本次双学位论文的题目是基于股评的情感分析和投资策略研究。阐述围绕四个方面展开,研究背景和内容、构建情感分析模型、构建时间序列预测模型以及总结展望。
研究背景
首先是研究背景。
本文的研究是基于股票市场,股市是一国经济的晴雨表,然而股市受政策、新闻、舆论的影响非常大,容易波动剧烈。因此对股市进行研究很有必要。
其次随着互联网新媒体的发展,人们越来越倾向于通过互联网平台来交流信息。实时股评中包含丰富的金融信息,体现投资者的情绪变化。因此对股市的研究可以考虑从股评入手进行挖掘分析。
最后新理论和技术的兴起。行为金融学使得对于股评的挖掘有了理论基础。文本挖掘、机器学习、时间序列模型等技术兴起使得股评挖掘成为了可能。
研究内容
因此本文的研究内容是,对股评进行情感分析并构建情感指标,结合股价建立时间序列模型,对股票走势提供一定的预测能力。这里面主要包含两方面的工作:
- 第一,构建情感分析分类模型,实现对股票评论情感倾向的快速判断。
- 第二,构建时间序列预测模型,对股市走势提供一定的预测能力。

构建情感分析模型
数据获取
首先是数据的获取。对于股评数据,选择东方财富网的“上证指数吧”提取股评数据。为此我专门使用Python语言设计了一款爬虫程序,爬取了3554页评论,时间跨度从2016-08-25到2017-3-15,共包含283905条股票评论。如图是其中几条股评以及设计的爬虫程序目录。
对于股票行情数据,使用开源财经接口包TuShare获取数据,采集的数据包括:日期、开盘价、最高价、收盘价、最低价、成交量、价格变动、涨跌幅等数据,实现对股票数据采集、清洗加工到存储的过程。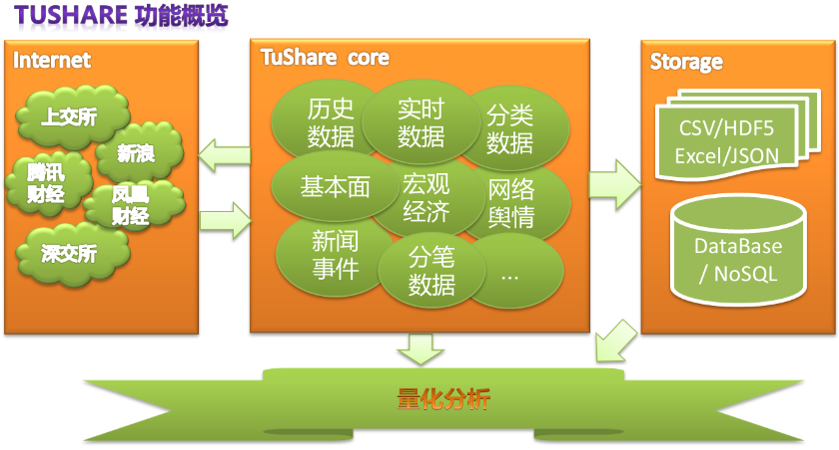
构建流程
接着是情感分析模型的构建流程。目标是构建一套情感分析和机器学习模型,挖掘股评中的情绪,实现对股票评论情感倾向的快速判断。
具体流程包括使用有监督机器学习分类方法、使用向量空间模型来进行文本表示、使用中文分词对句子进行切分,使用卡方统计量作为特征选择的指标、使用文本挖掘算法进行模型训练。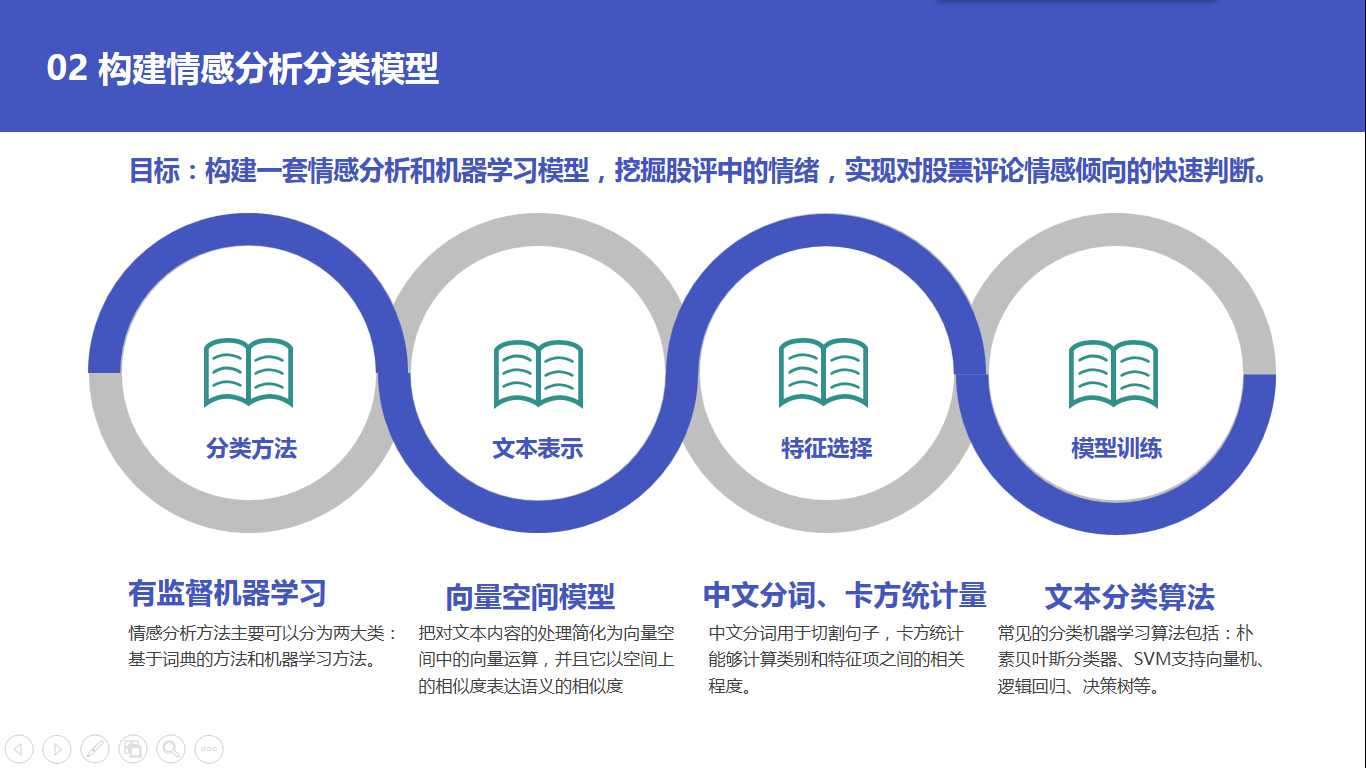
