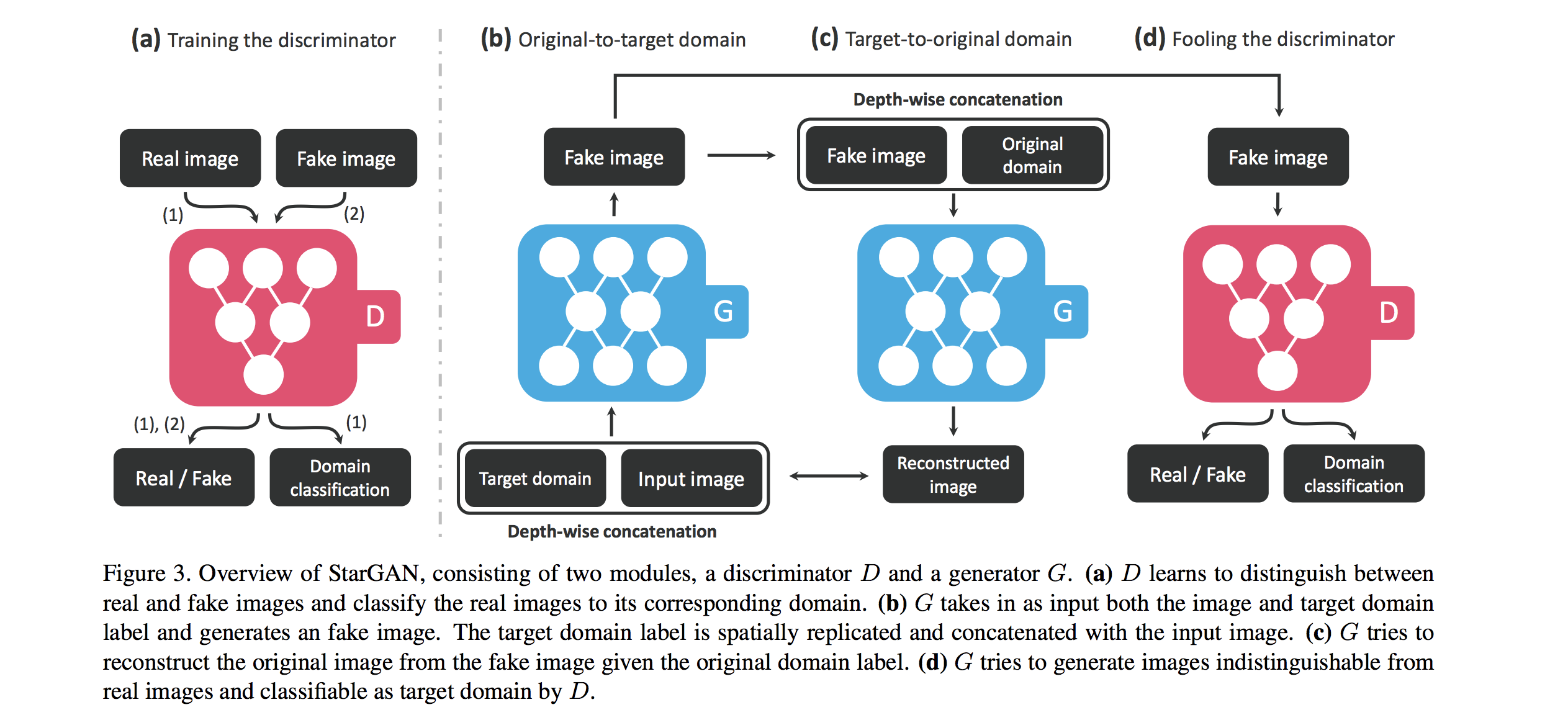
Demo如下:
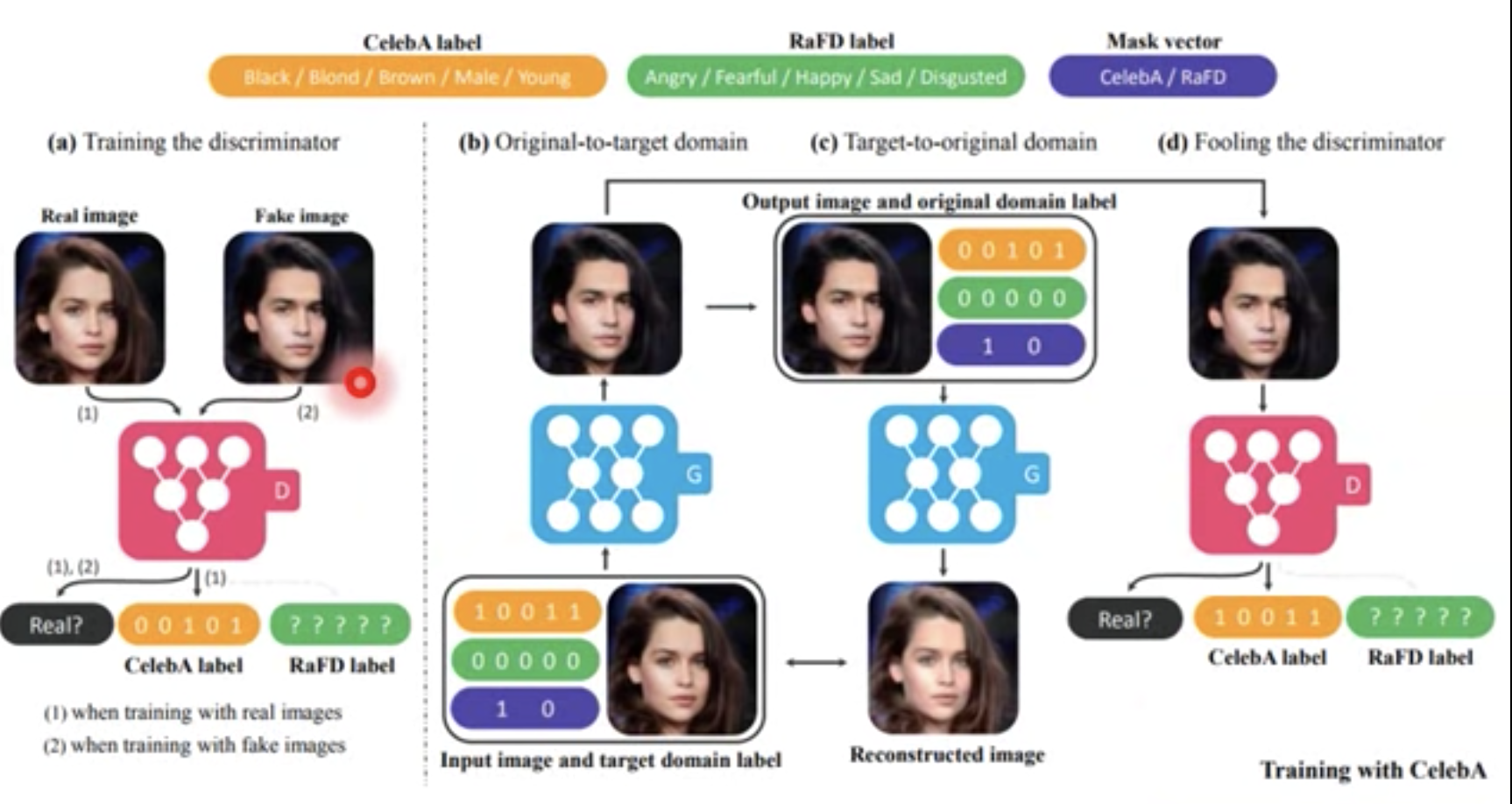
每个Domain(可能是组合,金色头发+年轻)有一个label。
Projection to Common Space
VAE-GAN
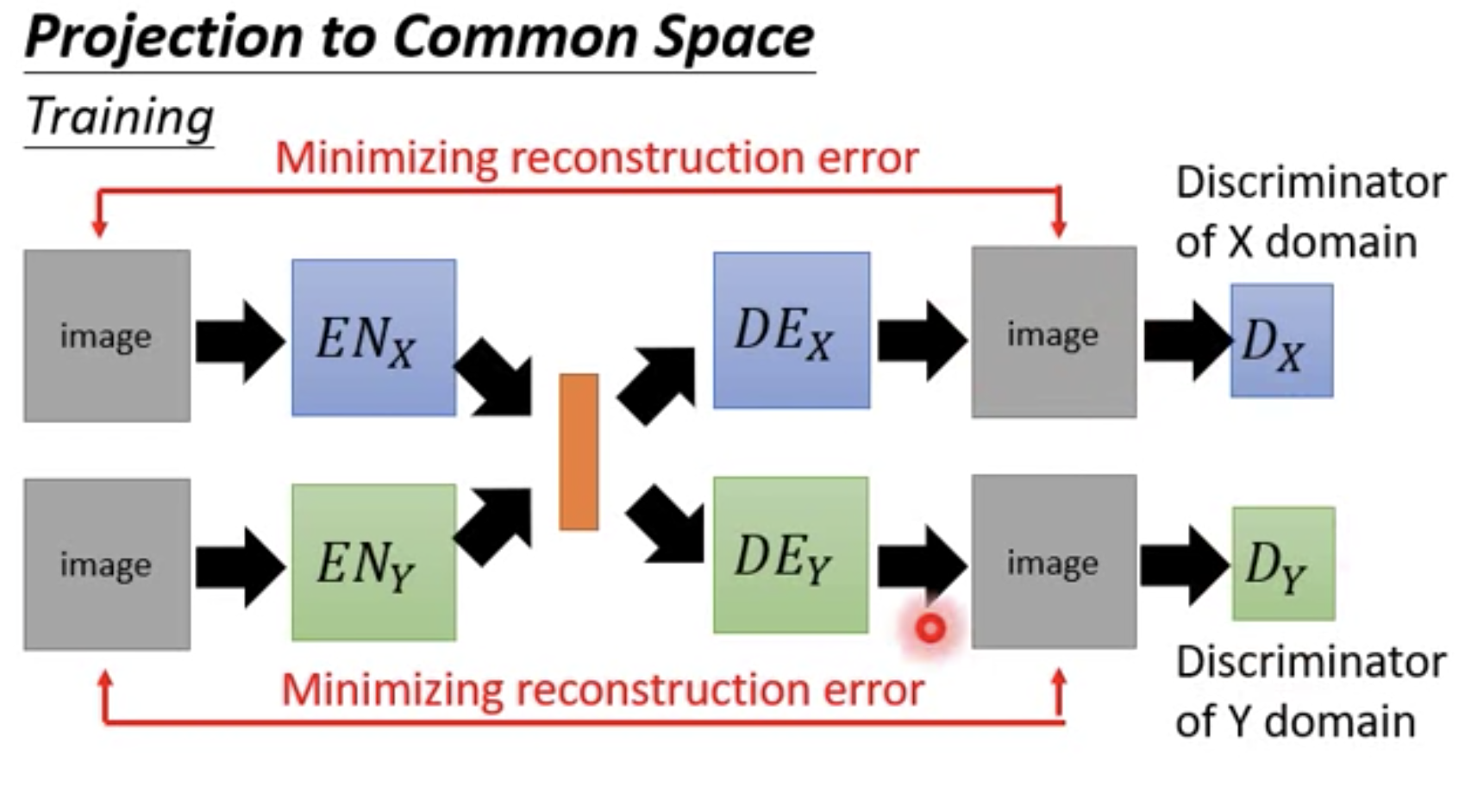
问题是,尽管得到了两个Encoder和两个Decoder。实际转换时,人脸照片作为Encoder X的输入,获取Decoder Y的输出,作为人脸照片的卡通画形象。如果训练时,输入数据是对应的数据pair对(人脸照片,对应的卡通化照片),那么中间的latent vector表达的语义在Encoder X中和Enocder Y中是一样的。但是,由于不是pairs数据进行训练,中间的latent space在Encoder X中和Enocder Y中的语义是不一样的,二者没有关系,是不同空间的。例如,在Encoder X中,latent vector第一维代表戴眼镜,在Enocder Y中,latent vector第一维可能代表长头发。这样,从Decoder Y输出的stuff,可能和Encoder X的输入stuff完全没有关系。我们必须保证latent vector对于Encoder X和Encoder Y来说,是位于common space的。上述的原因是,两个auto-encoder是分开训练的,除了中间共用了latent vector以外,优化时分开的,但是latent vector对于二者而言,语义可能完全不一样,即The image with the same attribute may not project to the same position in the latent space。
Couple GAN
Sharing the parameters of encoders and decoders.
