本次将带来基于GNN的序列推荐论文系列。整个系列主要围绕最近两年来基于图神经网络的序列推荐工作展开。这些工作包括但不限于,AAAI 2019 SR-GNN,IJCAI 2019 GC-SAN,SIGIR 2020 GCE-GNN,AAAI 2020 MA-GNN等。此次先带来第一篇SIGIR 2020 GCE-GNN,全局上下文提升的图神经网络。主要围绕5个方面展开(我称之为5-TION原则),Motivation,Contribution,Solution,Evaluation,Summarization。
1. Motivation
- 传统的序列推荐通常只使用目标session信息,而忽视了其它session的信息。其它session的信息通常也包含着一些和目标session有可能不相关,但也可能很相关的信息。因此,本文的主要动机如下:
- 同时利用目标session和其它所有的session信息。
- 在使用全局所有的session时,需要区分出哪些和目标session相关,哪些和目标session无关,抽取出相关的信息来辅助目标session更好地进行物品表征。
- 为此,作者提出了一种全局上下文提升(global-context enhanced)的GNN网络,称为GCE-GNN。能够从两种层次来学习物品的表征,包括global-level:从所有session构成的图上进行全局的表征;以及session-level:从单个session局部item转移图上进行局部的表征;最后融合二者,并通过注意力机制形成最终的序列表征,用于序列推荐任务。
2. Contribution
- 第一次引入global-level 物品转移图(pairwise item-transition graph)来进行序列推荐,该图是从所有session的物品转移数据中构造而来的。
- 从两个维度考虑pairwise item-transition关系,包括global-level item-transition graph和session-level item-transition graph。针对不同的图,提出了不同的表征方法。其中,global-level提出了session-aware注意力机制,能够选择性地从全局图中抽取出和目标session序列相关的信息。session-level则提出了一种position-aware的注意力机制来挖掘逆序位置信息,并融入到item的表征中;这个机制对序列推荐性能的提升非常重要。
- 做了广泛的实验,在3种真实数据上优于目前state-of-the-art的方法。
3. Soution
先从整体上梳理下整个方法。
- 首先是构图,针对global graph,根据输入的所有session序列来构造,实际上就是将每个session中的两两物品转移关系都融入到全局图中;针对session graph,只根据目标session内部的两两物品转移关系来构造。
