最近在调研内容理解相关的工作,发现了KDD 2019上,腾讯和阿尔伯塔大学刘邦大佬[2]合作的工作 A User-Centered Concept Mining System for Query and Document Understanding at Tencent [1],以用户为中心的概念挖掘系统在查询和文档理解中的应用。这篇文章信息量非常大,是一篇非常偏实践性的文章,值得深读。网上关于这篇文章的介绍主要是参考文献[3,4],其关于背景和技术的介绍比较到位,但是对整个工作脉络以及关键技术细节的梳理不太够。故借此机会,主要按照原文的行文思路,重新梳理下整个工作流程以及一些在内容理解中可能会用到的关键技术。
欢迎关注我的公众号”蘑菇先生学习记”,更快更及时地获取关于推荐系统的前沿进展!

1.Motivation
概念(Concept)蕴含着世界知识,指导着人类认知的发展。从海量的web文档中挖掘概念并构建相应的标签体系在文本理解领域是非常重要的研究问题。但是目前为止,大部分工作都是从百科或者网页文章中提取通用、浅层、粗粒度的概念,和用户认知视角以及用户兴趣并不一致。举个例子:”丰田4Runner”是一款”丰田SUV”(浅层概念),但用户可能更感兴趣的点在于:”底盘高的汽车”或者”越野型汽车”。为此,这篇文章提出了ConcepT概念挖掘系统,通过海量的用户查询和搜索点击日志,能够挖掘以用户为中心、符合用户兴趣的概念。进一步,作者提出了一种文档概念标签打标的方法并构建了topic-concept-instance的三级标签体系,应用于腾讯QQ浏览器的搜索引擎和新闻feeds推荐系统中,能够有效提高feeds的分发效率和搜索引擎的用户体验。
2. Contribution
核心的工作包括如下几个部分:
候选概念挖掘。从海量的query日志中挖掘候选的概念。包括了两种无监督策略和一种监督策略。
无监督策略,(1) 基于模式匹配的自助法。通过预定义的pattern来找到新的概念;同样,通过新的概念来反向补充和丰富pattern池;进一步,通过新发现的pattern,继续去找新的概念。周而复始,可以发现很多概念。(2) 查询词-标题对齐法。核心假设在于是query中重要的概念一定会在用户点击的文档标题中反复出现。这样可以从标题中挖掘出用户意图导向的概念。
监督策略,基于无监督方法挖掘出来的种子概念集构造监督训练集,训练一个CRF序列标注模型和质量判别模型。质量判别模型用于控制CRF抽取的concept的质量。
文档概念打标。包括了两种方法。 (1) 基于匹配的方法。挖掘文档的关键实例(key instances),然后基于key instances和concept之间的匹配,前提是key instances和concept之间是isA关系,且出现在已经构建好的标签体系中。(2) 基于概率推断的方法。基于key instances的上下文词相关的concept,来给文档打标,主要解决concept未出现在文档中的情况。比如:一篇文档中的关键词包括:芹菜,全麦面包,番茄,那么可能可以推断出”减肥饮食”的概念标签。
标签体系构建。 三层标签体系。topic-concept-instance,主题-概念-实例。三者之间的关系是isA。
在QQ浏览器的搜索推荐场景上都取得了好的离线和线上效果。
- 搜索:query概念化,基于抽取的concepts和分类体系来进行query理解。在实验中”用户体验调研”部分有显著提升。
- 推荐:feeds流推荐,提高了曝光的效率和时长。在实验中”线上AB test”部分有显著提升。
3. Solution
总体上对方法做个梳理。
- 首先从query和doc的title中挖掘出concepts。挖掘的方法包括无监督的模式匹配以及有监督的序列标注模型CRF。在3.1节进行详细介绍。
- 其次,concept质量控制。用质量控制模型对候选concepts做个清洗。最终得到高质量的concepts池。在3.2节进行详细介绍。
- 接着,要给doc打上挖掘好的concept标签。打标的方法是:先基于GBRank+基于词向量的TextRank方法,抽取doc的key instances (即关键词);然后计算key instances和concept之间的关联性,选择关联性高的concept作为doc的标签。计算关联性的时候用到了两种,强isA关系的匹配法(基于规则挖掘的concept和instance的isA关系池),以及概率推断方法(基于instance上下文词和concept之间的关联性来推断)。在3.3节进行详细介绍。
