此次比赛是典型的序列推荐场景中的纠偏问题,即:debiasing of next-item-prediction。模型构建的过程中要重点考虑行为序列和蕴含在序列中的时间信息,位置信息和长短期偏好等。为此,本文提出了一种融合传统协同过滤方法和图神经网络方法的多路召回模型以及集成了GBDT和DIN的排序模型的方案。该方案遵循了推荐系统的主流架构,即召回+粗排+精排。召回方案主要包括了多种改进后的协同过滤方法,即:user-cf、item-cf、swing、bi-graph,以及改进的基于序列的图神经网络SR-GNN[1]方法。这些改进的召回方法能够有效进行数据的纠偏。对每种召回方法,粗排阶段会基于物品的流行度等因素对每个用户的推荐结果进行初步重排,然后将不同方法的Recall的结果初步融合起来。精排方案主要采用了GBDT和DIN[4]方法,会重点挖掘召回特征,内容特征和ID类特征。最后通过集成GBDT和DIN产生排序结果。最终,我们团队Rush的方案在Track B中,full指标第3名,half指标第10名。
方案解析也可参考我的知乎:https://zhuanlan.zhihu.com/p/149061129
目前代码已开源:https://github.com/xuetf/KDD_CUP_2020_Debiasing_Rush
赛题解析
赛题介绍:KDD Cup 2020 Challenges for Modern E-Commerce Platform: Debiasing
主要包括了4个数据集:
- underexpose_user_feat.csv: 用户的特征,uid, age, gender, city。缺失值非常多。
- underexpose_item_feat.csv: 物品的特征,iid, 128维图片向量+128维文字向量。
- underexpose_train_click-T.csv: uid, iid, time, 训练集,记录了用户历史点击行为。
- underexpose_test_click-T.csv: uid, iid, time, 测试集,记录了待预测用户的历史点击行为。赛题方 还给出了要预测的用户下一次发生点击行为时的时间,即:underexpose_test_qtime-T.csv
目标是基于用户历史点击行为,来预测下一次用户会点击的item,即next-item prediction。
根据赛题介绍和对数据集的观察,可以推测主办方是从全量数据里头随机采样部分用户,将这些用户的点击数据作为赛题的数据。在进行数据划分的时候,选取了部分用户的数据作为测试集test,其他用户的数据作为训练集train。对于测试集,将每个用户行为序列的最后一次交互item作为线上测试answer,行为序列去除掉最后一个交互item以外的作为test用户的历史行为数据公开给我们,同时将answer中的user id和query time也公开给我们,即,test_q_time。具体如下图所示:
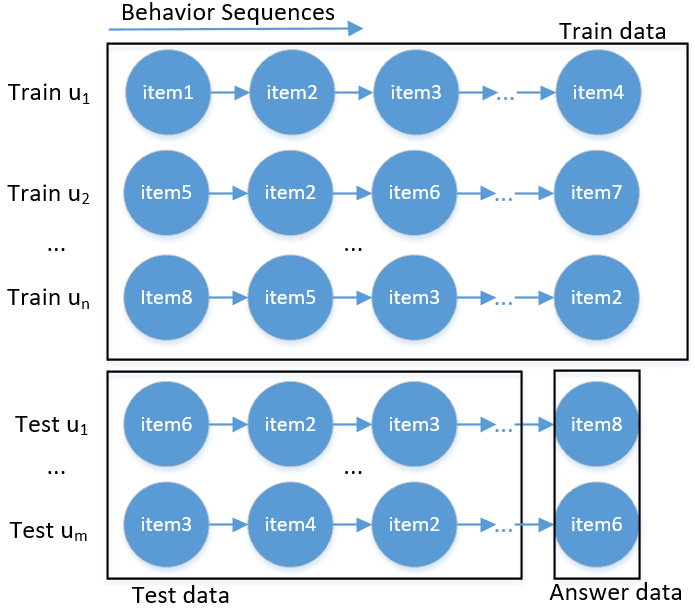
显然,这是典型的序列推荐场景,即next-item-prediction。模型构建的过程中要重点考虑行为序列和蕴含在序列中的时间信息,位置信息和长短期偏好等。
为了保证线上线下数据分布的一致性,验证集划分思路可参考线上数据的划分方式。即,利用线上train训练集进行划分,从train数据集中随机采样1600个用户,将这1600个用户的最后一次交互item作为验证集answer,其它数据作为验证集用户的历史行为数据。具体如下图所示:
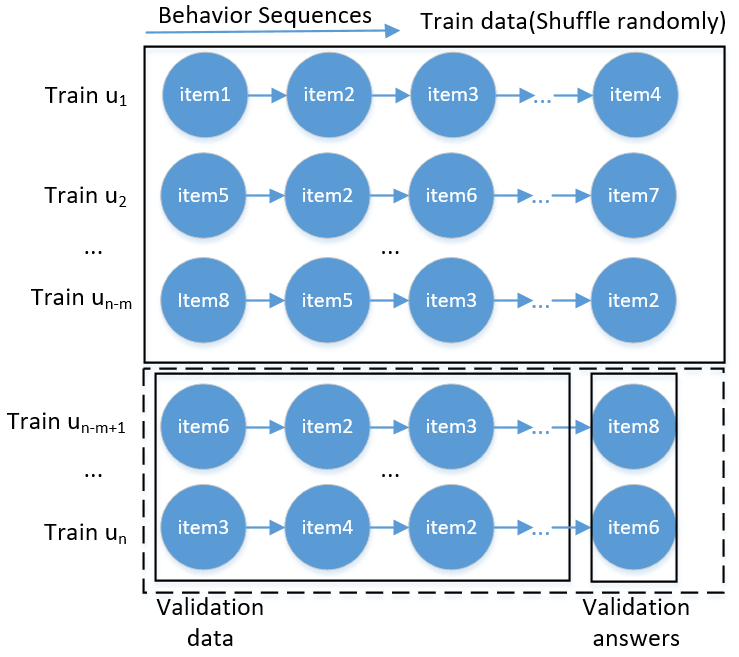
这样的划分,保证了离线环境和线上环境的一致性。上述操作对每个phase都会进行这样的划分过程。
数据分析