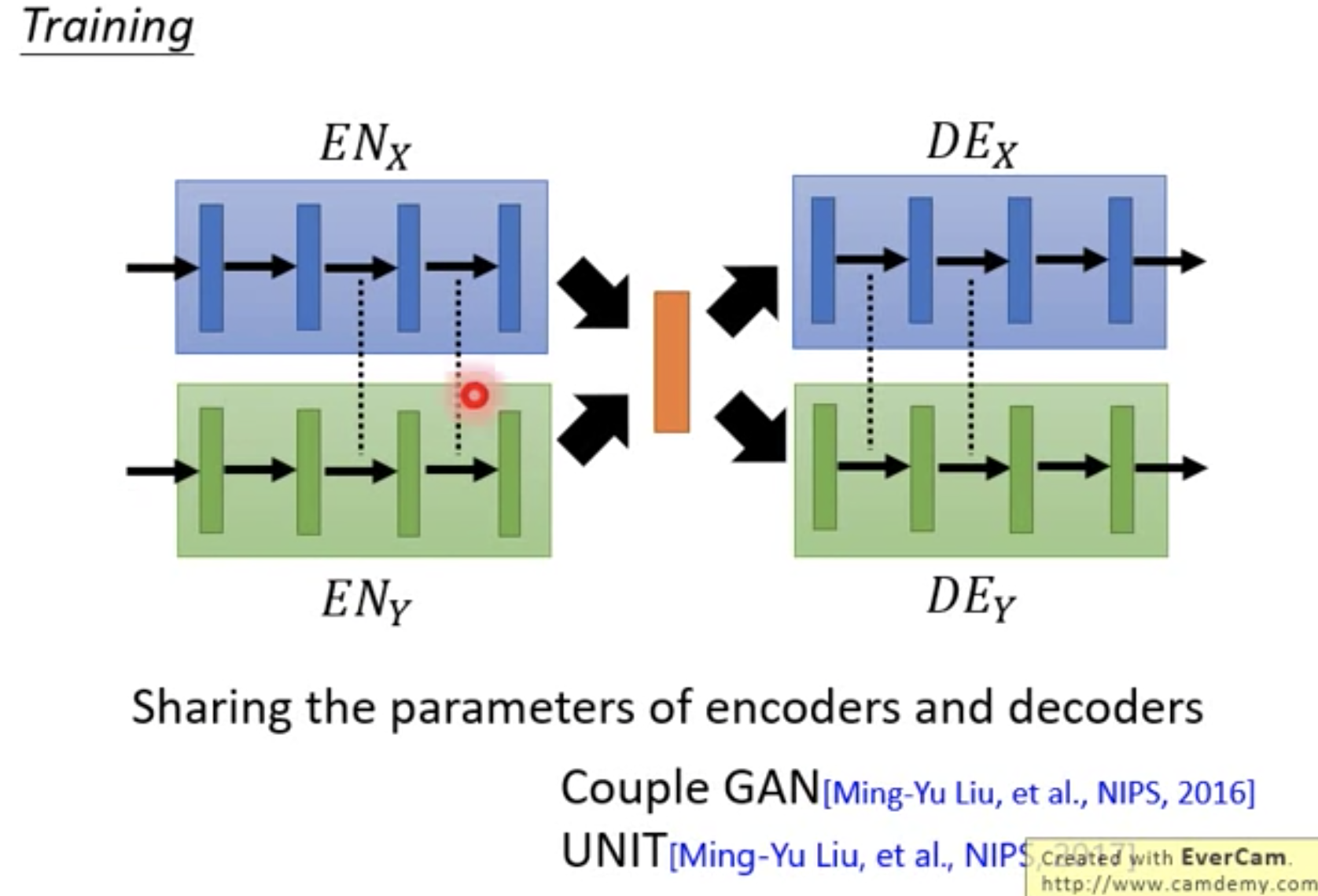
encoder最后几层的参数共用;decoder最前几层的参数共用。这样可以使得latent vector在两个encoder中的语义相似,在两个decoder的语义相似。极端情况下,两个encoder完全一样,只是输入的时候给不同domain的flags。
VAE-GAN + Domain Discriminator
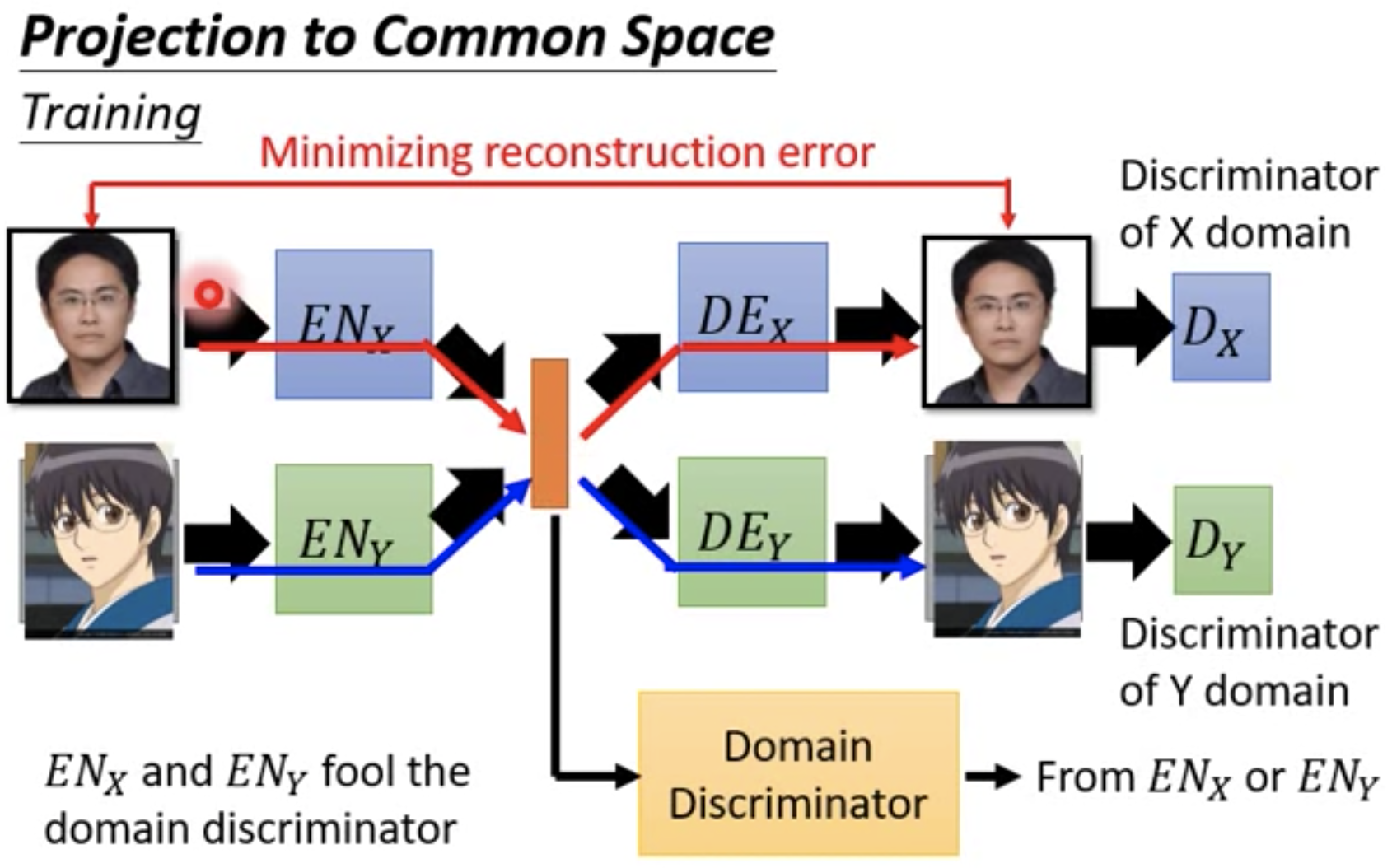
判断latent vector是从哪个domain的image转化来的。学习时,两个Auto-Encoder轮流骗Domain Discriminator。例如,Encoder X得到的fake latent vector作为负样本输入Discriminator,Encoder Y得到的real latent vector作为正样本输入Discriminator,不断更新Encoder X,来最大化Discriminator识别fake latent vector(X)为domain y的得分。反之,Encoder Y得到的fake latent vector作为负样本输入Discriminator,Encoder X得到的real latent vector作为正样本输入Discriminator,不断更新Encoder Y,来最大化Discriminator识别fake latent vector(Y)为domain x的得分。