在构建过程中,首先我人工标注了5000条左右的看涨看跌数据,然后将数据集进行划分,3份作为训练,1份作为测试。最后进行模型训练以及使用多种指标在测试集上进行评估。如准确率、召回率等。如图,这是特征选择时得到的有用的特征项。可以看到“跑”这个词很大程度上反映了看跌股评。
下图是不同模型得到的指标。可以看到基于多项式的贝叶斯估计分类器在各项指标上综合表现最好,准确率得到了90%。我们选择该分类器来对28万多条的股评进行看涨看跌倾向判断。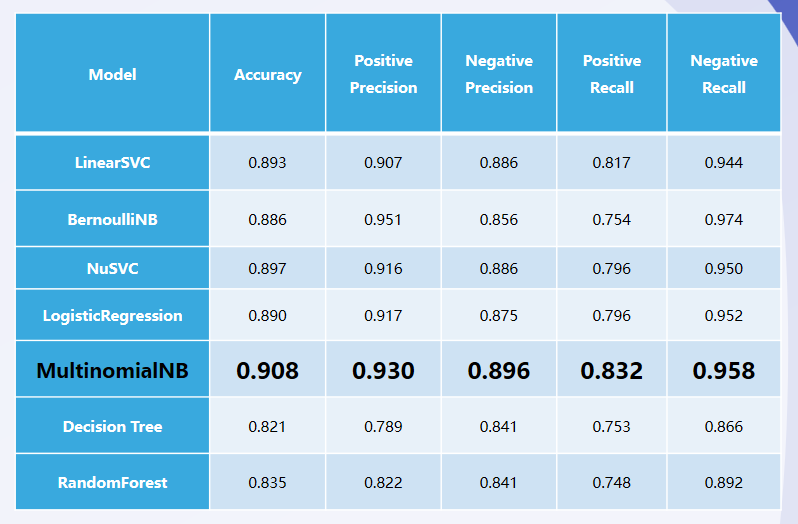
构建时间序列预测模型
指标选择
首先是指标的选择。对于情感指标,本文选择看涨指数。计算得到以日为单位的情感指标时间序列数据。如下公式所示:
$$BI=ln(\frac{1+M^{bull}}{1+M^{bear}})$$