几个重要的数据分析观察和结论如下:
经过统计分析,每个阶段的时间范围一致,不同阶段按照时间推移,且不同阶段的时间重叠部分占到了阶段时间区间的3/4,因此会出现当前阶段记录不完全的情况,所以训练模型时需要考虑使用联合多个phase的全量数据训练模型。推测可能是线上打点日志系统的延迟上报,或者主办方对每个阶段的数据,都是从某个较大的时间区间内通过滑动窗口的方式随机采样得到的,因此样本存在较大的时间重叠。
经过验证集上的统计,每个用户的最后一次点击有99%以上是在当前阶段出现过的item,因此利用全量数据时需要将不属于当前phase的item过滤掉,防止item的穿越。
一条相同的点击数据可能会分布在各个阶段之中,重复率占比非常高,因此需要对记录进行去重处理。
item出现的次数呈现典型的长尾分布,在重排阶段需要挖掘长尾物品,如结合物品出现的频次进行纠偏。
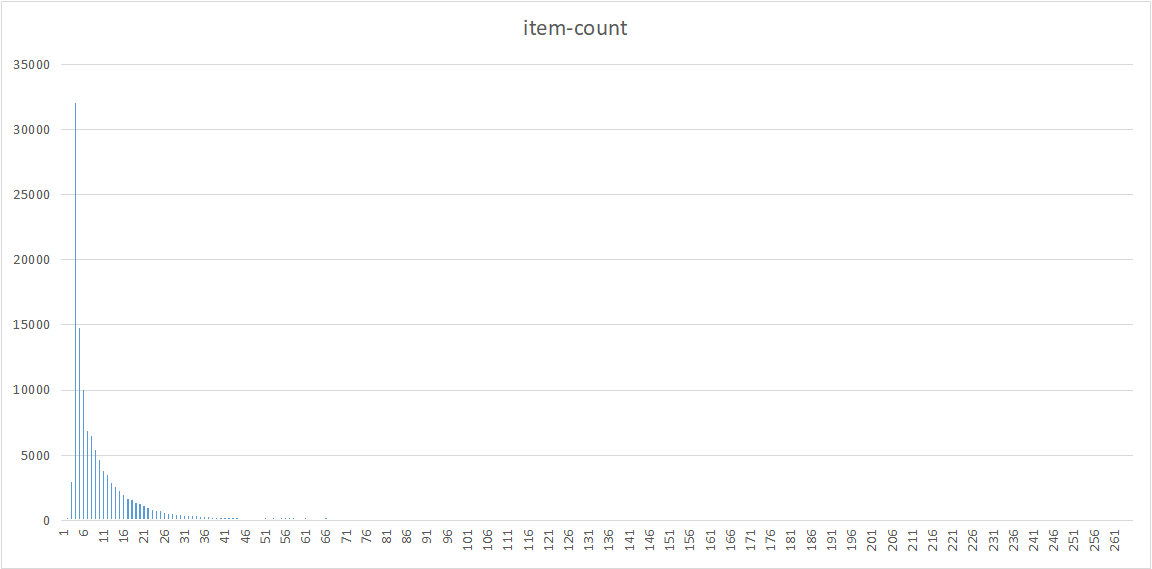
其它的一些分析包括,最后一次点击和倒二次点击之间的内容相似性、基于w2v嵌入的行为相似性等分析。不一一列举。
方案
我们的方案遵循了推荐系统的主流架构,即召回+粗排+精排。召回方案主要包括了多种改进后的协同过滤方法,即:user-cf、item-cf、swing、bi-graph。以及改进的基于序列的图神经网络SR-GNN方法。对每种召回方法,粗排阶段会基于物品的流行度等因素对每个用户的推荐结果进行初步重排,然后将不同方法的Recall的结果初步融合起来。精排方案主要采用了GBDT和DIN方法,会重点挖掘召回特征,内容特征和ID类特征。最终产生的结果是GBDT和DIN的集成。
召回方案
召回训练集构造
经过数据分析,我们发现不同阶段的数据存在明显的交叉,说明了不同阶段之间不存在明确的时间间隔。因此,我们希望充分利用所有阶段的数据。但是直接利用所有阶段的数据会造成非常严重的数据穿越问题。为了保证数据不穿越,我们对全量数据做了进一步的筛选。这是本方案的key points之一。具体包括两点:
1) 对每个用户,根据测试集中的q-time,将q-time之后的数据过滤掉,防止user的行为穿越。
2) 对1) 中过滤后的数据,进一步,把不在当前阶段出现的item的行为数据过滤掉,防止item穿越。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25def get_whole_phase_click(all_click, click_q_time):
'''
get train data for target phase from whole click
:param all_click: the click data of target phase
:param click_q_time: the infer q_time of target phase
:return: the filtered whole click data for target phase
'''
whole_click = get_whole_click()
phase_item_ids = set(all_click['item_id'].unique())
pred_user_time_dict = dict(zip(click_q_time['user_id'], click_q_time['time']))
def group_apply_func(group_df):
u = group_df['user_id'].iloc[0]
if u in pred_user_time_dict:
u_time = pred_user_time_dict[u]
group_df = group_df[group_df['time'] <= u_time]
return group_df