- 接着是单个物品的表征,即:对象是目标session序列$s$中某个物品$v_i$,要对它进行表征。首先是global graph上的表征,遵循标准的GNN信息传递机制,采用了加权汇聚邻域结点,作者提出了session-aware的注意力汇聚机制,会计算$v_i$在global graph上的每个邻居结点$v_j$和$v_i$的亲和度值,亲和度值的计算过程和目标session序列表征以及表征对象$v_i$都有关;针对session graph,作者区分了多种连边关系,入度边,出度边,自连接边,双向边;并设计了edge-type specific的注意力机制来加权汇聚邻域结点。最后,每个结点$v_i$的表征等于其在global graph上的表征加上在session graph上的表征。
- 最后是序列的表征,首先在序列结点$v_i$的表征中融入了位置信息(逆序位置嵌入);然后对序列中的结点表征作mean pooling得到session information,这个session information作为序列attention的trigger去和序列中的结点做position-aware的soft attention,得到表示每个结点对序列表征的贡献度值,根据该值加权每个结点的表征,最终得到序列的表征。
下面围绕着几个方面来介绍,首先看下整个框架结构。
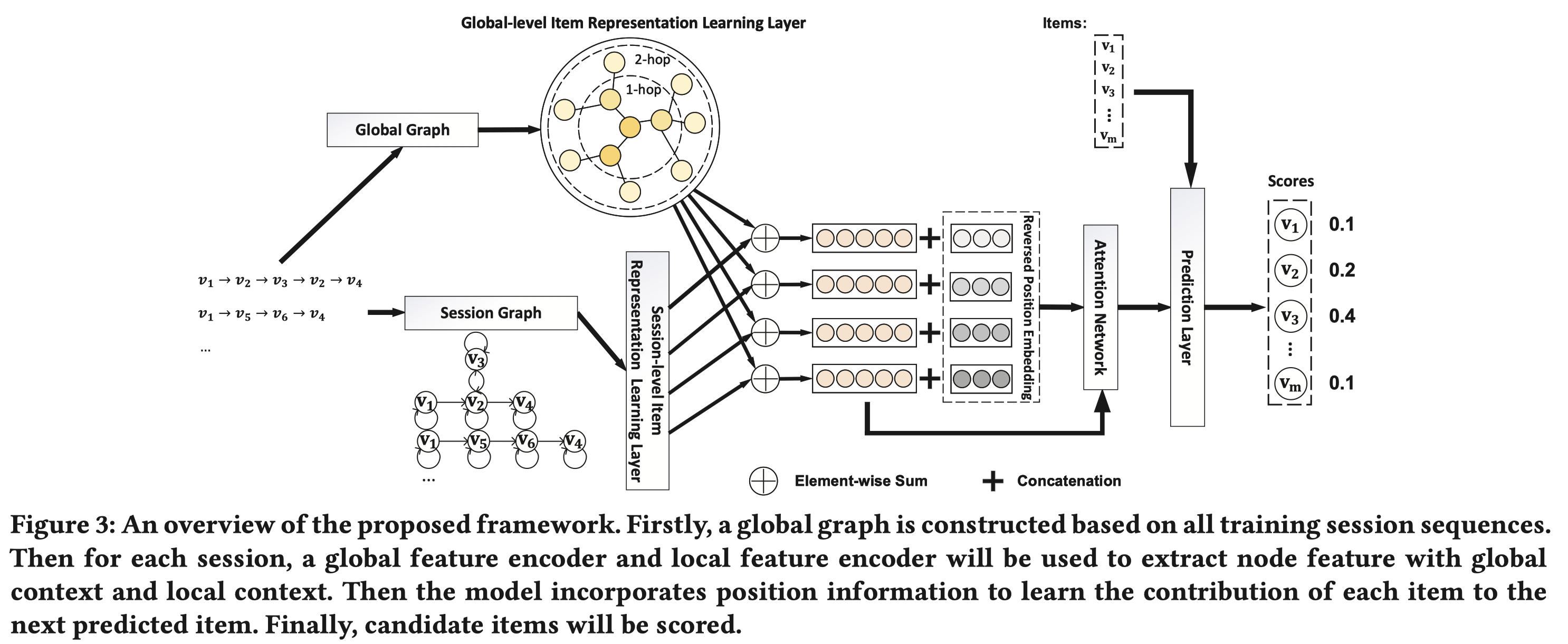
3.1 构图
session-graph: 有向图。包括了4种边关系,入度边,出度边,同时入度和出度边(两个结点互相指向),自连接边。
如图中左下角的部分,每条序列构造连边的时候,根据相邻物品结点构造转移边以及自连接边。其中,相邻结点的转移边又可以根据两个结点之间的关系区分为,仅入度边,仅出度边,同时入度和出度边(两个结点互相指向)。
global-graph: 定义一个$\epsilon-\text{Neighbor Set}$,实际上就是说同一个序列,任意两个结点想构造连边时,这两个结点之间的单位距离必须小于$\epsilon$。构造得到的图是带权无向图。连边权重使用共现的次数来表示。对每个结点,只保留Top-N权重的边。$\epsilon$和Top-N机制的目的都是为了减小复杂度,如果序列所有结点之间做全连接,那么构造得到的图的边规模会非常庞大。
3.2 物品表征
针对目标序列$S$中的某个物品结点$v_i$,我们要首先对它进行表征。结点$v_i$既出现在由序列$s$构成的session-graph中,又出现在global-graph中,我们可以从这两个图中分别提取结点$v_i$的表征,然后融合起来形成单个物品的表征。
3.2.1 Global-level物品表征
提取全局图上的物品表征的主要好处是能够借鉴其它session中和目标session相关的有用信息。因此,这里头的关键点是,如何衡量全局图上的信息是否和目标session序列$S$相关,是否对目标结点$v_i$的表征有作用。
信息传播:为了实现这一点,作者提出了一种session-aware的注意力机制,计算global-graph上和$v_i$相邻的结点$v_j$的贡献值$\pi(v_i, v_j)$
$$
\pi(v_i, v_j)=\text{softmax}(\boldsymbol{q}_1^T \text{LeakyRelu}(\boldsymbol{W}_1[\boldsymbol{s} \odot \boldsymbol{h}_{v_j} || w_{ij}]))