最终导致,Domain Discriminator无法识别latent vector是来自于Domain X还是Domain Y,此时意味着学习到的latent vector在Domain X和Domain Y中位于同一个语义空间。
ComboGAN: VAE-GAN + Cycle Consistency
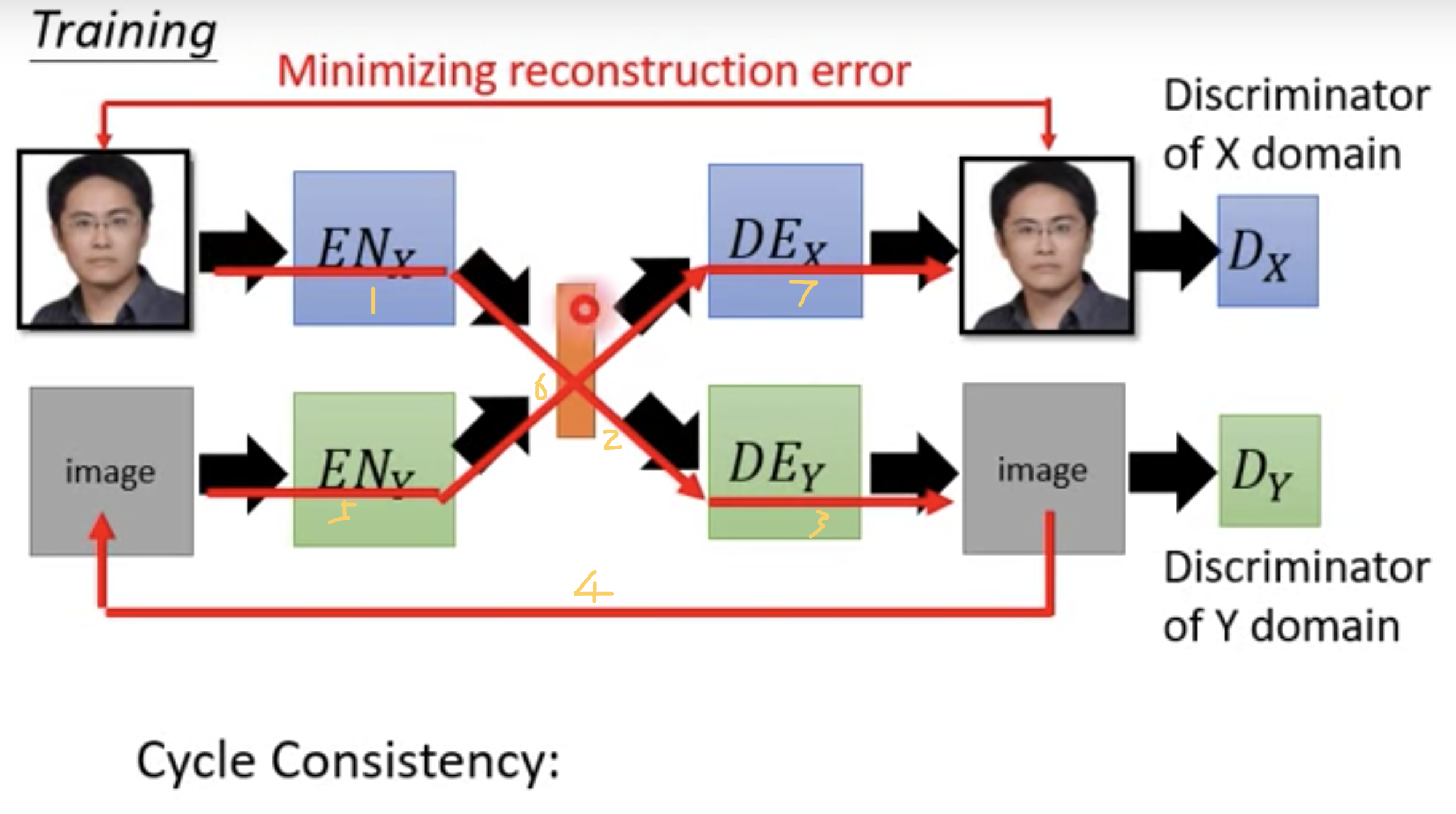
数据流入图中序号所示。
XGAN: VAE-GAN+Semantic Consistency
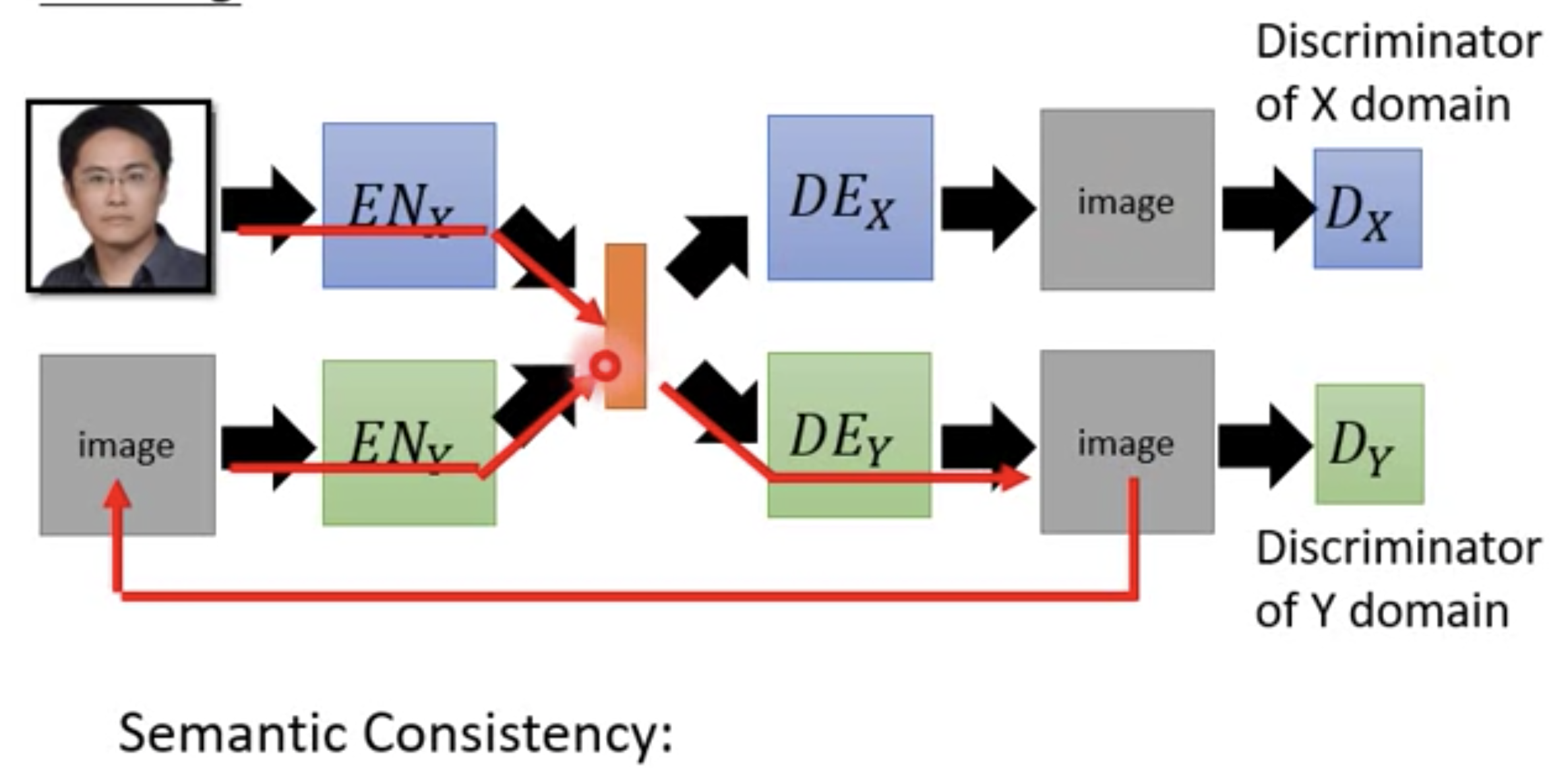
和ComboGAN类似,只不过重构误差加在latent vector上。经过Encoder X第一次得到的latent vector和经过Encoder X -> Decoder Y -> Encoder Y得到的latent vector之间误差最小,这是语义一致性,因为latent vector表征了学习到的语义。
Basic Theory behind GAN
Find data distribution $P_{\text{data}}(x)$。
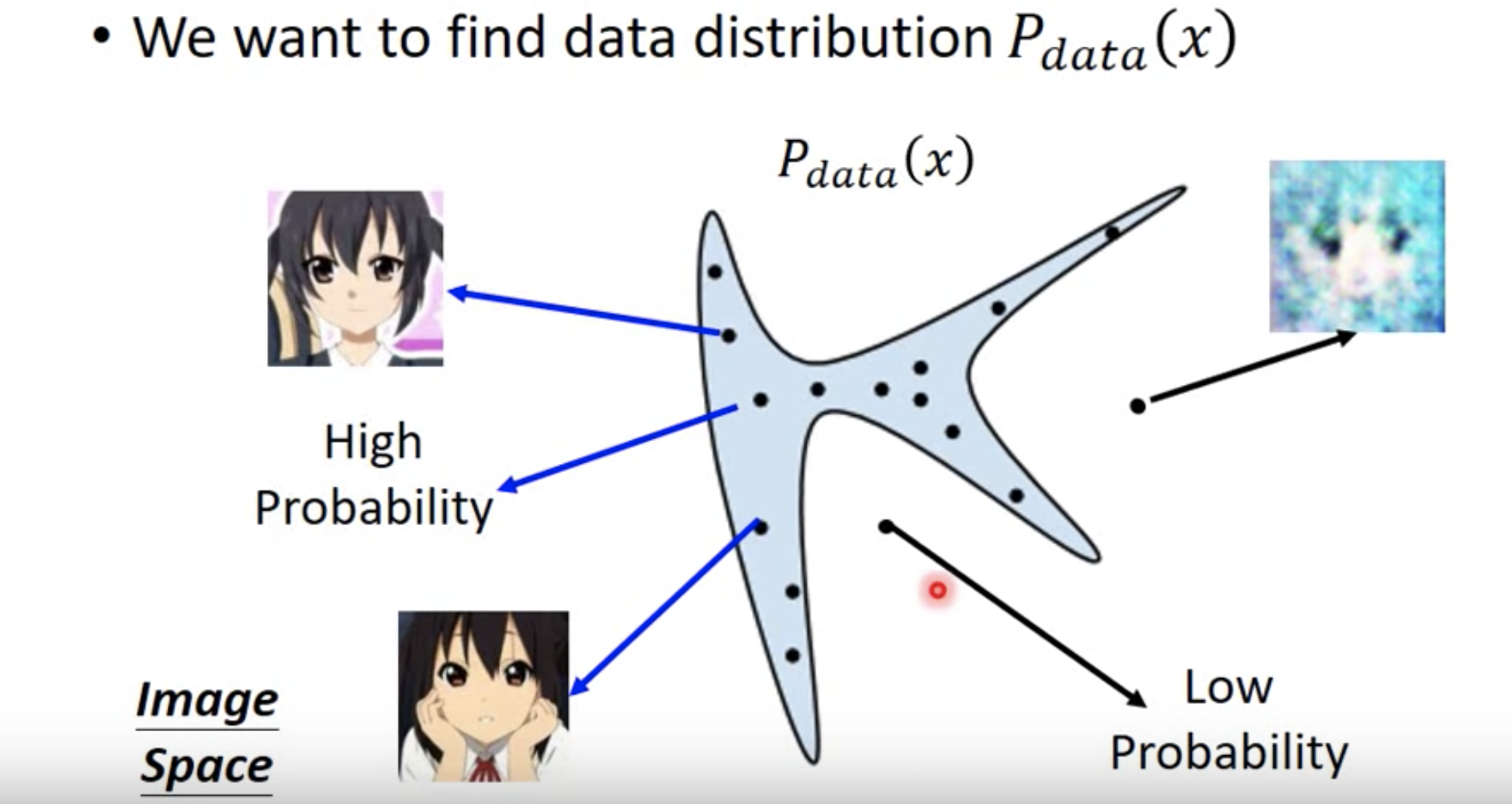
MLE
GAN之前的做法:MLE(maximum likelihood Estimation)