phase_whole_click = whole_click.groupby('user_id', group_keys=False).apply(group_apply_func)
print(phase_whole_click.head())
print('group done')
# filter-out the items that not in this phase
phase_whole_click = phase_whole_click[phase_whole_click['item_id'].isin(phase_item_ids)]
return phase_whole_click
对每个阶段,经过上述步骤后得到筛选后的针对该阶段的全量训练数据,会作为多路召回模型的输入进行训练和召回。
多路召回
多路召回包括了4种改进的协同过滤方法以及改进的图神经网络SR-GNN方法。
Item-CF
参考item-cf [7, 8]的实现,考虑了交互时间信息,方向信息、物品流行度、用户活跃度等因素对模型的影响对模型的影响。
$$
sim(i,j) = \frac{1}{\sqrt{|U_i||U_j|}} \sum_{u \in U_i \cap U_j} \frac{\left(exp(-\alpha * |t_i - t_j|)\right) \times (c \cdot \beta^{|l_i-l_j|-1})}{\log(1+|I_u|)} \tag{1}
$$
其中,
- $\left(exp(-\alpha * |t_i - t_j|)\right)$考察了交互时间差距因素的影响,$\alpha=15000$
- $(c \cdot \beta^{|l_i-l_j|-1})$考虑交互方向的影响,$\beta=0.8$;正向时,即$l_i > l_j$时,$c=1$,否则,即,反向时,$c=0.7$
- $\sqrt{|U_i||U_j|}$考虑了物品流行度的影响,越流行的商品,协同信号越弱。$U_i$即为交互过物品$i$的用户。
- $log(1+|I_u|)$考虑了用户活跃度的影响,越活跃的用户,协同信号越弱,$I_u$是用户$u$的交互过的物品。
上述改进能够有效进行纠偏。
1 | def get_time_dir_aware_sim_item(df): |
User-CF
在原始user-cf基础上考虑了用户活跃度、物品的流行度因素。
$$
sim(u,v) = \frac{1}{\sqrt{|I_u||I_v|}} \sum_{i \in I_u \cap I_v} \frac{1}{log(1+|U_i|)} \tag{2}
$$
1 | def get_sim_user(df): |
Swing
基于图结构的推荐算法Swing [9],将物品的流行度因素也考虑进去。
$$
Sim(i,j)=\frac{1}{\sqrt{|U_i||U_j|}} \sum_{u \in U_i \cap U_j} \sum_{v \in U_i \cap U_j} \frac{1}{\alpha+|I_u \cap I_v|} \tag{3}
$$
1 | def swing(df, user_col='user_id', item_col='item_id', time_col='time'): |
Bi-Graph
Bi-Graph [3, 10] 核心思想是将user和item看做二分图中的两个集合,即:用户集合和物品集合,通过不同集合的关系进行单模式投影得到item侧的物品之间的相似性度量。改进方式:将时间因素、商品热门度、用户活跃度三因素考虑进去。
$$