对于股票指标,选择收盘价和涨跌幅进行研究。得到以日为单位的收盘价和涨跌幅时间序列数据。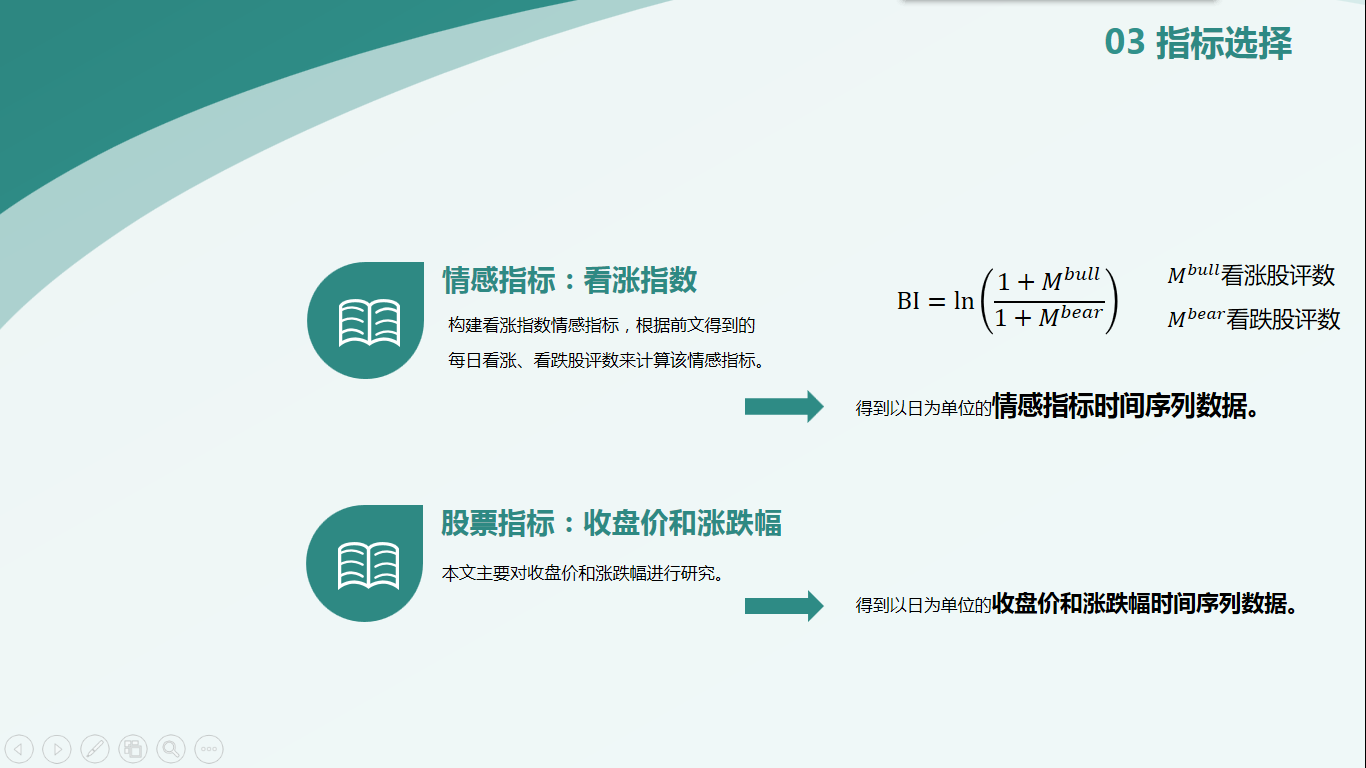
基于股票价格的股票预测模型
首先是基于股票价格的股票预测模型。这里面先不考虑情感指标,单纯的基于股票价格。具体的构建步骤包括:
平稳性检验。使用ADF单位根检验。如下图是原始的收盘价时间序列,明显有个趋势,检验结果p值大于显著性水平也表明序列不平稳。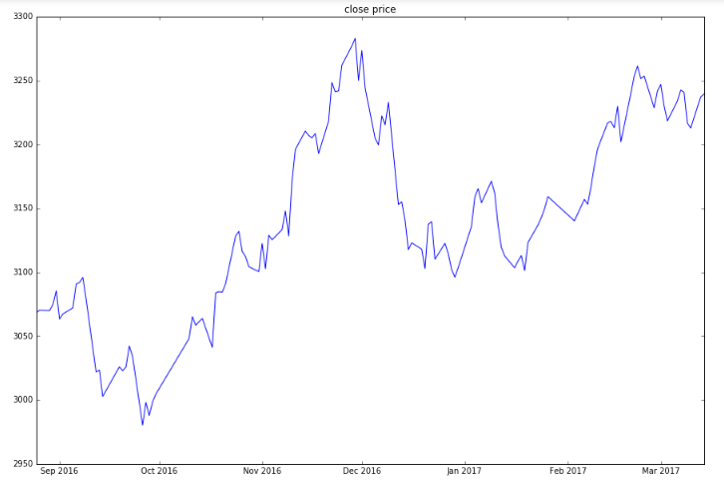
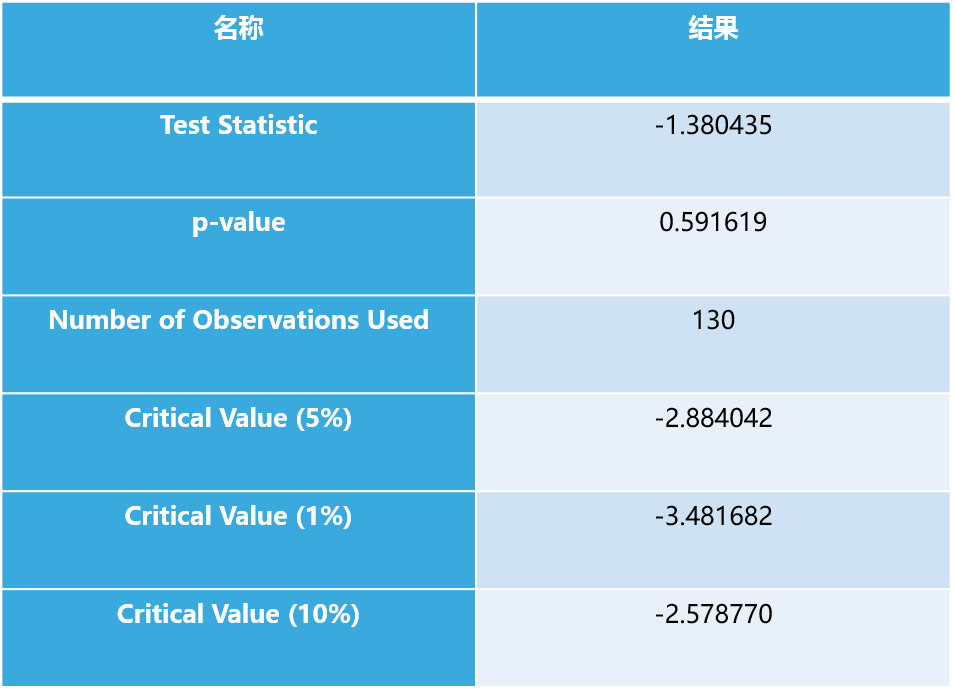
进行一阶差分后,进行ADF检验,发现序列已经平稳了。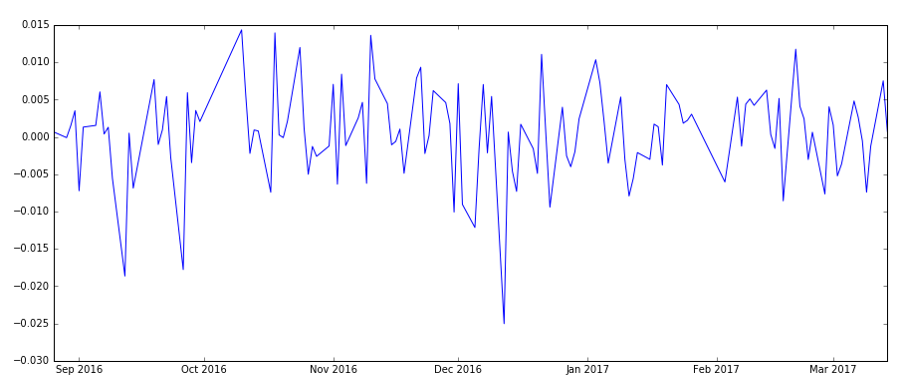
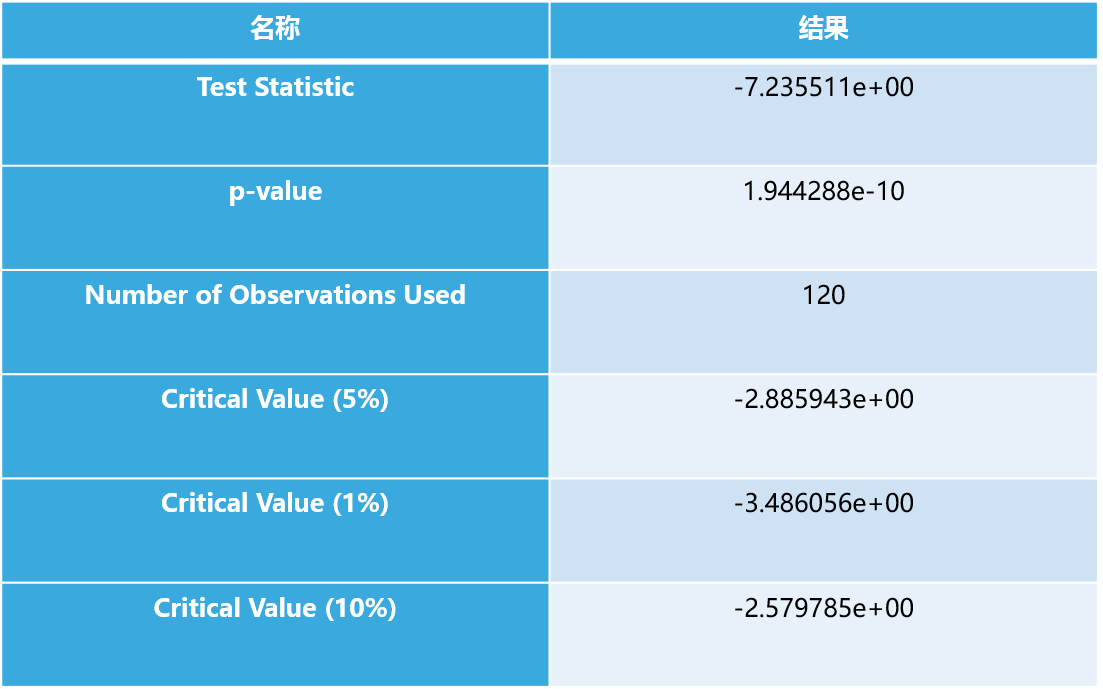