- 最后构造topic-concept-instance三级标签体系。其中topic是人工预定义的31种标签,用多分类模型来给doc打上topic,而第二步中已经给doc打上了concept,即:doc作为topic和concept之间的桥梁,从而可以得到topic和concept的关系。concept和instance的关系通过规则匹配或者语义匹配分类器的方法得到。在3.4节进行详细介绍。
3.1 概念挖掘:Concept Mining
先直观感受下从query中挖掘出来的概念。

再总体一览下三种挖掘概念的方法:从query以及title中挖掘概念。根据右侧图例来对照看。
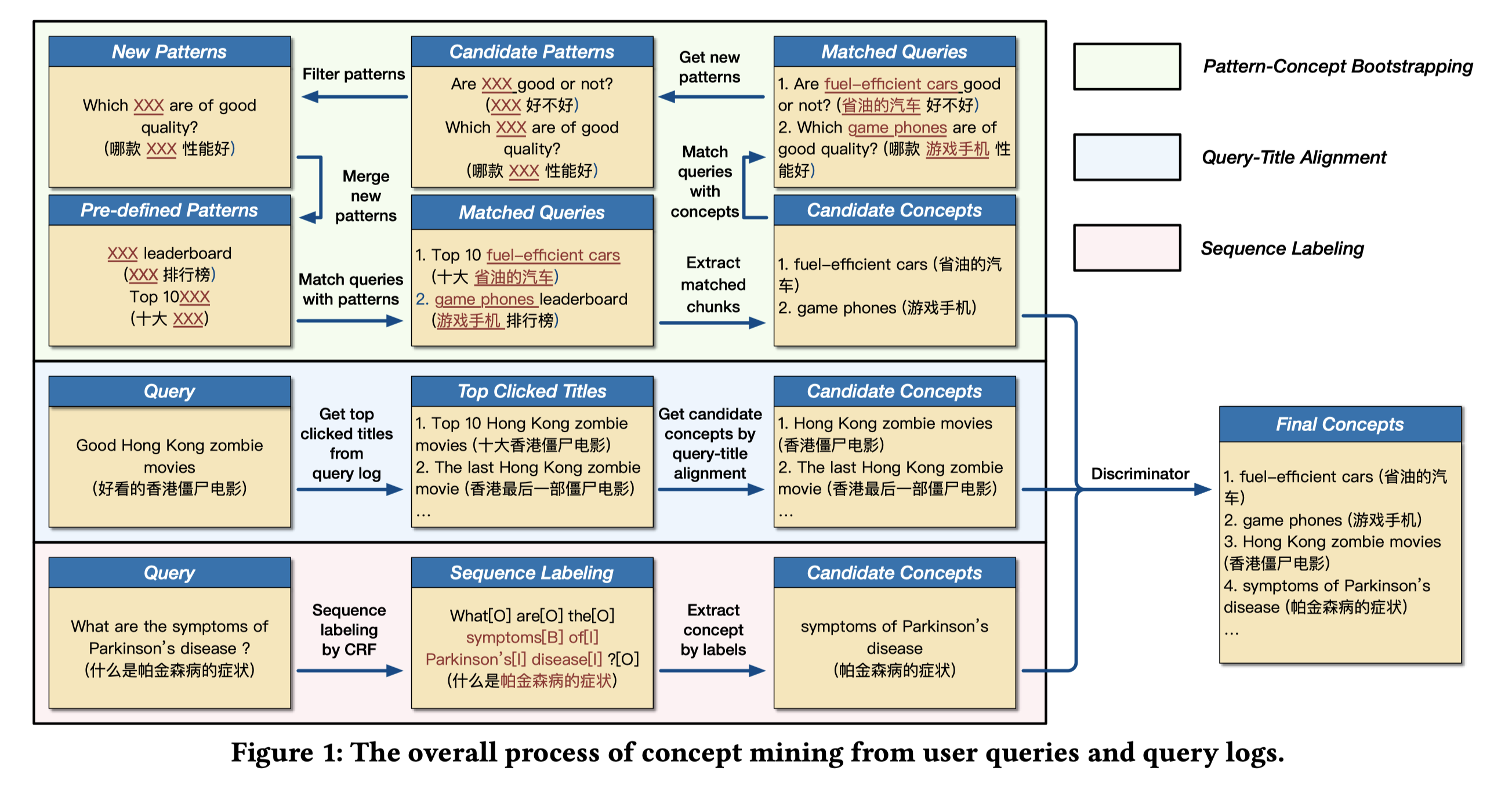
3.1.1 模式匹配自助法
英文是:Bootstrapping by Pattern-Concept Duality。目标是从query中抽取出符合模式的概念。如图1所示,最上面的一行。包括如下步骤:
- 基于预定义patterns抽取concepts。比如:XXX 排行榜,Top 10 XXX,十大 XXX,可以通过这个模式槽位抽取出一些概念,比如 “十大省油的汽车”中”省油的汽车”,”游戏手机排行榜“中”游戏手机”。
- 基于挖掘到的concepts发现新patterns。 基于挖掘到的概念”省油的汽车”和”游戏手机”,来观察语料中包含这些概念的其它query长什么样,能不能总结出一些新的patterns。比如:”省油的汽车 好不好” 总结出 “XXX 好不好“的pattern;”哪款 游戏手机 性能好” 总结出 “哪款 XXX 性能好“的pattern。
- 清洗并保留高质量的patterns。 新的patterns中可能包含很多噪声。比如:”XXX 好不好” 的pattern,包括”省油的汽车 好不好”,”每天跑步 好不好”等,显然”每天跑步”不是一个好的concept。一个好的pattern,一方面能够更多的命中已经挖掘好的种子concept;另一方面又能发现新的concept,但是不能过度泛化,命中很多无意义的词。解决方法是,对于某个轮次,给定一个新的pattern $\boldsymbol{p}$,令$n_s$是通过$\boldsymbol{p}$命中已挖掘的seed concept池中的concept的个数。$n_e$是通过$\boldsymbol{p}$挖掘的新concept的个数。$\boldsymbol{p}$会被保留当且仅当满足$\alpha < \frac{n_s}{n_e} < \beta$ 且 $n_s > \delta$。作者此处取$\alpha=0.6,\beta=0.8, \delta=2$。
- 基于新的patterns继续抽取concepts。基于新发现的patterns继续抽取concepts,周而复始。不断产生新的概念。
附录中还提到了,作者随机从1个月的搜索日志中抽取了15000条query,然后用模式匹配自助法抽取了一批concept,再经过腾讯的产品经理人工校验了一下。最终形成了一批种子concept集合,每个concept也记录了其来源的query,因此实际上也隐含着有一批种子query集合。
3.1.2 查询-标题对齐法
英文名是:Concept mining by query-title alignment。上述Boostraping法抽取能力太有限,精度很高,但召回率很低。查询-标题对齐法的目标是从query和top点击的titles中抽取出概念,即:利用了query和用户的点击行为中蕴含的doc标题信息。直觉来源在于,用户搜索的query中的concept通常是和用户点击的doc的title强相关。比如:用户的query是”好看的香港僵尸电影”,出来的doc的标题可能是”香港最后一部僵尸电影”或者”香港搞笑僵尸电影”。即:title能够更好地传达出query本身的语义信息和用户感兴趣的点。这个例子中,抽取到的concept为”香港僵尸电影”。那怎么抽取出这样的concept呢?