Sim(i,j)= \sum_{u \in U_i} \sum_{j \in I_u} \frac{\left(\exp(-\alpha * |t_i - t_j|)\right)}{\log(|I_u|+1) \cdot \log(|U_j|+1)} \tag{4}
$$
1 | def get_bi_sim_item(df): |
SR-GNN
SR-GNN [1] 是将GNN用于序列推荐的一种模型,原论文的方法在多个数据集上都表现出较好的性能。SR-GNN通过GGNN能够捕捉序列中不同item之间的多阶关系,同时会综合考虑序列的长短期偏好,尤其是短期的最后一次交互item,天然适用于该比赛的场景。但是直接使用原始论文开源的代码[13],在我们的比赛场景中,召回效果不佳,还不如单个CF方法来的好,因此需要进行改进。
我们将用户的行为记录按时间戳排序,然后对用户序列进行数据增强操作,得到增强后的行为序列后,使用改进的SR-GNN实施召回。具体改进如下:
嵌入初始化
由于训练样本较少,难以对物品嵌入矩阵进行充分的学习,因此不宜使用随机初始化。考虑到比赛提供的数据中包含了物品特征,为此我们使用物品的文本描述和图片描述向量(共256维)对嵌入矩阵进行初始化。这是本方案的重要trick之一。 这个方法能够显著解决某些长尾item的嵌入学习不充分的问题。
1 | # obtain item feat |
这里头有一个小细节,点击数据里存在一些特征缺失的items(未出现在item_feat.csv中),这些items的特征需要做填充。我们采用了局部上下文统计item-item共现关系,并基于共现item的特征做特征填充的方法,这种方式得到的完整item feat对排序过程的提升作用也非常大。
1 | def fill_item_feat(processed_item_feat_df, item_content_vec_dict): |
带有节点权重的消息传播
在SR-GNN中,得到物品序列后,将序列中的物品作为图节点,序列中相邻的物品之间通过有向边连接,最终分别得到入边和出边的邻接矩阵并按行归一化。例如,物品序列$s=[v_1, v_2, v_3, v_2, v_4]$对应的有向图及邻接矩阵$\boldsymbol{M}_{s, out}, \boldsymbol{M}_{s, in}$, 如下所示:
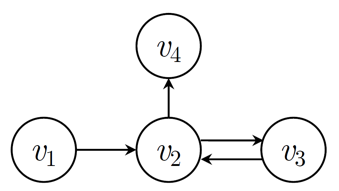
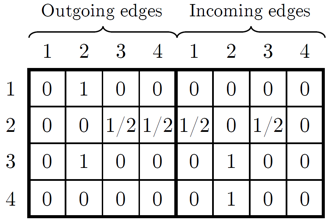
得到序列的图表示后,之后进行GNN处理的,遵循GNN信息传递架构 [12],即:信息构造—传播—更新三个步骤:
1)、 信息构造:针对全部物品设置嵌入矩阵,每个节点对应的物品可用嵌入矩阵的一个行向量$\boldsymbol{e}_i \in \mathbb{R}^d$表示。由于训练集中物品呈长尾分布,对于出现次数较多的物品,我们希望降低它的影响,因此我们设置节点$i$(即对应的物品$i$)的初始权重,
$$
w_i = \frac{1}{\sqrt{\#i / \text{median}}+1} \tag{5}
$$
$\#i$为物品$i$在训练集中出现的次数,$\text{median}$为全部物品出现次数的中位数,最终权重位于(0,1)之间,出现次数较多的物品权重较小,而出现次数较少的物品权重接近1。我们设置权值$w_i$为可学习的参数,因此节点$i$待传播的信息为$w_i \boldsymbol{e_i}$。
2)、 传播:按照连接矩阵进行传播,
$$
o_{s,i}^t = \text{concat}(\boldsymbol{M}_{s, in}^i \boldsymbol{E}^{t-1} \boldsymbol{W}_{in}, \boldsymbol{M}_{s, out}^i \boldsymbol{E}^{t-1} \boldsymbol{W}_{out})+b \tag{6}