最大似然估计等同于最小化生成模型$P_G$和潜在数据分布$P_{data}$(我认为更准确的应该是经验分布)之间的KL divergence。注意下图推导中,$arg max_{\theta}$中的第二项$\int_x p_{data}(x)log p_{data}(x)dx$是与$\theta$无关的常数,故可以添加该项。

以往做法通常使用GMM作为$P_G$,然后在高维空间拟合样本$x$。但是训练完,通过GMM生成的图往往很糊,因为是直接在高维空间做的,但是很多高维空间的样本实际上是位于低维的语义空间,即Manifolds流形区域的,因此如果直接拟合高维空间的样本,往往学习到的东西是存在很多冗余和噪声的。
GAN
GAN的做法:
- Generator
A network which defines a probability distribution $P_G$.
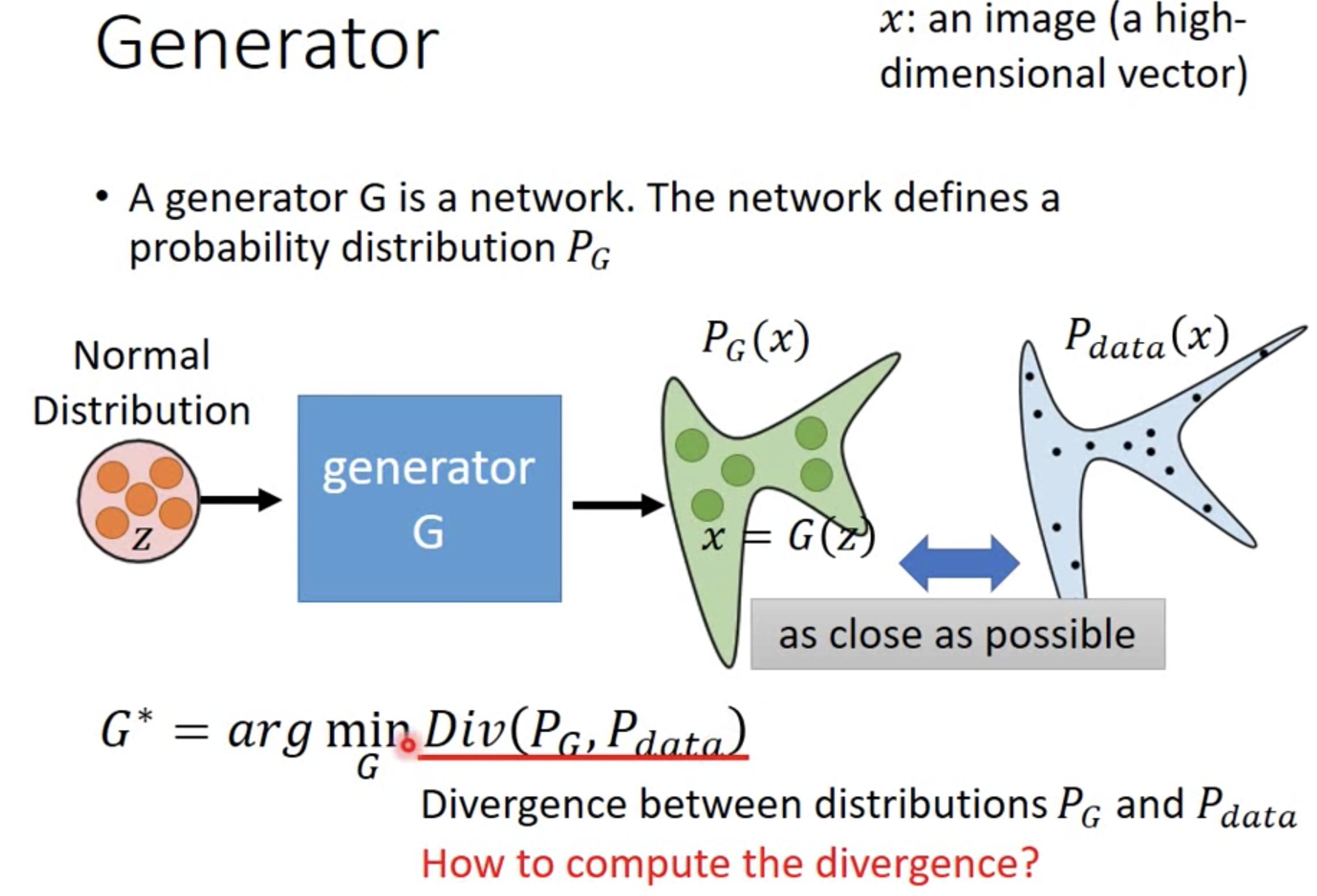
问题是Div很难算,$P_{data}$和$P_G$的Formulation是未知的。如果形式已知,那么Div能算,就可以直接通过梯度下降优化了。
GAN的做法很神奇,即使$P_{data}$和$P_{G}$的Distribution Formulation未知,但是二者都可以通过【采样】来近似。
- 对于$P_{data}$直接从已有数据集中进行采样,等价于从$P_{data}$中采样的;
- 对于$P_{G}$,随机地产生noise信号并输入到generator,generator的输出就是采样到的样本。(非常关键的理解!!!非常关键!!非常关键!!重要的事情说三遍!!)