对每个query $q$,通过统计所有用户点击数据,获取top个点击的doc的title集合$T^q$。具体而言,作者统计了1个月内点击次数超过5次的title加入top title集合。
对每个query $q$和title $t \in T^q$,遍历序列获取所有的N-grams(存疑,字粒度还是词语粒度?推测是词语粒度)。
遍历query和title的所有子串,比较query的n-gram子串和title的m-gram子串,将title的子串选作候选的concept当且仅当 (1)title子串包含所有query子串中的词,且词之间相对的序都相同;(2) query子串和title子串各自的头部词相同,尾部词也相同。 比如:
query:”好看的香港僵尸电影”的子串”香港僵尸电影”;
title:”香港最后一部僵尸电影”的子串”香港最后一部僵尸电影”。
条件(1)满足,title子串包含了query子串所有词”香港僵尸电影”;条件(2)满足头部词”香港”相同,尾部词”电影”相同。因此,”香港最后一部僵尸电影“可以选作候选概念。当然这个候选概念粒度太细,后续质量控制会被过滤掉。
可以推测,上述query也是有一定的选取规则来把控质量的。比如从1.1中选出来的种子query集合对应的top titles中抽取。
3.1.3 监督序列标注法
英文名是:Supervised Sequence Labeling。训练一个CRF模型来标注带概念词的序列,包括query和title。监督标注数据的来源是前面两种方法,即boostrapping和query-title对齐法中挖掘到的概念。按照我的理解,序列标注监督数据是这么构造的:
boostraping方法的query序列:根据挖掘到的concept,就可以给原始query打上标注,concept词序列的起始词用B,中间词用I,其它词用O。比如:”十大游戏手机”中挖掘到concept为:”游戏手机”。那么”十大游戏手机”的标注为:
1
2十 大 游 戏 手 机
O O B I I Iquery-title对齐方法的title序列。比如,query:”好看的香港僵尸电影”,title:”十大香港僵尸电影”,抽取到的concept为:香港僵尸电影。显然用上述方法,可以对query和title都打上标注。
有了序列标注数据,那么就可以训练CRF模型了。训练的时候,会提取序列中每个token的特征,比如词性、实体标签、上下文特征(e.g., 前后序词的词性pair)等。如下:

作者用CRF++ v0.58来训练,80%训练集,10%验证集,10%测试集。CRF对于那些有明显非概念词作为边界的短文本挖掘很有效,比如”省油的汽车有哪些?”中的概念”省油的汽车”。对于那些概念分散在多处的效果则一般,比如:”父母过生日准备什么礼物?” 的概念”父母生日礼物“。后者使用query-title对齐方法更好。(btw, 个人不认为这个例子query-title对齐方法能抽取出来父母生日礼物,query-title是基于n-gram匹配的,这个例子中”父母生日礼物”这个n-gram不符合3.1.2中的条件,即:title子串包含所有query子串中的词)。
3.2 Concept质量控制
英文名是:A Discriminator for quality control。上述方法挖掘出来的concept并不都是高质量的,有的粒度太粗,有的太细。比如:香港最后一部僵尸电影,粒度过细,很少有用户这么搜。因此,本部分主要为了训练一个质量判别分类器,用于判断抽取出来的候选概念短文本是否是合适且恰当的concept。