$$
此处,$\boldsymbol{E}^{t-1}=[w_1 \boldsymbol{e}_1^{t-1}, …, w_n \boldsymbol{e}_n^{t-1}]$为图中全部节点的信息矩阵,$\boldsymbol{M}_{s, in}, \boldsymbol{M}_{s, out} \in \mathbb{R}^{1 \times n}$分别表示入度矩阵和出度矩阵的$i$行, 我们从入边和出边两个方向传播信息,$o_{s,i}^t \in \mathbb{R}^{2d}$为节点$i$在第$t$步时从邻居节点汇聚得到的信息。$\boldsymbol{W}_{in}, \boldsymbol{W}_{out}, b$为模型可学习的参数。
3)、 更新:根据节点自身的信息和来自邻居的信息,更新节点的信息。这里使用GRU进行结点信息的更新:$\boldsymbol{e_i}^t=GRU(o_{s,i}^t, \boldsymbol{e}_i^{t-1}) + \boldsymbol{e}_i^0$,此处,我们采用了残差连接。
以上过程可循环进行$R$步,最终每个节点可获取到它的$R$阶邻居的信息。我们的方案中,$R=2$。
位置编码
用户的行为受最后一次交互影响较大,为了强化交互顺序的影响,我们增加了位置编码矩阵$P \in \mathbb{R}^{k \times d}$,$k$为位置数量,我们从后向前编码,最后一次交互的物品位置为1,上一次为2,以此类推。通过GNN更新后的节点向量和位置编码向量相加:
$$
\boldsymbol{e_i} \leftarrow \boldsymbol{e}_i + \boldsymbol{p}_i \tag{7}
$$
$\boldsymbol{p}_i$为节点$i$的位置编码向量。我们设置$k=5$,对于倒数第5个物品之前的物品,它们的位置均为5。
序列级别的嵌入表征
这里需要汇聚图中全部节点向量,得到一个图级别的输出作为序列的嵌入表征。考虑到最后一次行为的重要性,我们使用了加权平均池化的汇聚方式,即:
$$
\boldsymbol{s}_h = w \boldsymbol{e}_T + (1-w) \sum_{i=1}^{T-1} \frac{\boldsymbol{e_i}}{T-1} \tag{8}
$$
$\boldsymbol{e}_T$为序列最后一个item的嵌入表示,这里我们对序列中最后一个物品之前的物品向量进行平均池化,之后和最后一个物品向量按照权重$w$进行加权,得到序列的表示。$w$是可学习的参数。
预测和损失函数
我们对序列向量及物品向量进行L2归一化:
$$
\boldsymbol{s}_h = \frac{\boldsymbol{s}_h}{||\boldsymbol{s}_h||_2}, \boldsymbol{e}_i = \frac{\boldsymbol{e}_i}{||\boldsymbol{e}_i||_2} \tag{9}
$$
之后通过点积对物品进行打分:
$$
\hat{y}_i = \text{softmax}(\sigma \boldsymbol{s}_h^T \boldsymbol{e}_i) \tag{10}
$$
$\sigma$为超参数,我们设为10,来进一步拉大高意向item和低意向item之间的差距。这实际上是通过余弦相似度对物品进行打分,这些在参考文献[2]中有具体描述。模型的损失为预测概率的多分类交叉熵损失。
产出多路召回结果
上述协同过滤方案实际上分为了Item-based,即:item-cf、swing、bi-graph和User-based,即user-cf。在具体进行推荐时,我们封装了基于item的产生召回结果的流程和基于user的产生召回结果的流程。
Item-based