也就是说,随机产生的输入信号noise的意义就是为了随机从generator生成模型中进行采样,等价于从$P_{G}$模型中进行随机采样。
那为什么nosie作为输入能够模拟从generator生成模型中进行采样?那是因为,如果两个随机变量$Z$和$X$之间满足某种映射关系$X=f(Z)$, 那么它们的概率分布$p_X(X)$和$p_Z(Z)$也存在某种映射关系。当$Z,X \in \mathbb{R}$都是一维随机变量时,$p_X=\frac{df(Z)}{dX}p_Z$; 当$Z,X$都是高维随机变量时,导数变成雅克比矩阵,即$p_X=\boldsymbol{J}p_Z$。因此,已知$Z$的分布,我们对随机变量间的转化函数$f$直接建模,就唯一确定了$X$的分布(实际上,回顾一下会发现这就是“逆变换采样法”的原理)。在GAN中,$Z$就是满足某种特定分布的随机Nosie输入信号,$f$为Generator神经网络,则Generator的输出即为$X_{fake} \sim p_{generator}$。因此,随机的noise输入,Generator输出的就是对应的采样到的fake stuff。
往更深一步讲,这是一种重参数化技巧(Reparametrization tricks),将采样操作提前到计算图开始执行之前,使得BP算法能够正常使用;换句话说,就是要防止在计算图运行过程中执行离线的采样操作(如generator采样)导致误差无法反向传播。这种技巧在VAE中很常见(对Encoder得到的隐变量z的采样使用重参数化技术)。

那么采样完数据后,如何计算二者之间的Divergence呢?
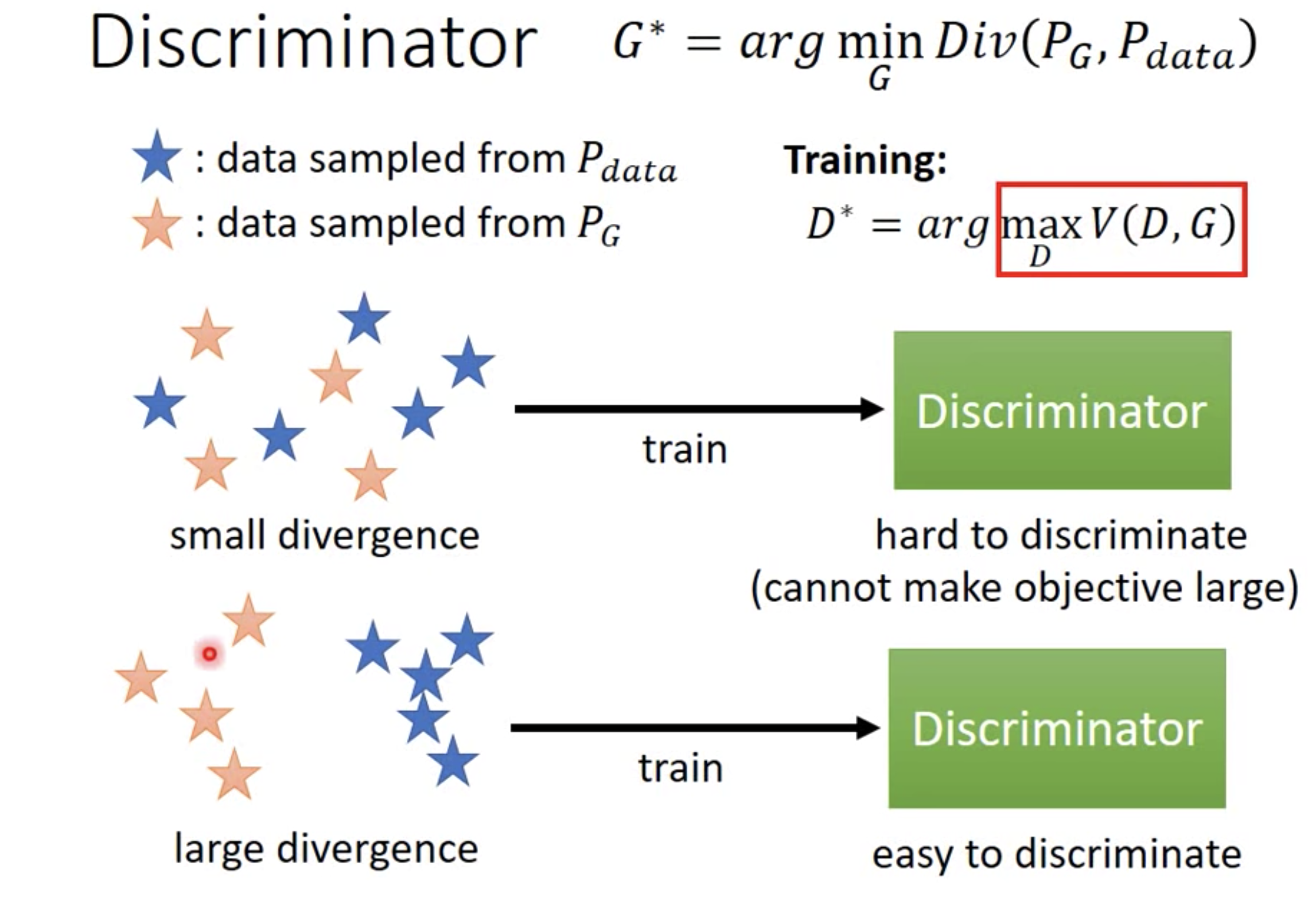
- Discriminator
GAN利用Discriminator来计算二者之间的Divergence。实际使用时,就是选择某种关于二者的目标函数进行优化,来近似等同于优化二者之间的Divergence。

重要结论:目标函数的最优值和JS divergence密切相关(目标函数的上界是JS)。
$$
\max V = \text{JS}\ \\
\arg \min \text{JS} \leftrightarrow \arg \min \max V
$$