作者做了一个简单的分类器GBDT/LR,统计了每个候选concept的一些特征,比如:是否出现在某个query中,被搜索多少次,文本词袋向量,query对应的用户点击文档的主题分布等。具体的特征如下表所示:

上述数据的标签是人工标注的。作者说只需要300个样本就能够训练一个好的分类器。这有点不可思议。说明存在超强特征,比如被搜索的次数等。但个人仍然存疑。
3.3 文档打标:Document Tagging
先直观感受下打标的例子。如下图所示,第二条新闻打上了油耗低的车这以concept。

下图是整个文档打标的流程图。包括了keyword instances抽取,再基于key intances和concept二者之间的关联来打标,打标的方法包括:基于匹配的打标和基于概率推断的打标。
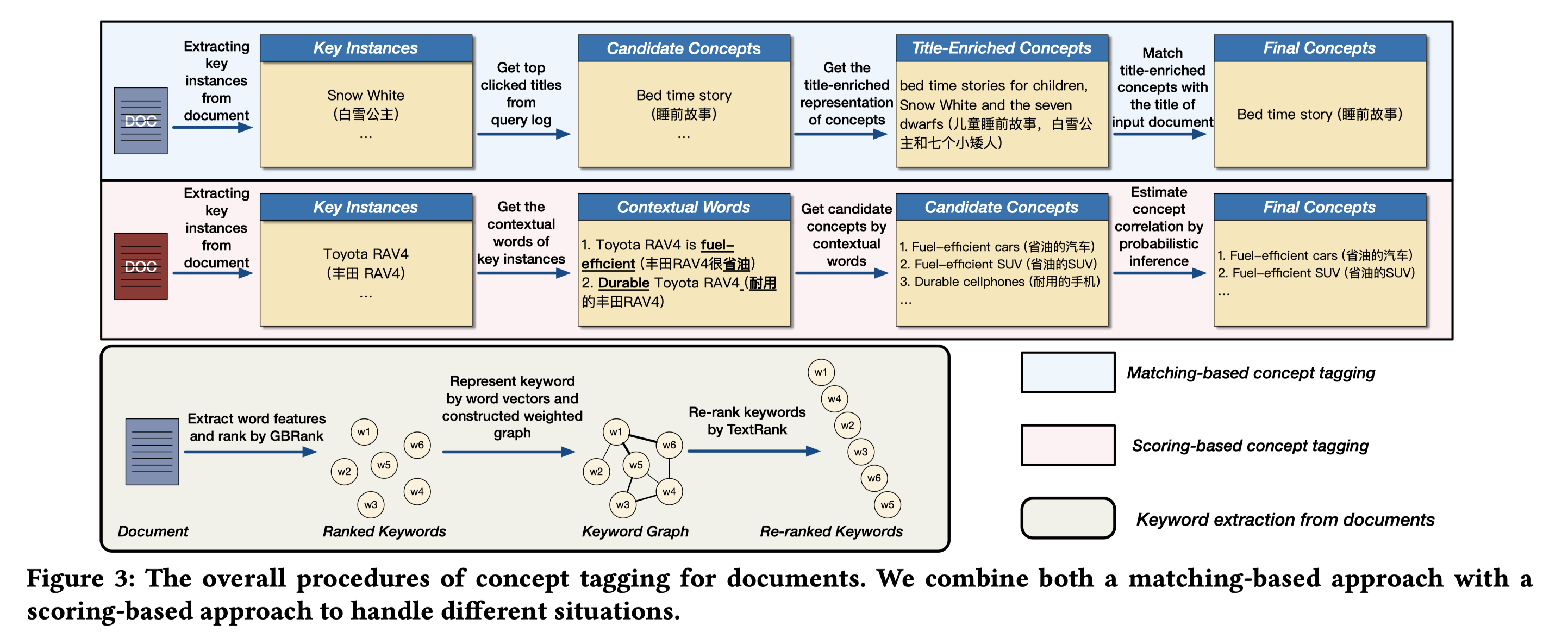
3.3.1 文档Key Instance 抽取
上图3左下角部分对应key instance的抽取过程。
先基于监督方法GBRank[4]对文档的words进行排序,GBRank是一种pair-wise的排序学习方法,主要是基于doc - key instance pairs数据来训练,输入的特征包括词频、词性、实体等信息。这部分重点是doc-key instance pairs怎么来?文中没仔细说明。下表是输入特征。

对TopK(原文取10)排序好的词进行词向量表征,用到方法[5]。这部分用word2vec,GloVe,BERT等词向量个人认为也是可行的。
对TopK的词,基于词向量之间的cosine相似性构造带权无向图。
使用TextRank[6]无监督方法来做重排序并打分。
保留分数大于$\delta_{w}$(原文取0.5)的关键词,作为抽取到的doc的key intances。
作者的经验是,采用GBrank和基于词向量的TextRank能够很好地抽取出和doc主题一致的关键词。
3.3.2 概率推断打标法
基于概率推断的打标法,核心问题在于估计$p(c|d)$,其中$c$是待打的concept,$d$是待打的doc。作者做了两步的链式法则拆解:
第一步:用key intances来表示$d$;第二步,用key instances的上下文词来代表key instances。
首先是第一步,用key intances来表示$d$,则可以根据链式法则拆解$p(c|d)$为:
$$
p(c|d)=\sum_{i=1}^{|E^d|} p(c|e_i^d) p(e_i^d|d)
$$
其中,$E^d$是doc $d$的所有key instance集合。$p(c|e_i^d)$衡量了key instance $e_i^d$和concept $c$之间的关联性;$p(e_i^d|d)$则衡量了doc $d$和key instance $e_i^d$之间的关联性,可以用$e_i^d \in E^d$在$d$中词频分布来表示。因此核心问题转成了:如何表示 $p(c|e_i^d)$。
第二步,作者进一步用链式法则,用key instance $e_i^d$的上下文词和$c$的关联性来表示,
$$
p(c|e_i^d) = \sum_{j=1}^{|X_{E_d}|} p(c|x_j) p(x_j | e_i^d)
$$
$X_{E_d}$是key instance $e_{i}^d$的上下文词的集合,$p(x_j|e_i^d)$正比于上下文词$x_j$和$e_i^d$之间的共现概率。如果两个词出现在1个句子中,则共现。因此,可以求$x_j$和$e_i^d$同时出现在一句话中的次数,除以$e_i^d$出现总次数,来求$p(x_j|e_i^d)$。