item-based的方法在进行推荐的时候,会利用用户的历史行为item,计算历史行为item最相似的Top-K个item推荐给用户。在计算相似性时,同样会利用前文提到的策略,即:根据交互时间进行指数衰减;根据交互方向进行幂函数衰减。同时,我们还利用了物品的内容特征,即,利用Faiss [11] 计算了item-item之间的内容相似性权重,最后,每个item的得分=召回方法的分数 $\times$ 时间权重 $\times$ 方向权重 $\times$ 内容权重。每种方法产生Top-200个召回结果。
1 | def item_based_recommend(sim_item_corr, user_item_time_dict, user_id, top_k, item_num, alpha=15000, |
User-based
User-based进行推荐时,会将相似用户的历史感兴趣item推荐给目标用户。但是这里面的一个问题是,没有利用到目标用户本身的行为序列信息。我们做了改进,会计算相似用户历史感兴趣item和目标用户本身行为序列中的item之间的相似性,计算相似性时,同样会利用时间权重和方向权重进行衰减。产生Top-200个召回结果。
1 | def user_based_recommend(sim_user_corr, user_item_time_dict, user_id, top_k, item_num, alpha=15000, |
SR-GNN
我们还对数据进行了增强操作。对每个用户的交互序列进行截断,变成多条的交互序列。然后使用模型进行训练并产出结果。具体使用时,我们使用了两套参数(原始论文实现+改进版实现)训练SR-GNN,每套参数对应的模型根据公式(10)各产生Top-100个召回结果,共Top-200个召回结果。
1 | # Train |
在A榜中,单模型的SR-GNN效果已超过4种改进后的CF融合后的效果。
最终,每个用户产生了1000个召回结果。
粗排方案
粗排阶段主要基于这样的观察,我们的模型Top 100的hit-rate指标远高于Top 50,说明可能很多低流行度的物品被我们的模型召回了,但是排序较靠面,因此需要提高低频商品的曝光率,以消除对高频商品的偏向性。具体而言,对每个阶段进行召回时,本方案会统计该阶段内的物品出现的频次,然后根据该频次以及召回方法计算的item-item相似性分数,对相似性分数进行调整。这是本方案的key points之一,能够在基本不影响full的情况下,有效提高half。不同于其他开源的方案,我们在召回后进行re-rank,而不是在精排后进行re-rank。
本方案考虑加入频率因素,具体方法包括:
(1) 首先将频率作为一个单独的考量标准,为了初步鉴定频次的打压效果并尽量排除其他权重对其干扰,直接将召回分数除以物品出现的频次,初步鉴定对half有比较明显的提升,但是会显著降低full指标。
(2) 进一步,经过对item频次进行数据分析,item频率的分布呈现长尾效应,因此对于这些高频但极少数的item,考虑使用幂函数削弱打击的效果。采用的打压函数分段函数如下所示:
$$
\begin{split}
f(c) &= \log(c + 2), c < 4 \\
f(c) &= c, 4 \leq c < 10 \\
f(c) &= c^{0.75} + 5.0, c > 10
\end{split}
$$
其中,$c$为item出现在目标pahse中的频次,则新的分数为,$s_i^{*} = s_i / f(c_i)$。
(3) 考虑到不同活跃度的用户对于不同频率的物品的倾向性不同,越活跃的用户越倾向于点击低频的商品,因此对高活跃度的用户,需要提高高频item打压程度;对低活跃度的用户,提高对于低频率物品的打压程度。对于不同用户进行区分的策略在几乎不影响ndcg-full同时,有效提高了ndcg-half。