接着是参数的选择。ARMA(p,q)有p,q两个参数。根据自相关图拖尾特征得到q=1,根据偏自相关图的拖尾特征得到p=2。进一步使用AIC准则进行参数选择,AIC越小表明模型越好,使用AIC准则同样得到q=1,p=2。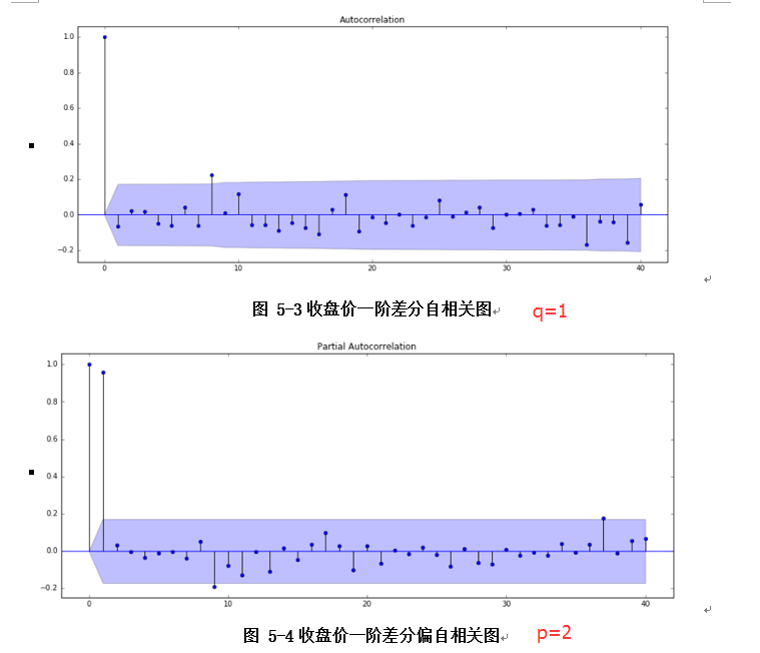
最后使用该模型进行预测。如图是原始数据和预测数据绘制的图。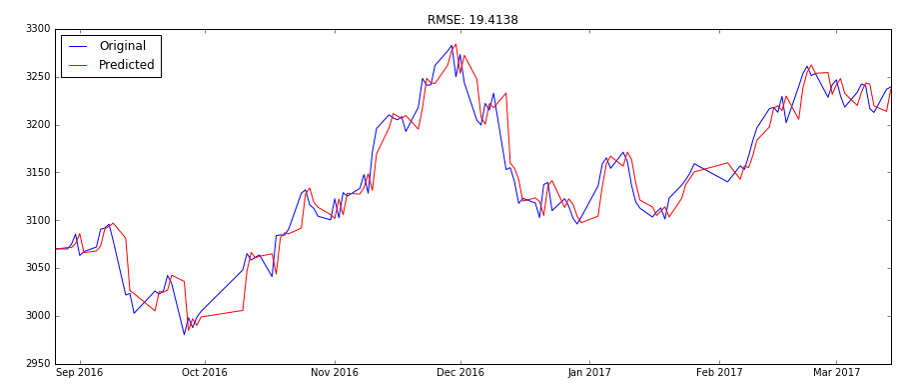
根据均方根误差指标来检验:
$$RMSE=\sqrt{\frac{\sum_{i=1}^n(Y_{obs,i}-Y_{model,i})^2}{n}}$$
发现均方根误差为19.4138,偏大一点,不够理想。相关性分析
我们考虑基于情感看涨指数序列进行改进。
首先进行看涨指数序列和过去股票涨跌幅序列相关性分析。如下图是二者绘制在一起的图,可以看出来趋势挺一致的。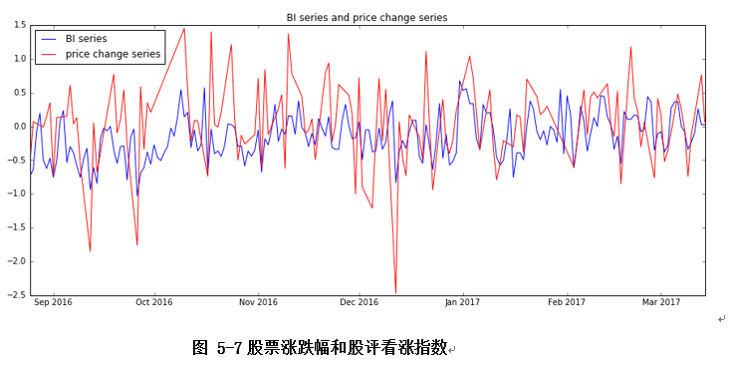
进一步使用pearson相关系数分析:
$$\rho_{X,Y}=corr(X,Y)=\frac{cov(X,Y)}{\sigma_X \sigma_Y}=\frac{E[(X-\mu_X)(Y-\mu_Y)]}{\sigma_X \sigma_Y}$$
得到相关系数为0.677,属于较强相关,因此看涨指数一定程度上反映了股价涨跌幅趋势。
注意:这里的相关性分析的主体是看涨指数序列与过去股票涨跌幅。看涨指数不受未来股票价格走势的影响。这个是下文构建带外生变量的ARIMA模型的前提。基于外生变量的ARIMA模型
进一步我们构建基于外生变量的ARIMA模型。外生变量是指在经济机制中受外部因素影响的变量,可以影响内部变量。股评情感指数可以看作是很多外生变量的综合反映,反映了宏观经济、公司基本面信息、政策、重大事件等诸多股票价格变动的外在因素。
因此本文构建以收盘价为内生变量,股评看涨指数为外生变量的ARIMA模型,如图是拟合结果,均方差误差已经缩小至5.7。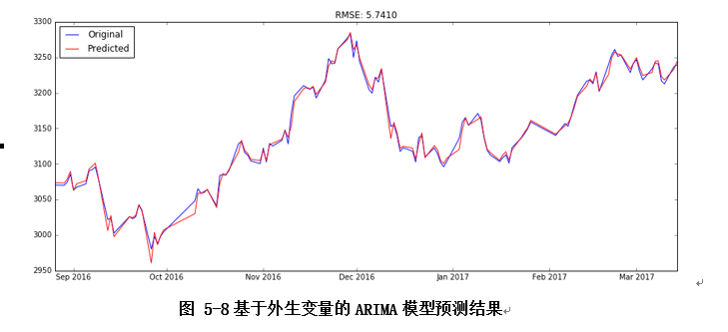