$$
其中,$\boldsymbol{s}$是目标序列的表征,是目标序列中所有结点的mean pooling结果,即$\boldsymbol{s}=\frac{1}{|S|}\sum_{v_i \in S}\boldsymbol{h}_{v_i}$。$\boldsymbol{h}_{v_j}$是结点$v_j$的表征;$w_{ij}$是结点$v_i$和$v_j$在global graph上的连边权重。这个公式的好处是把目标序列$S$和邻居结点$v_j$以及目标结点$v_i$和$v_j$的亲和度$w_{ij}$都考虑进去了,求出来的注意力值能够衡量global-graph上的邻居结点$v_j$和目标session序列是否相关,对目标结点的表征是否有用。softmax在$v_i$的所有邻居结点上求一个概率分布。这个注意力机制是此部分的主要亮点,intuition很符合我们的认知。剩余的步骤就是常规的加权邻域汇聚结点并叠加多层来提取global-graph上多阶的结点关系。
$$
\boldsymbol{h}_{\mathcal{N}_{v_i}^g}=\sum_{v_j \in \mathcal{N}_{v_i}^g} \pi(v_i,v_j)\boldsymbol{h}_{v_j}
$$
$\boldsymbol{h}_{\mathcal{N}_{v_i}^g}$是从邻域结点传播到目标结点的信息。
信息汇聚:和自身的信息融合起来。拼接在一起过一个非线性变换。
$$
\boldsymbol{h}_{v_i}^g=\text{Relu}(\boldsymbol{W}_2[\boldsymbol{h}_{v_i}||\boldsymbol{h}_{\mathcal{N}_{v_i}^g}])
$$
上述步骤可以抽象成一个agg函数,叠加多层网络提取多阶关系,递推式:$\boldsymbol{h}_{v_i}^{g,(k)}=\text{agg}(\boldsymbol{h}_{v_i}^{g,(k-1)}, \boldsymbol{h}_{\mathcal{N}_{v_i}^g}^{g,(k-1)})$。
3.2.2 Session-level物品表征
session-level的物品表征就是从session-graph中和目标结点$v_i$相邻的邻域结点$v_j$中提出信息。这里头的主要亮点就是注意力机制的设计。在计算序列中结点之间的attention值时,attention的设计考虑了结点之间的4种连边类型(即:出度,入度,自连接,双向),即:edge-type specific attention机制。这个是和基于SR-GNN的工作的差异点之一。SR-GNN基于出度和入度邻接矩阵来算每个结点的贡献度,而不是根据attention机制。
$$
\boldsymbol{\alpha}_{ij}=\text{softmax}(\text{LeakyRelu}(\boldsymbol{a}_{r_{ij}}^T (\boldsymbol{h}_{v_i} \odot \boldsymbol{h}_{v_j})))
