概述
本文是对spark2.0.2分布式集群搭建的一个详细说明。旨在通过阅读该文章帮助开发人员快速搭建spark分布式集群。
三种集群资源管理概述
Spark Standalone
作为Spark的一部分,Standalone是一个简单的集群管理器。它具有master的HA,弹性应对WorkerFailures,对每个应用程序的管理资源的能力,并且可以在现有的Hadoop一起运行和访问HDFS的数据。该发行版包括一些脚本,可以很容易地部署在本地或在AmazonEC2云计算。它可以在Linux,Windows或Mac OSX上运行。Apache Mesos
Apache Mesos ,分布式系统内核,具有HA的masters和slaves,可以管理每个应用程序的资源,并对Docker容器有很好的支持。它可以运行Spark工作, Hadoop的MapReduce的,或任何其他服务的应用程序。它有Java, Python和C ++ 的API。它可以在Linux或Mac OSX上运行。Hadoop YARN
Hadoop YARN,作业调度和集群资源管理的分布式计算框架,具有HA为masters和slaves,在非安全模式下支持Docker容器,在安全模式下支持Linux和Windows Container executors,和可插拔的调度器。它可以运行在Linux和Windows上运行。
准备
装有centOS7的3台服务器
1
2
3master 172.16.21.121
node1 172.16.21.129
node2 172.16.21.130搭建hadoop集群环境
hadoop分布式环境搭建教程scala: scala-2.12.1.tgz
- spark: sprak-2.0.2-bin-hadoop2.7.tgz
- 上传sacala和spark到3台服务器
安装Scala
- 解压到/usr/local/scala
配置环境变量
1
2export SCALA_HOME=/usr/local/scala/scala-2.12.1
export PATH=$PATH:$SCALA_HOME/binscala -version查看版本
安装spark
- 解压
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz到/usr/local/spark 配置环境变量
1
2export SPARK_HOME=/usr/local/spark/spark-2.0.2-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin配置集群
master上:$SPARK_HOME/conf/slaves 添加:
1
2node1
node2spark-env.sh: 添加SCALA_HOME和JAVA_HOME
1
2export SCALA_HOME=/usr/local/scala/scala-2.12.1
export JAVA_HOME=/usr/local/java/jdk1.8.0_73修改spark web 默认端口为8081
1
2
3
4cd $SPARK_HOME/sbin
vim start-master.sh
if [ "$SPARK_MASTER_WEBUI_PORT" = "" ]; then
SPARK_MASTER_WEBUI_PORT=8081
启动
- 启动hadoop集群,master上执行
$HADOOP_HOME/sbin/start-all.sh - 启动spark集群,master上执行
$SPARK_HOME/sbin/start-all.sh jps查看
master:
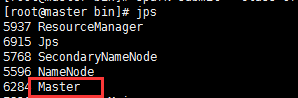
node1:
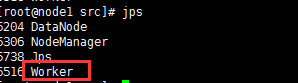
node2:
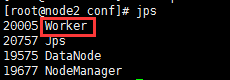
- 启动hadoop集群,master上执行
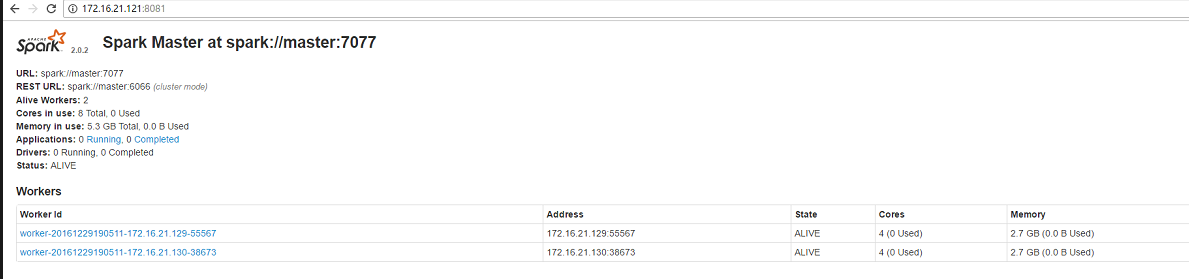
验证
- 访问master的8081
http://172.16.21.121:8081/
运行SparkPi例子
1
2cd $SPARK_HOME
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 examples/jars/spark-examples_2.11-2.0.2.jar 100 2>&1 | grep "Pi is roughly"
- 访问master的8081
参考
http://www.voidcn.com/blog/dream_broken/article/p-6319289.html