看出端倪了。Discriminator的目标是最大化real stuff的得分以及最小化fake stuff的得分,等价于最大化V(G,D),其中G是固定的,V的第一项是real stuff的得分$D(x \sim p_{data})$要最大化,第二项是fake stuff的得分$D(x \sim p_{generator})$要最小化,即$1-D(x \sim p_{generator})$最大化,也就是最大化V函数。而最大化V函数的结果正好衡量了real stuff数据分布和generator生成的fake stuff数据分布之间的JS!!那么,轮到generator优化时,顺理成章就是最小化二者的JS,等价于$\arg \min \max V$, 最终变成了一个max-min博弈问题。
直观解释:
理论证明:

积分最大化,转成每个样本都最大化,那么所有样本相加也是最大化。
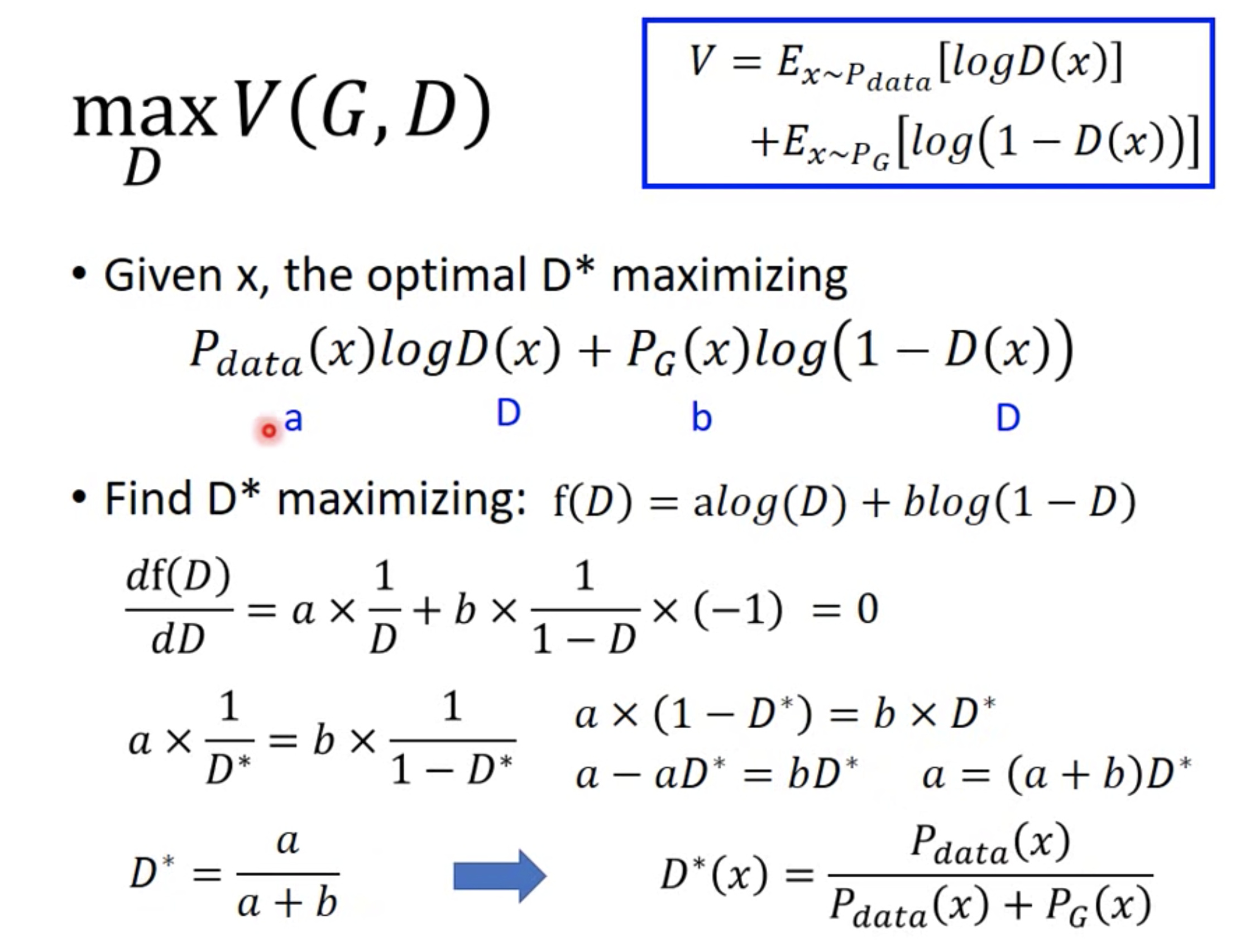
求导得到最优的$D^{*}(x)$。代入原来的目标函数得到:
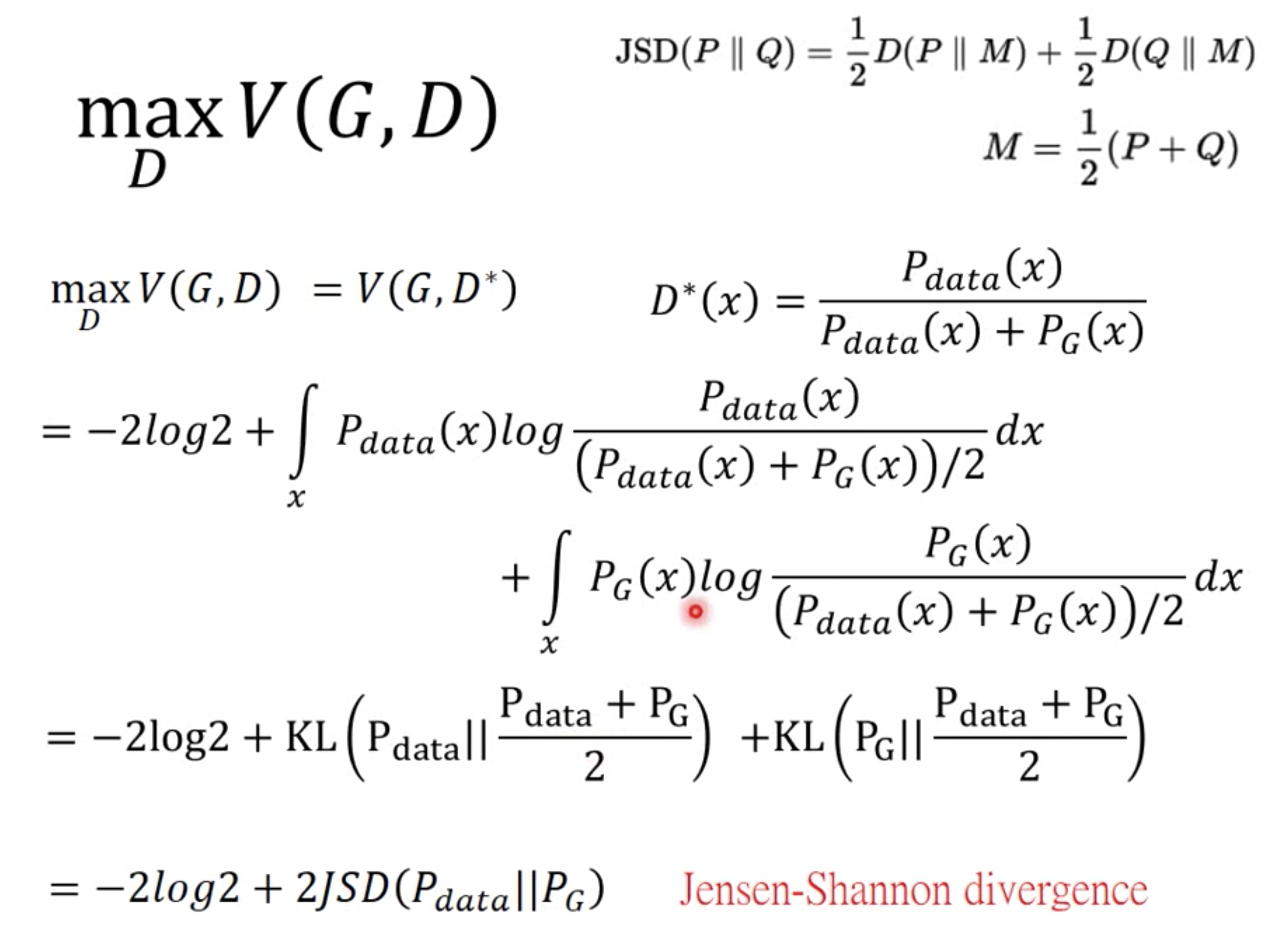
优化目标转换:
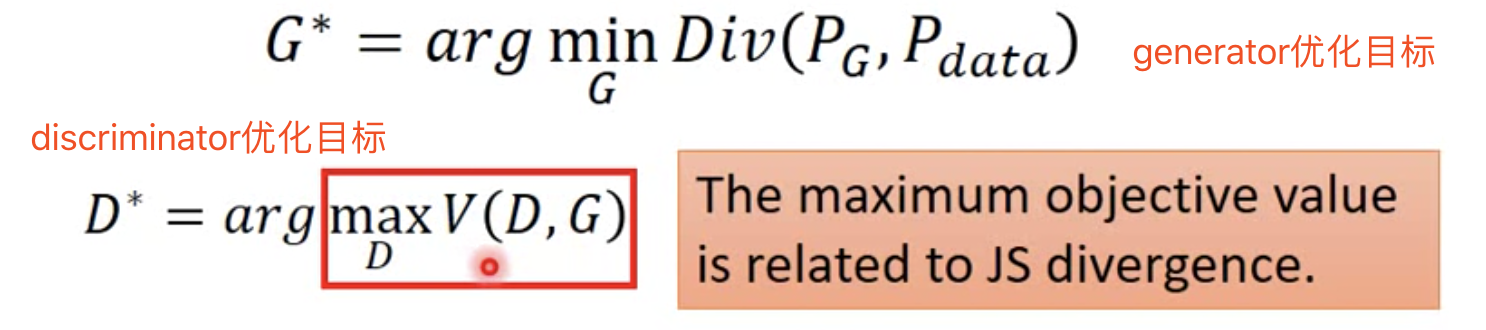
代入$\max V= \text{Div}$:
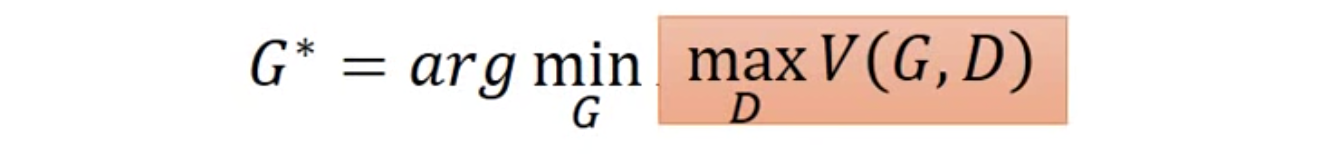
变成了一个MIN-MAX的问题。
举个例子进行形式化解释。
假设候选的Generator只有3个,G1,G2,G3。Discriminator只由1个参数(横坐标)决定,曲线D上任意一点代表不同的Discriminator。
在给定Generator条件下,优化D。选择D使得$V(G,D)$最大化,也就是下图每幅图中的最高点对应的D,得到3个点。
在给定Discriminator条件下,优化G。选择G使得$\max V(G,D)$最小,因此在上述得到的3个D中,选择最小的点对应的Generator,即G3。
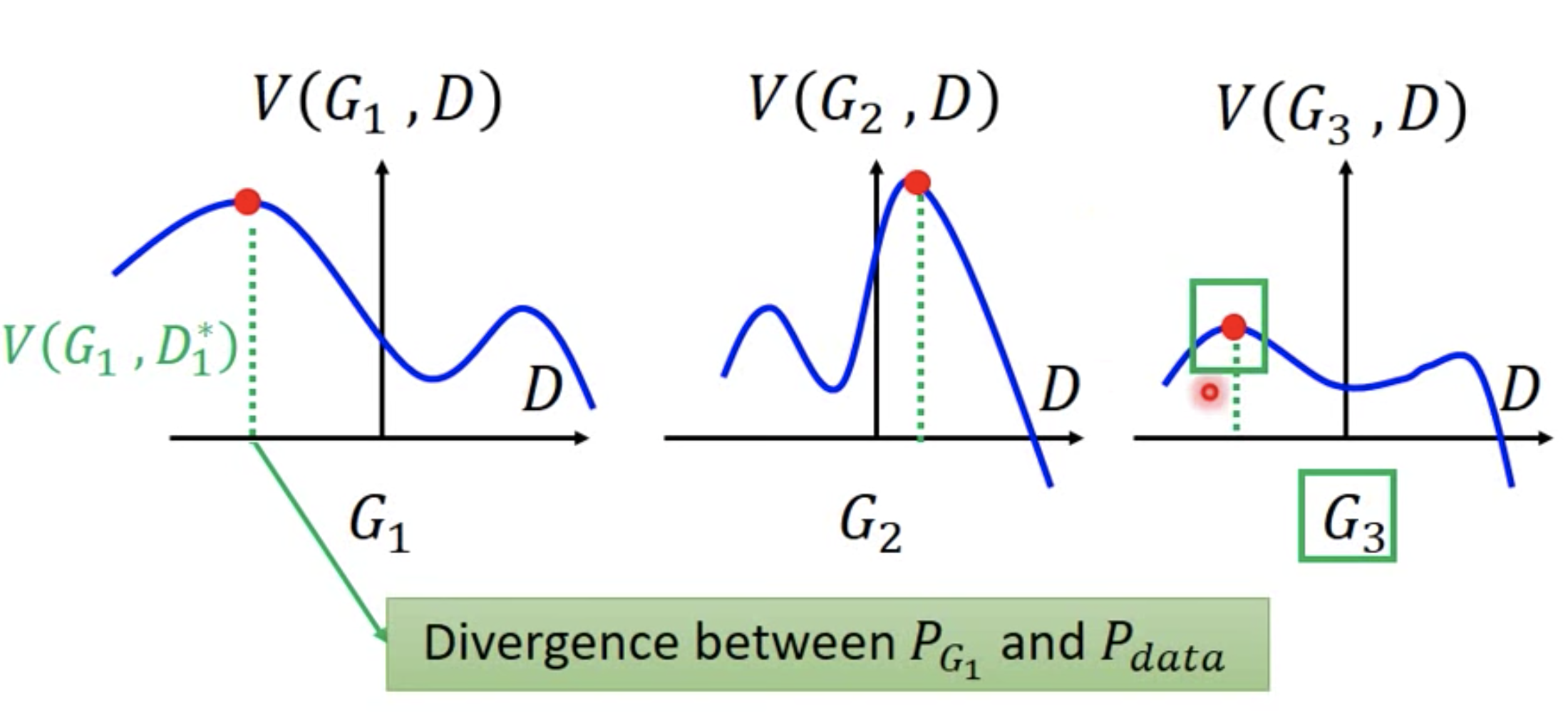
演算法如下:

G固定,更新D。直接$\arg \max_D V(G,D)$,即可。Evaluate JS Divergence.