$$
$r_{ij}$是序列中的两个结点$v_i$和$v_j$连边类型,$\boldsymbol{a}_{r_{ij}}$是该连边类型特定的参数向量。根据该注意力值加权汇聚邻域结点。由于有自连接边,所以加权汇聚的过程中实际上相当于同时做了信息传播和信息汇聚。
$$
\boldsymbol{h}_{v_i}^s=\sum_{v_j \in \mathcal{N}_{v_i}^s} \alpha_{ij} \boldsymbol{h}_{v_j}
$$
作者在session-graph上只提取了一阶的结点关系,即:上述步骤只进行1次。
最终,每个结点的表征是global-level的表征和session-level的表征sum pooling的结果,即图中加号的部分。具体而言,作者对global-level的表征加了一层dropout来防止过拟合。即:
$$
\boldsymbol{h}_{v_i^s}^{\prime}=\text{dropout}(\boldsymbol{h}_{v_i}^{g,(k)}) + \boldsymbol{h}_{v_i}^s
$$
3.3 序列表征
得到了序列中每个结点的表征后,需要对序列中的每个结点表征进行汇聚,从而形成序列表征。主要包括几个关键点:
结点的位置信息很重要,即位置ID的嵌入。故:首先在序列结点$v_i$的表征$\boldsymbol{h}_{v_i}^{\prime}$中融入了位置信息。位置编码包括顺序编码和逆序编码,二者存在差异的原因主要在于,不同序列的长度是不一样的。因此肯定会设置一个最大编码长度参数,大于这个最大编码长度的就是取默认编码值。此时,顺序编码会导致部分长序列末尾的位置编码都是默认值,逆序编码会导致部分长序列头部的位置编码都是默认的。作者特意强调了逆序编码更有用。符合认知。
$$
\boldsymbol{z}_i=\text{tanh}(\boldsymbol{W_3}[\boldsymbol{h}_{v_i^s}^{\prime} || \boldsymbol{p}_{l-i+1}]+\boldsymbol{b}_3)
$$
$\boldsymbol{p}_{l-i+1}$就是位置的嵌入,$l$是最大编码长度。然后对序列中的结点表征作mean pooling得到session information,可以认为是这个session序列浓缩后的信息。
$$
\boldsymbol{s}^{\prime}=\frac{1}{l}\sum_{i=1}^l \boldsymbol{h}_{v_i^s}^{\prime}
$$这个session information作为序列attention的trigger去和序列中的每个结点做soft attention,得到表示每个结点对序列表征的贡献度值。作者称这种注意力机制为position-aware attention($\boldsymbol{z}_i$中融入了位置信息)。这个和基于SR-GNN的工作是比较大的差异点,SR-GNN中用的last item作为trigger去做attention。
$$