因此,问题转成了求 $p(c|x_j)$,即:concept $c$和上下文词$x_j$的关联性。这个关联性作者用字符串的匹配程度来表示,即:如果上下文词$x_j$包含在$c$的某个子串中,则存在关联。比如concept为”省油的汽车”,上下文词为”省油”,则”省油的汽车”包含”省油”。为了估计$p(c|x_j)$,就去看包含$x_j$子串的concept集合$C^{x_j}$大小,这个集合中的concept平分这个概率,不包含$x_j$的concept则概率为0。
$$
p(c|x_j) = \frac{1}{|C^{x_j}|}, x_j为c的子串
$$
3.3.3 基于匹配打标法
这种方式在key instances和concept存在isA关系时使用。首先定义isA的关系。concept和instance之间的isA关系。根据concept的修饰词和query(或title)中的修饰词的对齐来抽取。比如:某个concept是”省油的汽车”,抽取包含”省油的”修饰词的query(或者title),比如”省油的丰田RAV4”,从中抽取到instance “丰田RAV4”,这样instance”丰田RAV4”和concept”省油的汽车”之间就是isA关系。concept和instance的isA关系可以提前算好。当然,通过这种规则后,可能还需要人工检查或者进一步做语义匹配建模。
有了isA关系后,接着介绍基于匹配打标法。给定:doc文档title,doc文档的候选key instance集合,以及每个key instance对应的isA的concept集合,目标是去给doc打上某个concept标签。
根据key instance获取isA对应的concept:比如:某个doc的key instance为”白雪公主”,对应的isA的concept为”睡前故事”,”童话故事”。
丰富concept的表示:对每个候选的concept,作者用top 5用户点击的链接的title(应该是concept的来源title)来丰富其表示,即:concept和top5 title拼接在一起,比如: concept:”睡前故事”;top的title:”儿童睡前故事”,”白雪公主和七个小矮人”。二者拼接在一起,睡前故事, 儿童睡前故事, 白雪公主和七个小矮人,…。并用TF-IDF向量来表示,即:所有词典上每个词的tf-idf值构成的向量,维度为词典大小。”童话故事”也同理。可以获得每个concept的tf-idf向量。
- 文档标题document title也获取tf-idf向量表示。
- 计算丰富后的concept的表示和document title表示的cosine相似性,大于某个阈值$\delta_u$(作者取0.58)则打上该concept标注。
这种方法和3.2的区别在于,3.2中找不到key instance和concept之间的isA强关联关系,退而求其次,用key instance的上下文词和concept之间关联关系来间接表示。3.3中,因为key instance和concept之间存在isA强关联关系,因此要合理利用。即:先找到key instance的isA关系的concepts,如果key instance抽取得更好,理论上可以直接打上该concept标签。但是作者做了进一步的校验,用title-enriched的concept的tf-idf向量和doc的title的tf-idf向量相似性来做限定,核心假设在于key instance如果够好,应该传达的主题和title是近似的,因此用instance的isA关系的concept和title做了相似性校验。
3.4 标签体系构建