进一步输出模型的AIC值,足够小表明模型稳定。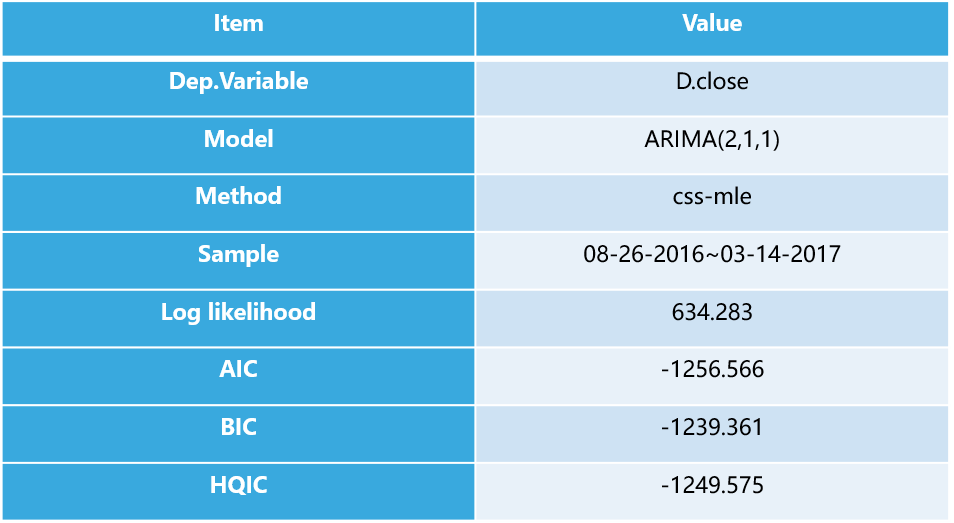
最后对模型进行系数检验,系数标准差很小且z值检验接近于0,可认为显著性水平高,为下面进一步预测奠定基础。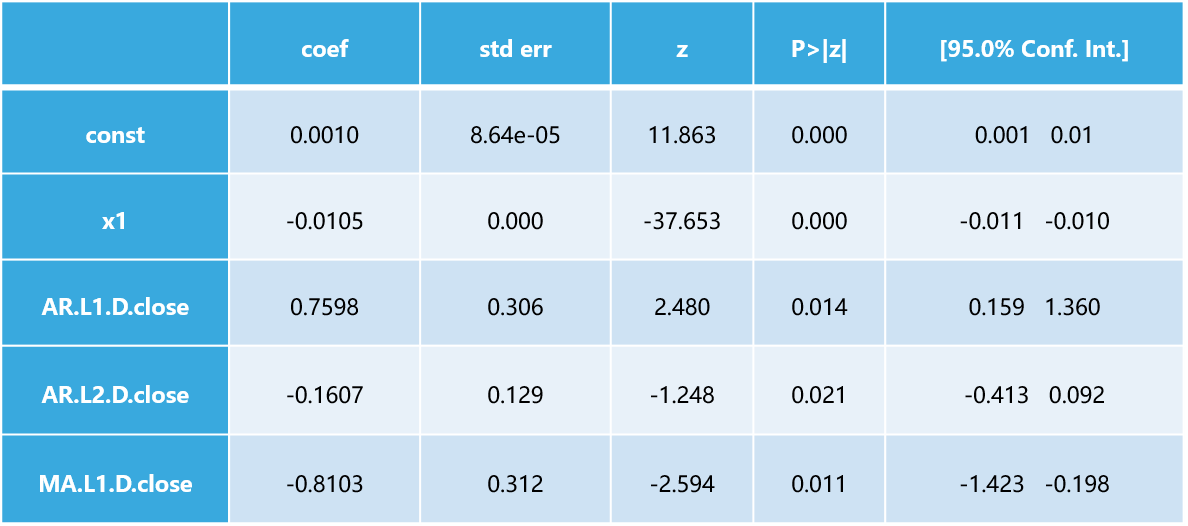
最后我们使用外生变量的ARIMA模型进行未来股价的预测及投资策略研究。本文主要研究短期预测。首先是静态预测,我们使用模型对未来n天数据进行预测,得到该表,可以看到3-15预测很准,3-16号预测数值相差较大,3-17趋势预测错误。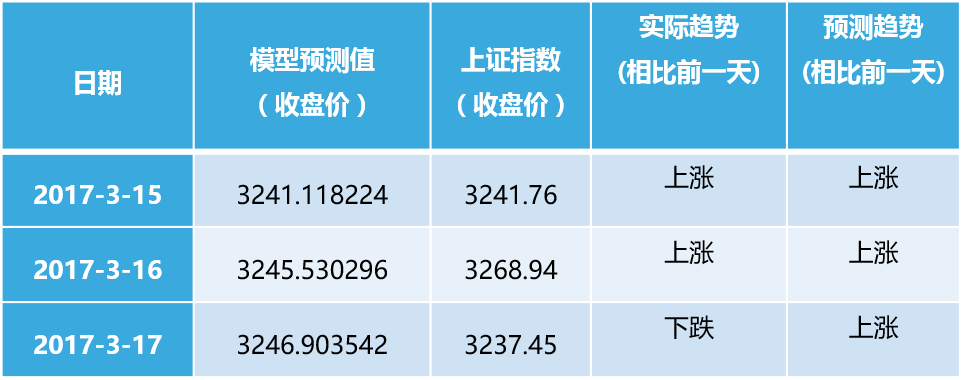
上面我们发现对第二天预测的结果表现不错,我们使用滚动预测,通过添加最新的数据预测第二天的数据,得到该表。发现趋势全部预测正确,数值方面存在一点偏差。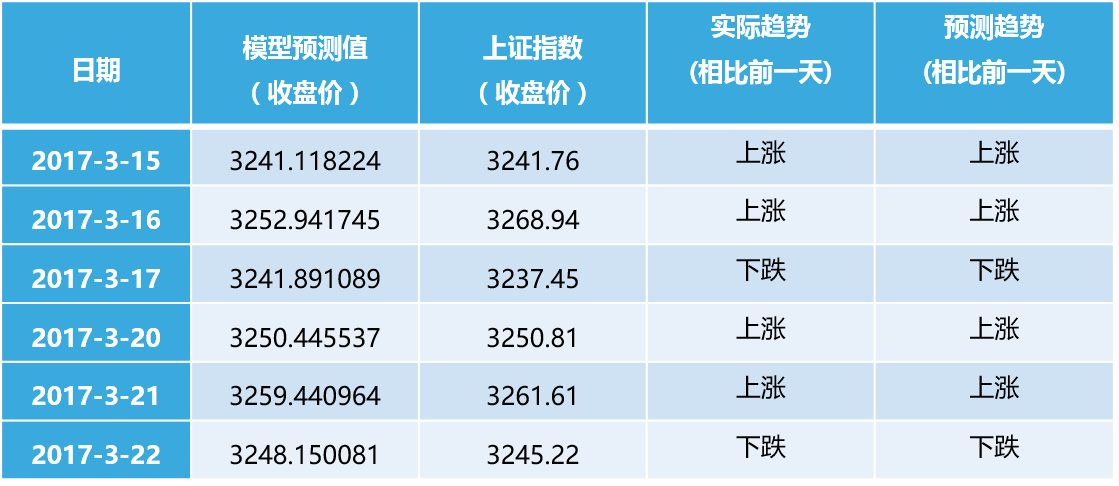