\beta_i=\boldsymbol{q_2}^T\sigma(\boldsymbol{W}_4\boldsymbol{z_i} + \boldsymbol{W}_5 \boldsymbol{s}^{\prime}+\boldsymbol{b}_4)
$$
- 根据该值加权每个结点的表征,最终得到序列的表征。
$$
\boldsymbol{S}=\sum_{i=1}^l \beta_i \boldsymbol{h}_{v_i^s}^{\prime}
$$
3.4 预测层
最后的预测层很简单,预测下一次交互,多分类问题。序列表征和物品初始表征做点击,再softmax,得到该物品是下一次交互的概率值。
$$
\hat{y}_i=\text{softmax}(\boldsymbol{S}^T \boldsymbol{h}_{v_i})
$$
最后训练的时候用交叉熵损失。上述公式写成矩阵形式就是$\boldsymbol{S}$和物品的初始嵌入矩阵$H$做点击,得到在所有物品上的概率分布。
Evaluation
- 对比实验:对比了很多序列推荐的方法。包括早期的GRU4Rec,还有比较新的SR-GNN,CSRM,FGNN等。可以看出,赢了SR-GNN还挺多的。
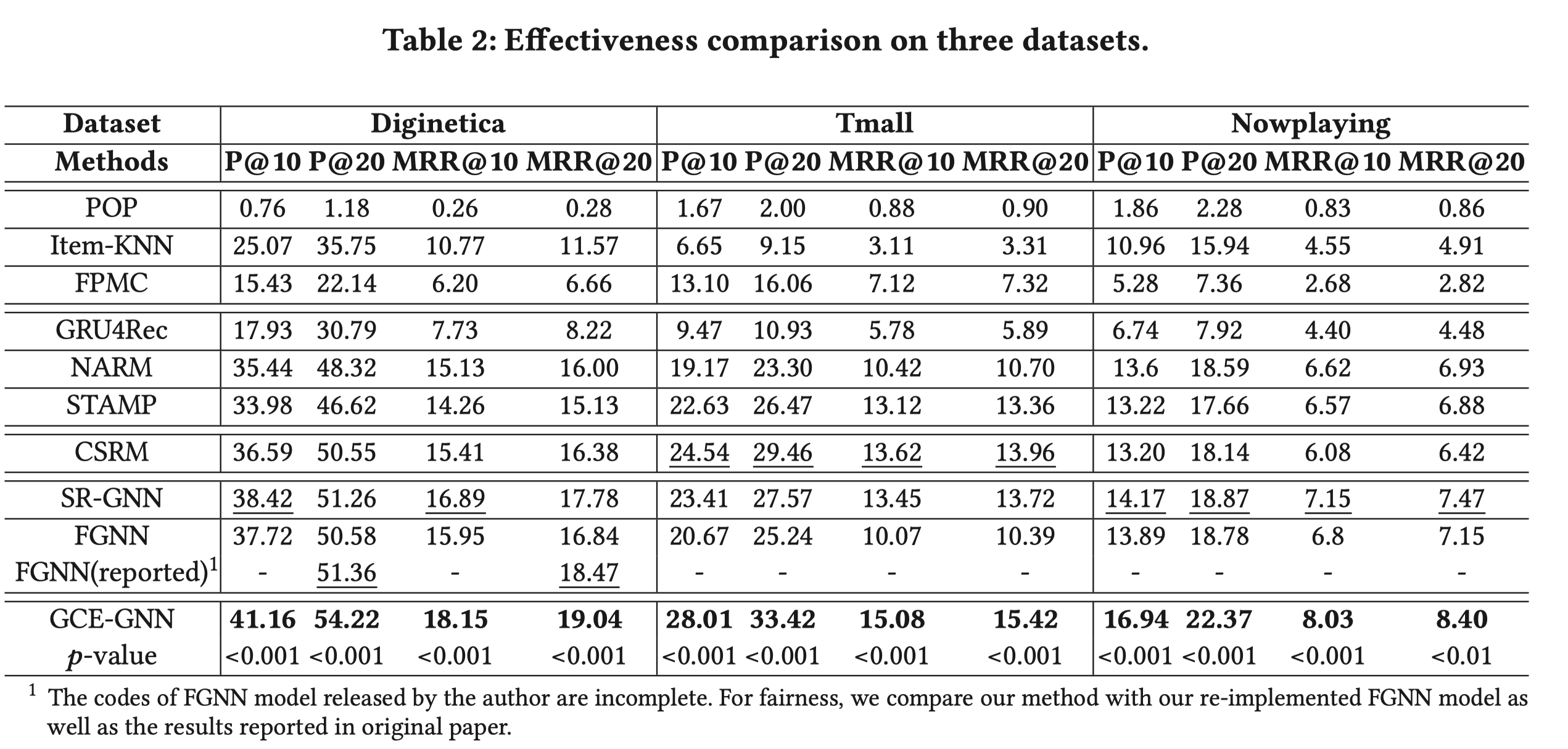
- 消融实验:主要考察的点包括:global-graph(存在与否),session-graph(存在与否),global-graph的阶数(1-hop, 2-hop),位置编码(顺序+逆序),global-level和session-level的表征的汇聚方式(文中是简单的sum pooling,作者还对比了gate,max,concat等),dropout。
Summarization
这篇文章总体上还是有值得借鉴的地方。比如从所有的session序列中构造全局图,这样能够通过借助其它session的信息来辅助目标session的表征。为了能够从全局图中提取相关的信息,作者提出了session-aware注意力机制来自适应地选择相关的全局信息。另一方面,针对由目标session序列构造而来的局部图,文章的核心贡献包括序列中结点之间edge type specific的注意力机制来进行邻域信息汇聚;为了得到整个session序列的表征,需要计算每个结点对序列表征的贡献度,大部分工作会用最后一个item去和每个结点做attention,而这篇文章,作者用整个序列浓缩后的信息去和每个结点做attention,且该attention机制是position-aware的。这些亮点都能作为独立的组件去改进原来的基于GNN的序列推荐方法,都值得在实践中去尝试。
Reference
- Wang Z, Wei W, Cong G, et al. Global Context Enhanced Graph Neural Networks for Session-based Recommendation[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020: 169-178.
- CODE:https://github.com/johnny12150/GCE-GNN