作者构造了3级标签体系,即:主题-概念-实例,topic-concept-instance。其中,
- topic:31种,预定义的分类主题,如娱乐,技术,社会等。
- concept:20W,前文挖掘到的用户为中心的概念。其中,4W concept至少包含1种instance,说明有16W不包含任何instance。
- instance:60W,前文提取的doc的关键实例。其中,20W instance至少与1个concept存在isA关系,说明40W不存在isA关系。
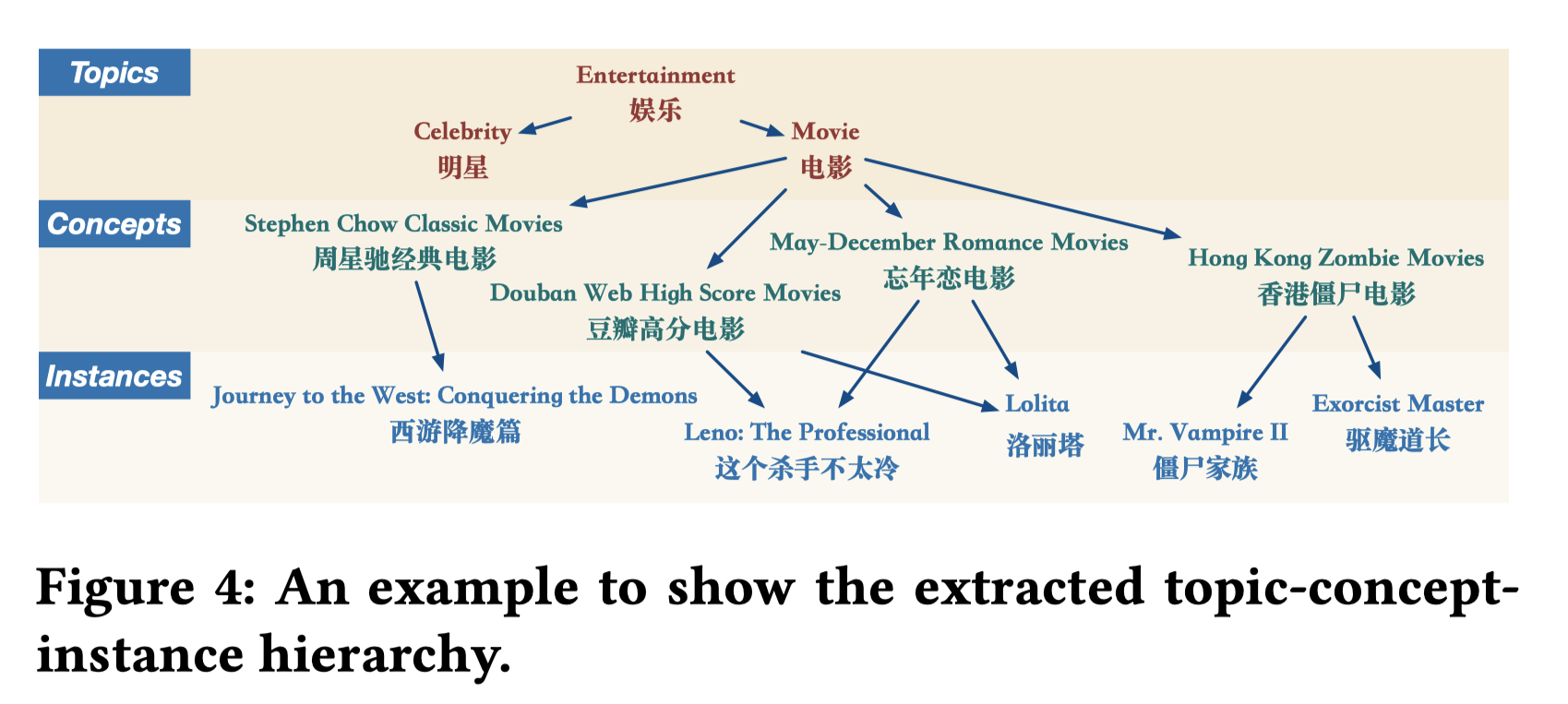
进一步细看图4中的三级分类体系,是一个有向无环图,有向边意味着isA关系。concept和instance之间的isA关系前文已经提到。剩下就是topic和concept之间的关系。作者采用的方法如图6所示,先用词向量+max pooling的方式表征doc(标题,作者,doc内容),再通过DNN模型来做主题的多分类任务,输出doc的分类。作者提到在一个35,000个新闻文章标注数据上可以达到95%的准确率。
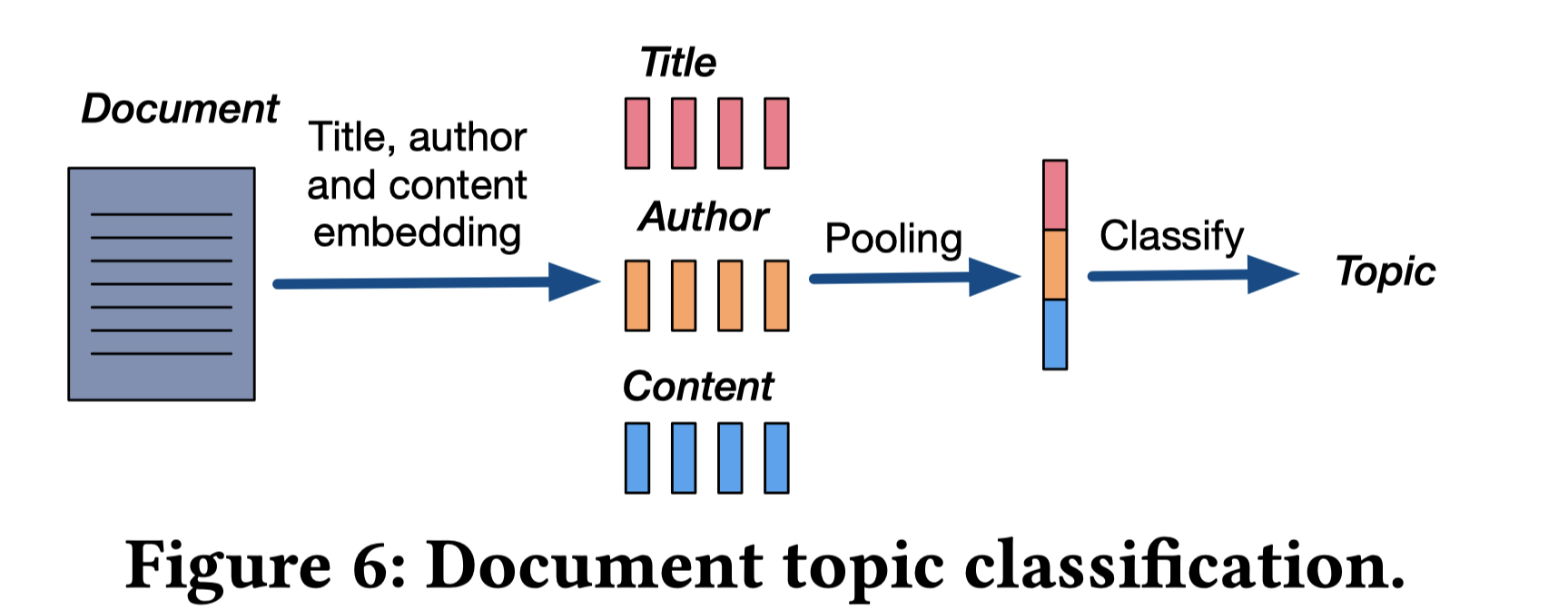
但现在的目标是求topic和concept的关系。怎么做呢?通过doc来做桥梁。
给定一个concept $c$和topic $p$,假设有$n_c$个doc包含了该concept标签,其中有$n_p^c$个文档属于主题$p$,那么可以估计$P(p|c)=n_{p}^c / n^c$,这个大于某个阈值$\delta_t$(作者取0.3)则认为该doc和该topic存在isA关系。
4.Evaluation
4.1数据
搞了一个开源的小数据集来做评估。User-Centered Concept Mining Dataset (UCCM),是从QQ浏览器的query日志中抽样的。数据开源在github [8],数据示意图如下:

4.2 concept挖掘对比实验
针对concept的挖掘,对比了如下几种keyword抽取的方法,
- 基于图的无监督方法: TextRank[6]
- 刘知远老师的工作,基于翻译模型: THUCKE [9]
- AutoPhrase[10] 著名的方法。基于通用知识库、并借助词性分词信息来做短语抽取。
- Q-Pattern,基于query规则模式匹配的方法。即:前文boostrapping方法中介绍的。
- T-Pattern,基于title的规则匹配方法。也是boostrapping方法,只不过从title抽。
- Q-CRF,从query中用CRF序列标注方法来抽取关键词。
- T-CRF,从title中用CRF序列标注方法来抽取关键词。
- QT-Align,Query-Title 对齐方法,上文介绍的对齐方法。
对于TextRank,THUCKE,AutoPhrase,输入:用户query和点击的title的拼接,输出top 5关键词或短语,选出和query词重叠最多的关键词或短语作为最终结果。
指标:完全匹配Exact Match(EM)和F1。EM就是看挖掘出的词和人工打标的词的完全匹配占比;F1看挖掘的词和人工打标的词之间的重叠tokens的比例。
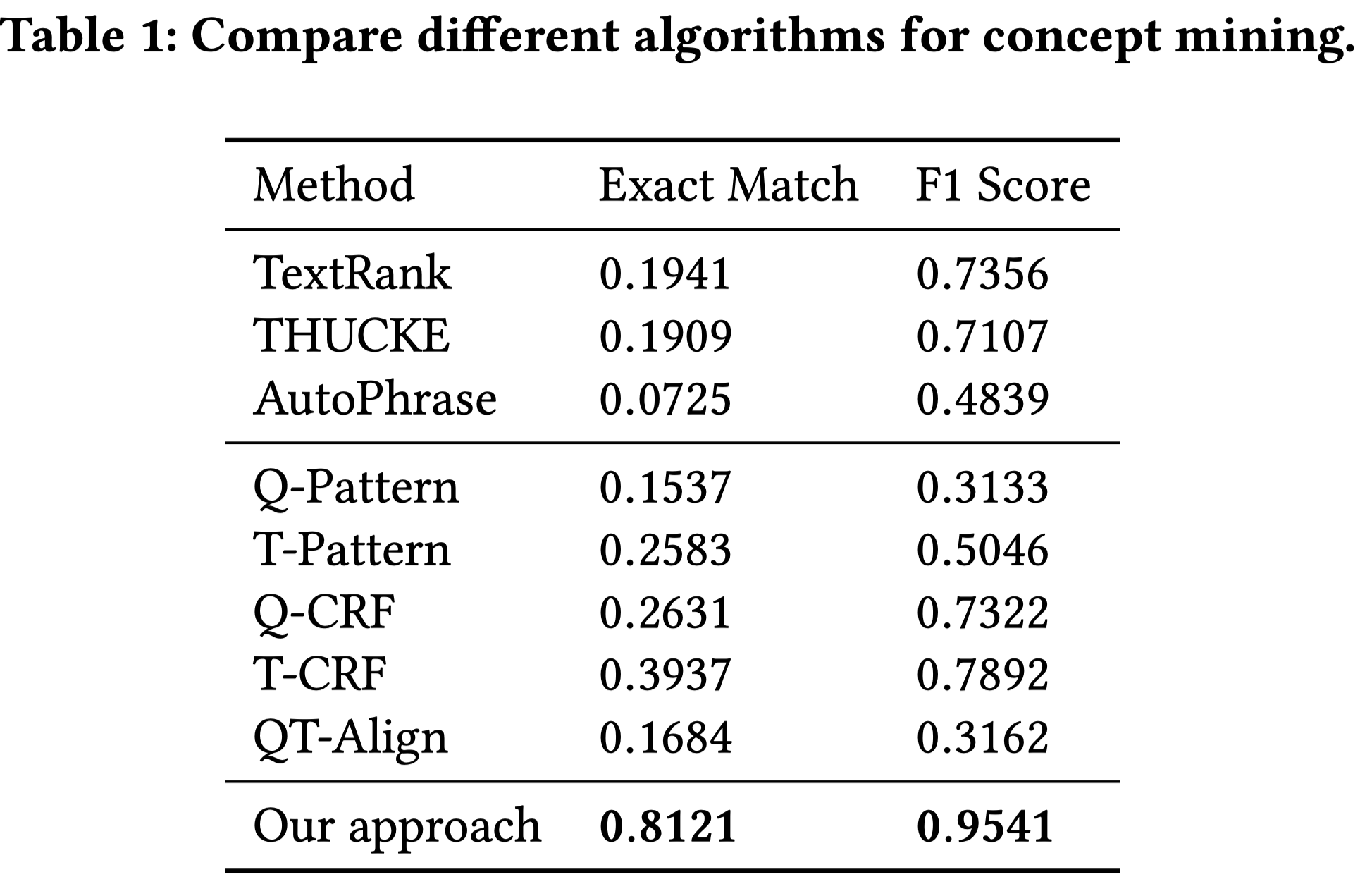
从表中结果可以看出差距很大。但是个人对对比方法的结果存在质疑。比如:AutoPhrase的结果这么差,是不是作者用的不恰当?作者解释是说这些方法适合从长文本中去提取,而本文的方法是适用于query/title的短文本中去提取。那么为什么不去对比适用于短文本抽取的方法呢?