最后总结下投资策略选择,如图是预测的走势和实际走势图,很一致。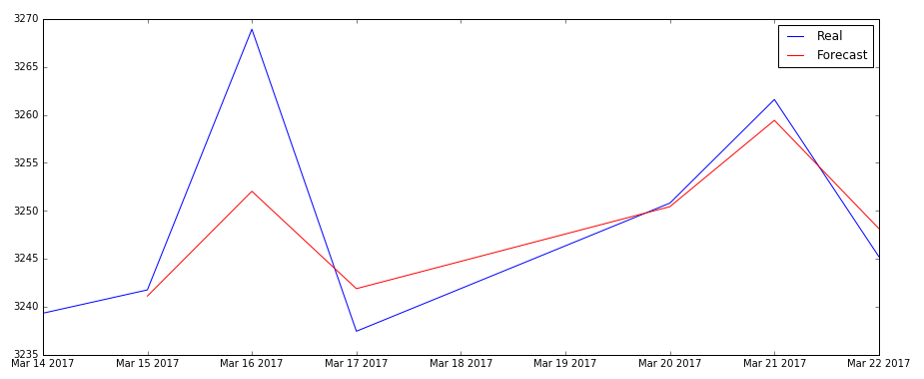
将其和历史数据一起绘制,从整体来看,更加吻合。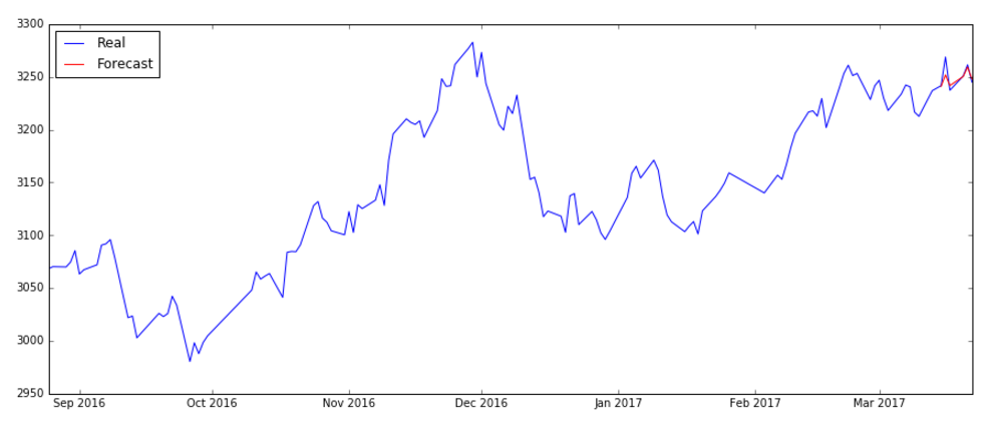
因此既可以根据看涨指数和涨跌幅的强相关性,能够大致得到股票收盘价格的整体趋势变化情况。也可以结合股票历史收盘价格序列以及看涨指数,使用带外生变量的ARIMA模型,来对股票走势进行预测。
总结展望
最后总结展望一下。本文结合股票价格和情感指标,构建时间序列预测模型,对股市短期投资策略提供一定的参考。后续的工作:
- 可以使用算法融合思想提高情感分析的精度。
- 推广研究对象,不局限于上证指数,实现对单一股票的分析。
- 也可以推广研究指标,不局限于收盘价格和看涨指数,可以对开盘价、转手率等进行研究或构建新的情感指标。
- 最后,也可以不局限于短期预测,探索长期预测的模型和方法。