D固定,更新G。Minimize JS Divergence.
主要难点在于max operation的求导。
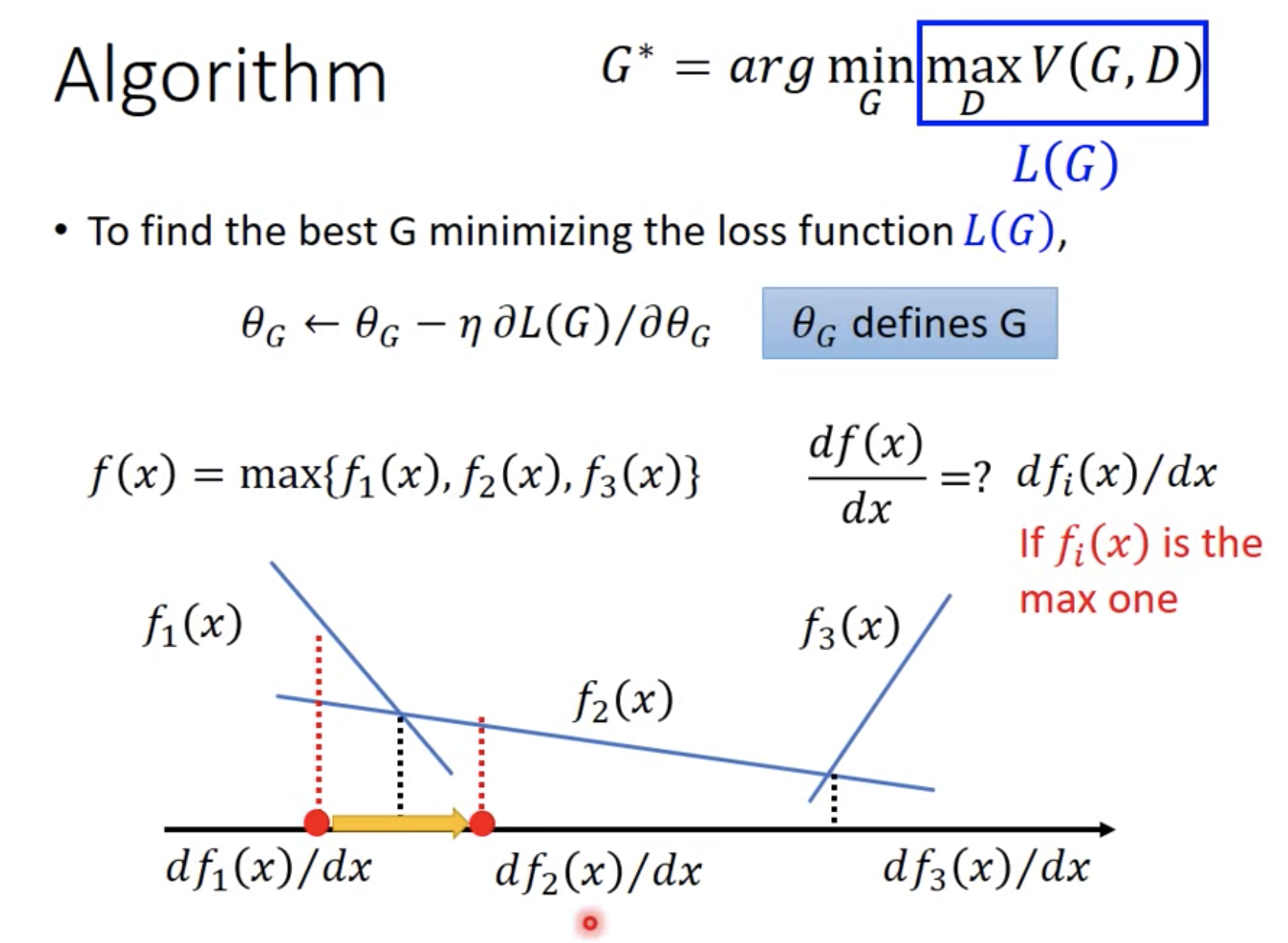
梯度下降:如果从整体上来看,$max V(G,D)$等价于JS目标,那么第二步就是最小化JS目标,因此用梯度下降。
从细节来看,前面我们说优化G时,希望更新后的G产生的样本,D能给更高的分,等价于V(G,D)的第二项越小越好($1-D(x \sim P_{generator})$越小,$D(x \sim P_{generator})$越大),而第一项与G无关,则相当于整体上V(G,D)越小越好,因此用梯度下降。
max operation求导:实际上就是不同的G(类比输入$x$),对应不同的V(G,D)(类比$f_i(x)$,可以看做分段函数)曲线。把所有不同G对应的V(G,D)曲线求max operation整合在一起,得到一个总的曲线就是$L(G)$。从另一个角度理解,V(G,D)越大,$G$越不喜欢,而$G$倾向于减小$V(G,D)$,因此选择最大的$V(G,D)$能够提供最大的梯度。
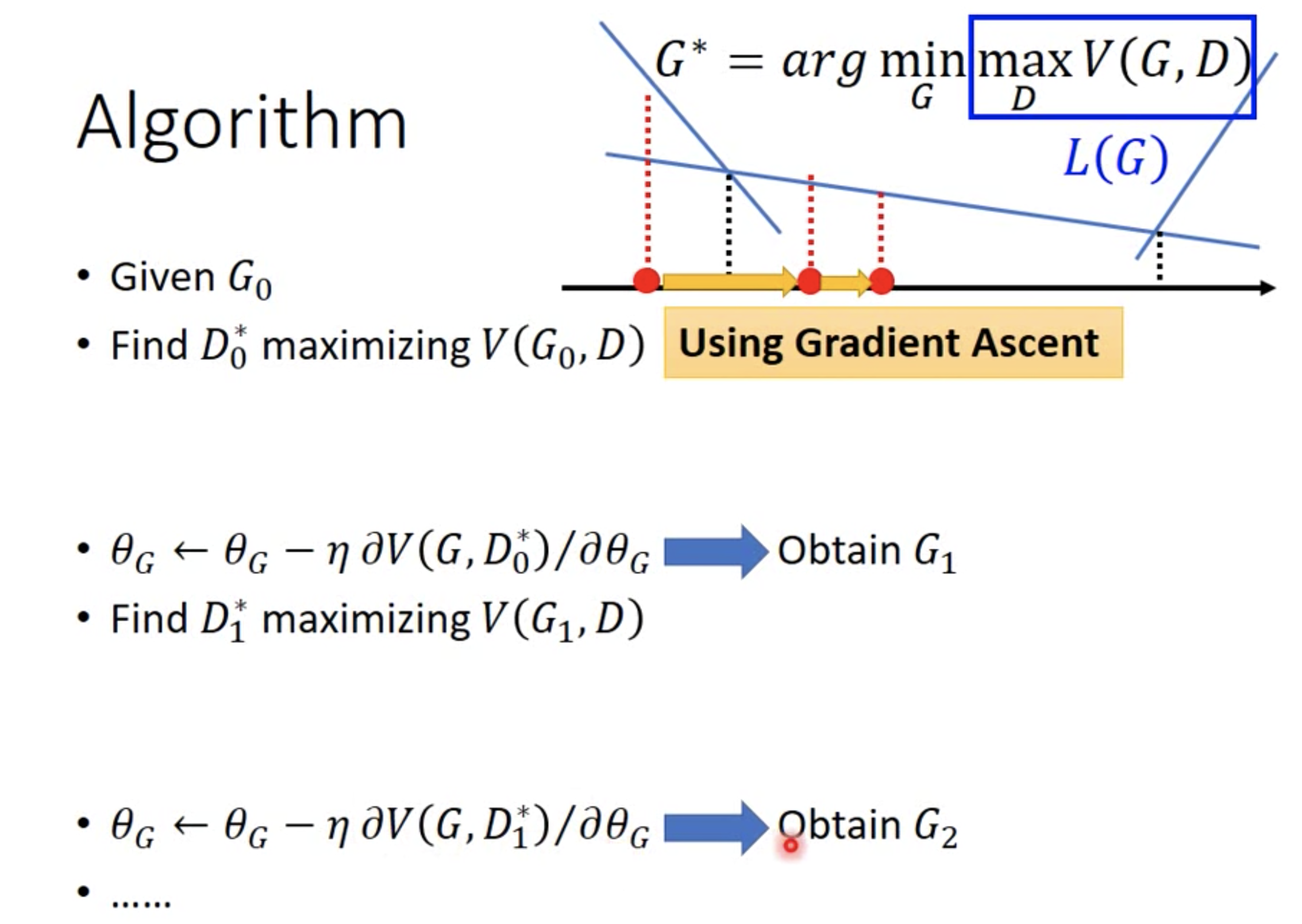
但这里有个问题,迭代过程中,每轮迭代之间JS divergence都会下降吗?我们不妨来看下图,
- 第一次迭代,给定$G_0$, 找到$D_0^{*}$来最大化$V(G_0, D)$。因此,$V(G_0, D_0^{*})$此时等于JS divergence。接着,固定$D_0^{*}$,最小化$L(G)$,得到$G_1$。此时,要注意$V(G_1,D)$的曲线发生了变化,不再是$V(G_0, D)$的曲线。并且,在$V(G_1,D)$曲线中,$V(G_1,D_0^{*})$这个点不再是$V(G_1,D)$的最高点。
- 第二次迭代时,给定$G_1$,找到$D_1^{*}$来最大化$V(G_1, D)$,最大值会发现是图中的点$V(G_1, D_1^{*})$,该值是此刻真实的JS divergence,相比于前一轮迭代,该JS divergence不降反升。
究其原因是,G的更新幅度太大,导致V(G,D)曲线变化太大。如果G的更新幅度很小,两幅曲线基本一致的话,则,$D_0^{*} \approx D_1^{*}$,即两幅曲线的最高点都在相同的位置取到,此时梯度下降更新G的结果就像稍微把曲线往下挪,仍然在同一个位置取到JS最大值,但是此时JS divergence相比于前一轮迭代是下降的。
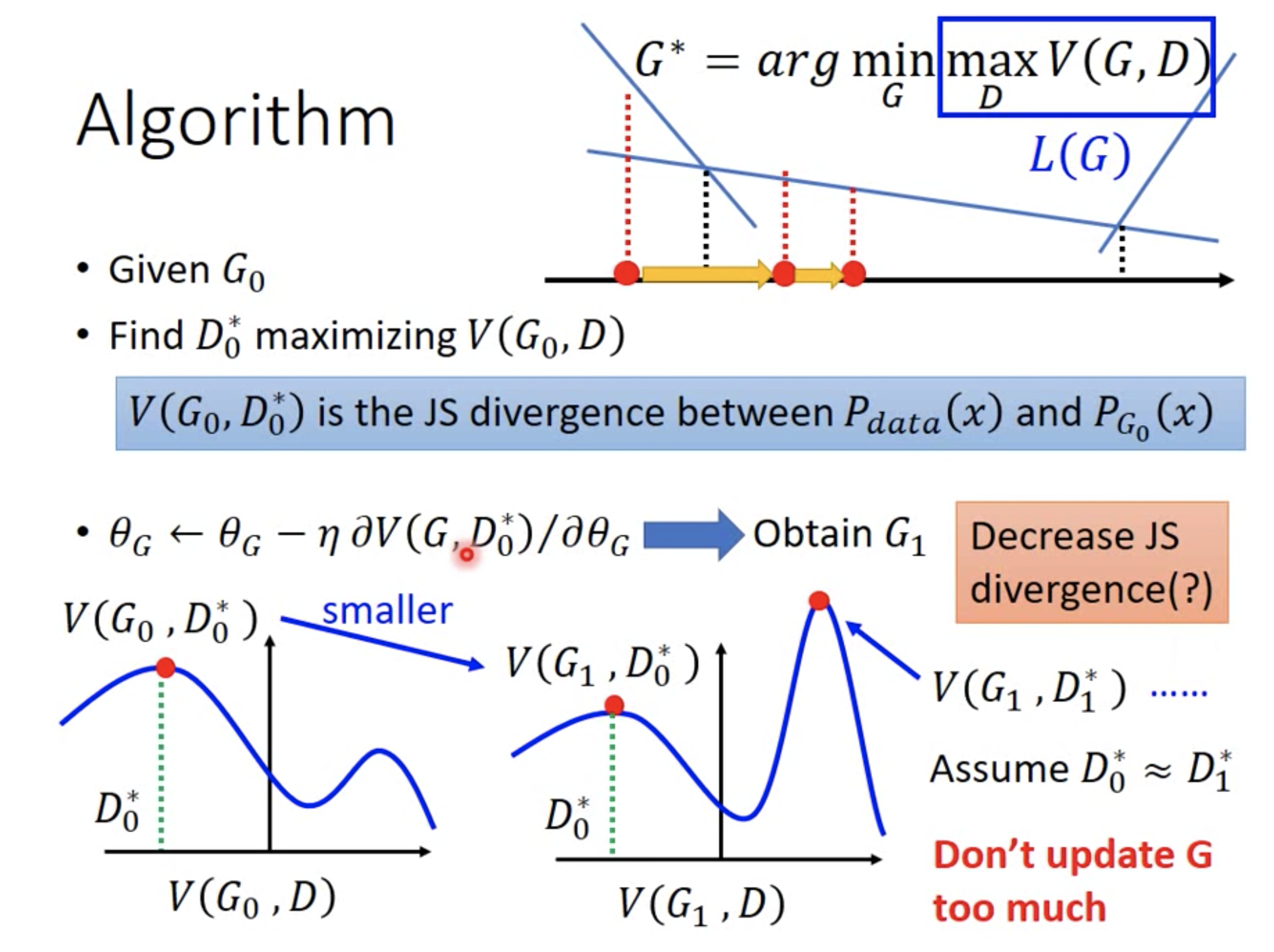