4.3 文档打标签和类目体系评估
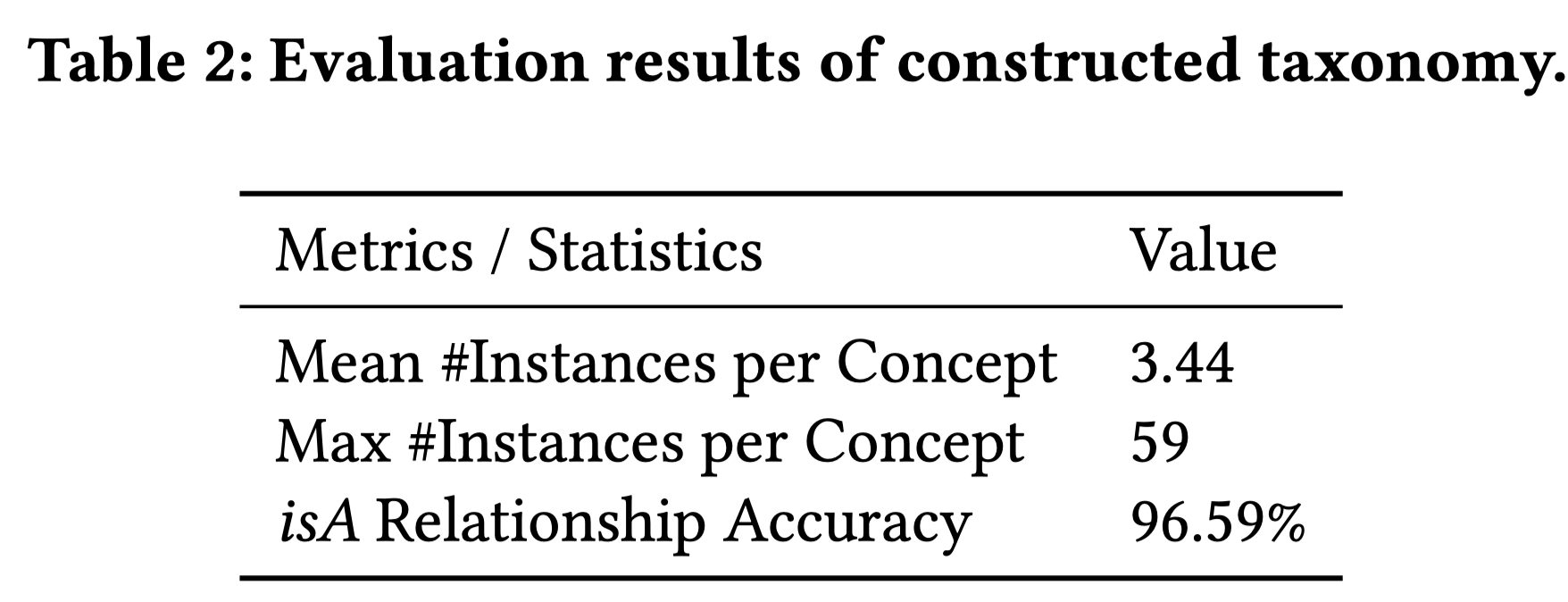
作者人工标注了一份doc和concept的数据,参见github [8]中的concept_tagging_data.txt。打标的精确率可以达到96%。

对于类目体系的评估,作者从这个体系中随机抽取了1000个concepts。作者只针对concept和instance之间的isA关系做评估,因为这二者的关系对于查询理解非常重要。此处的评估主要靠人工判断,判断是否是isA关系。准确率为96.59%。
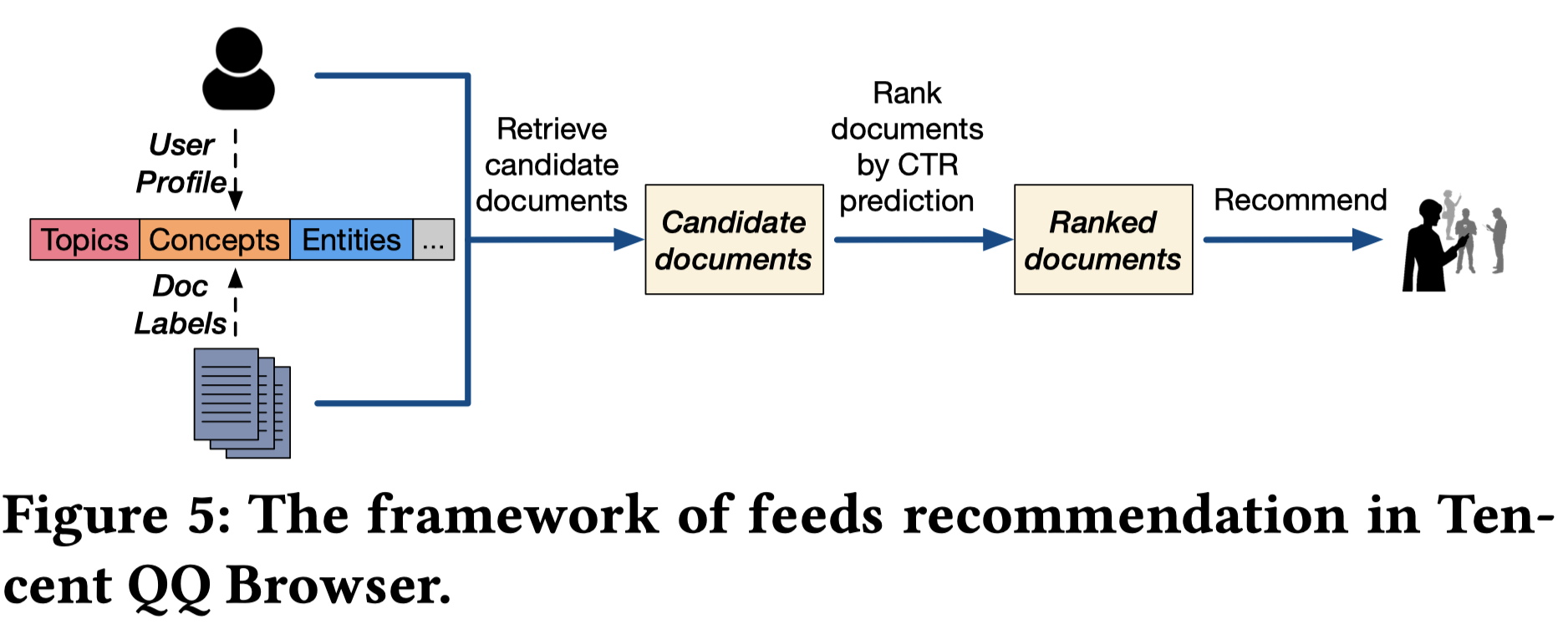
4.4 推荐场景:在线A/B测试
框架如下图所示,用户和文档都会打上topic,concepts和instances的画像信息。召回的时候,根据二者画像的匹配来做;然后用ctr模型来排序并推荐。
AB实验方法,将用户分桶,每个桶包括80W用户,观察每个桶的的多种指标:
- IPV:Impression Page View,曝光结果数。
- IUV:Impression User View,曝光用户数。
- CPV:Click Page View,点击结果数。
- CUV:Click User View,点击用户数。
- UCR:User Conversion Rate,用户转化率,$CUV/IUV$。
- AUC:Average User Consumption,人均点击数,$CPV / CUV$。
- UD:User Duration:人均在页面的停留时长,衡量了每个人每天花费了多少时间在app上。
- IE:Impression Efficiency,曝光效率,$CPV/IUV$,点击结果数除以曝光用户数,衡量了每个人每天读了多少内容。
从中选出两个上述指标最相近的桶,排除其他干扰因素,然后用这个两个桶做对比实验。1个桶用concept的文档标注做召回推荐,1个桶不用。跑了3天的线上实验,重点关注UD和IE。
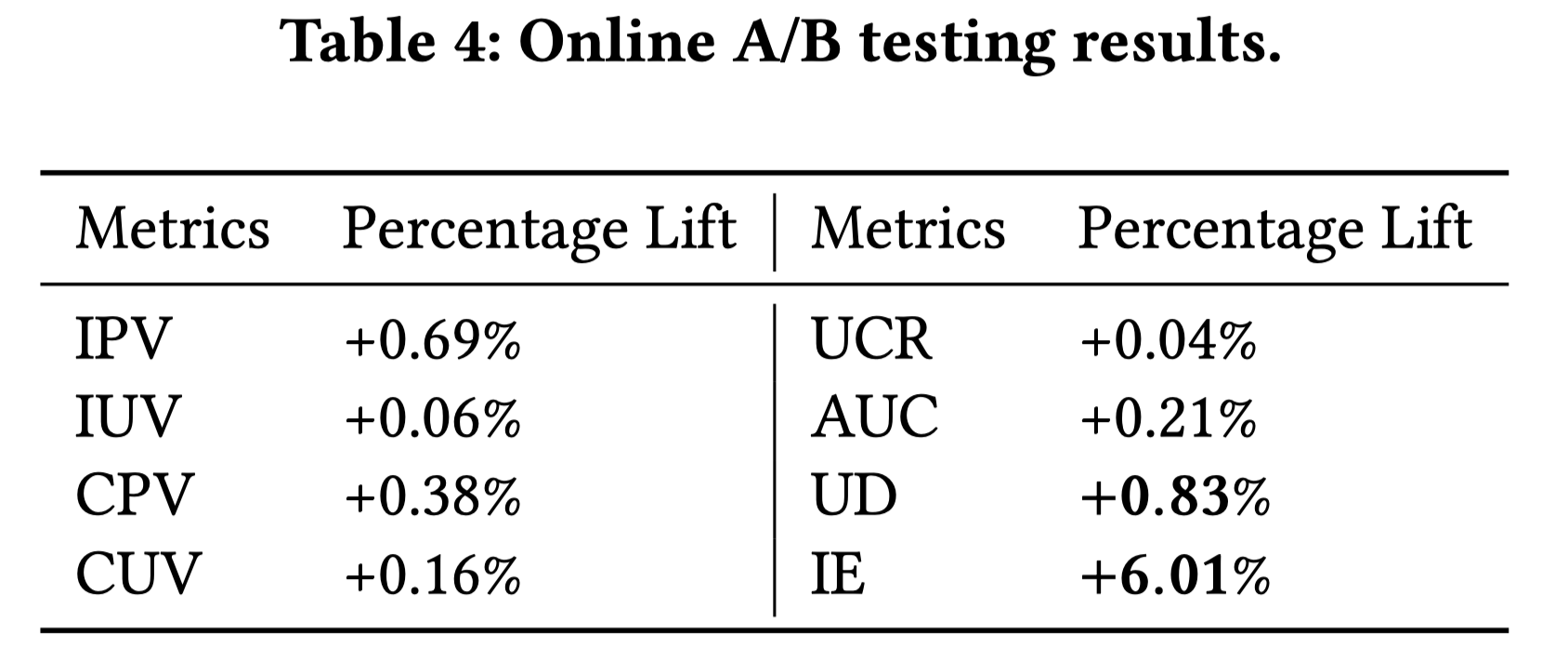
可以看出每个指标都涨了,尤其是IE。
4.5 搜索场景:离线用户体验调研
基于query改写来做离线的用户体验调研。挑了108个query,对每个query $q$,通过ConcepT系统分析出concept,然后取出该concept对应的isA关系的instances。对每个instance $e$,分别将原始query做改写,形如$q \ e$。然后用百度搜索来测试用户体验:
- 基准结果:原始query $q$返回top10个结果。
- 对比结果:所有改写的query $q \ e$ 返回top 10个结果,即:如果有K个instances,则每个改写的query返回$K/10$个结果,最后整合在一起。
作者找了3个人来判断query和结果的相关性。结论是经过改写,相关性从73.1%提高到了85.1%。原因是,concept能够辅助理解用户意图。
5. Summarization
这篇文章很偏工程化,比较适合落地实践。全文技术上的亮点很少,主要是成熟的技术、规则来结合具体的业务场景做定制和实践。但是,对于实践而言,这篇文章的信息量很丰富,很多行之有效的简单方法值得在内容理解,查询理解上应用。但是也不得不提,要想很好得借鉴和落地,需要非常强的领域知识,尤其是pattern的设计,因此仍然需要大量底层的工作,而无法直接借用文中开源的一些seed patterns。总而言之,是一篇真实应用落地的好文,但是离一把梭距离比较远,可以借鉴其中的一些思路做尝试。