因此,实际更新模型时,每轮迭代时,对Discriminator必须要使劲训练,Train到收敛,因为V的最大值才能用来衡量JS Divergence;而对Generator不能更新太多,稍微训练即可,防止V(G,D)曲线变动。另外,优化目标函数中存在期望,实际优化时,使用抽样的方式求平均值来近似期望。

注意,在更新G时,V的第一项和G没关系。
另外,在更新G的时候,要最小化V的第二项,即$\log(1-D(x))$。然而,由于$\log(1-D(x))$在D(x)很小时(比如:一开始训练),导数很小,导致收敛非常慢。因此,实际实现时,通常改成优化minimize: $-\log D(x)$(最小化$\log(1-D(x))$,即最大化$\log(D(x))$,也即最小化$-\log D(x)$),二者趋势一致,但是导数大,收敛快。如下图: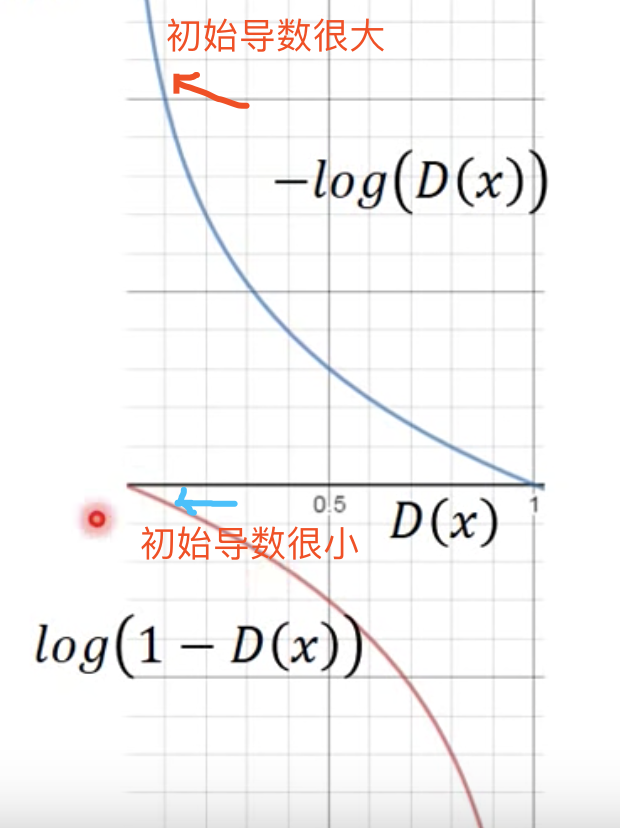
而从另一个角度,在最小化$-\log D(x)$时,完全可以复用更新Discriminator的代码来更新Generator。只需要将标签反过来,即:generator输出的作为正样本,数据集中的作为负样本,然后运行Discriminator更新的代码即可。即,
$$
\begin{split}
& \underbrace{\max E_{x \sim P_{\text{data}}}[\log D(x)] + E_{x \sim P_{\text{G}}}[\log(1-D(x))]}_{\text{object function of Discriminator}} \\
& \leftrightarrow \\
& \underbrace{\max E_{x \sim P_{\text{data}}}[\log (1-D(x))] + E_{x \sim P_{\text{G}}}[\log(D(x))]}_{\text{object function of Generator}}
\end{split}
$$
第一个式子是Discriminator的更新代码;第二个式子是Generator的更新代码,可以看出是直接将V的第一项real data的预测标签从$D(x)$改为$1-D(x)$, 第二项fake data的预测标签从$1-D(x)$改为$D(x)$。
在更新Generator时,第二个式子的第一项在更新Generator时是常数,可以忽略;而max第二项就等价于min $-\log D(x)$,也即Generator的目标。
总结
不得不说李老师的教学视频非常棒!受益匪浅!比大多数网上讲解GAN的资料好太多。再次致谢!