参考
[1] A User-Centered Concept Mining System for Query and Document Understanding at Tencent:https://arxiv.org/abs/1905.08487
[2] KDD | 用户视角看世界:腾讯提出ConcepT概念挖掘系统,助力推荐搜索,https://cloud.tencent.com/developer/article/1458043
[3] 腾讯提出概念挖掘系统ConcepT-学习笔记,https://zhuanlan.zhihu.com/p/85494010
- [4] Zhaohui Zheng, Keke Chen, Gordon Sun, and Hongyuan Zha. 2007. A regression framework for learning ranking functions using relative relevance judgments. In SIGIR. ACM, 287–294.
- [5] Yan Song, Shuming Shi, Jing Li, and Haisong Zhang. 2018. Directional SkipGram: Explicitly Distinguishing Left and Right Context for Word Embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). ACL, 175–180. https://doi.org/10.18653/v1/N18-2028
- [6] Rada Mihalcea and Paul Tarau. 2004. Textrank: Bringing order into text. In EMNLP.
- [7] 基于TextRank算法的文本摘要:https://www.jiqizhixin.com/articles/2018-12-28-18
- [8] https://github.com/BangLiu/ConcepT
- [9] Zhiyuan Liu, Xinxiong Chen, Yabin Zheng, and Maosong Sun. 2011. Automatic keyphrase extraction by bridging vocabulary gap. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning. ACL, 135–144.
- [10] Jingbo Shang, Jialu Liu, Meng Jiang, Xiang Ren, Clare R Voss, and Jiawei Han.Automated phrase mining from massive text corpora. IEEE Transactions on Knowledge and Data Engineering 30, 10 (2018), 1825–1837.
也欢迎关注我的公众号”蘑菇先生学习记“,更快更及时地获取推荐系统前沿进展!