1 | def re_rank(sim, i, u, item_cnt_dict, user_cnt_dict, adjust_type='v2'): |
不同的召回方法得到的分数会经过上述步骤进行分数调整粗排,然后需要将不同召回模型初步融合在一起,我们的方法是,每种方法对每个用户产生的推荐结果先进行打分的最小最大归一化;然后求和合并不同方法对同一个用户的打分结果。
注:实际上,我们临近截止日期的时候对召回做了小修改,full指标上升了一些,half下降了一些,导致覆盖了原本最好的half结果,没来的及对改进后的召回重排策略进行精排。最终导致目前线上最终的成绩是仅通过上述召回方案得到的。而在我们所有的提交记录中,我们最好的half指标的成绩是该召回方案和下文即将描述的排序方案产生的。笔者认为,如果对改进后的重排策略进行精排的话,我们的分数应该还会更高。
精排方案
到目前为止,B榜的最终成绩(full rank 3rd, half rank 10th)仅由上文提到的召回+粗排即可得到。精排方案在A榜的时候会有full会有0.05+的提升;half会有0.01+的提升。B榜由于时间问题没来得及对改进后的召回方案做排序并提交。如果你有兴趣可以接着往下阅读。
精排方案主要由GBDT和DIN方法组成。这里面最重要的步骤来自于训练样本的构造和特征的构造。其中,训练样本的构造是重中之重,个人认为也是本次比赛排序阶段最大的难点所在。
训练样本构造
排序方案的训练样本构造我们采用了序列推荐的典型构造方案,即:滑窗方式构造训练样本。为了保证训练时和线上预测时的数据一致性,我们以行为序列中的1个item为滑窗步长,共滑动了10步。具体步骤即:对每个用户的行为序列$s=[i_1, i_2, …, i_n]$,从倒数第1个item开始,即:$i_n$为ground truth item, $i_1 \sim i_{n-1}$的通过我们的召回模型来计算item pair相似性,并为第$n$个位置的next-item产生召回结果;滑动窗口往左滑动1步,即:$i_{n-1}$为ground truth item, $i_1 \sim i_{n-2}$的通过我们的召回模型来计算item pair相似性,并为第$n-1$个位置的next-item产生召回结果;以此类推,共滑动10步。这种方式的缺点在于,计算复杂度非常高。因为每次滑动,都需要进行相似性的计算,并用训练集中所有的用户进行召回。目前笔者还不清楚这种方式是否是最优的构造方法(应该不是最优的),希望后面看看其他队伍的开源开案,学习学习。
1 | def sliding_obtain_training_df(c, is_silding_compute_sim=False): |
构造样本标签时,将召回结果中,命中了的用户真实点击的item作为正样本(即:不包括召回结果中未命中,但是用户真实点击的item,好处是能够把召回分数特征等送到模型中进行排序),然后随机负采样部分item作为负样本,负样本的策略以user和item侧分别入手,按照比例进行负采样,最终采样到的负样本: 正样本比例 约等于 10:1。
具体实现时,我们会对每个阶段的数据中的所有用户,分别进行召回并构造样本和标签。上述得到的数据格式即:user id, item id, hist item sequence, label,即: 用户id,目标物品id,用户历史交互item序列,标签。
特征提取
重要的特征主要涉及召回时的特征以及目标item和用户历史item之间的各种关联性,如内容关联性、行为关联性等。
召回特征
召回特征主要包括了:
- 用户对目标item的分数,即多种recall方法融合并粗排后的分数;
- 目标item和历史item的相似性,我们只选择历史交互序列中的最后3个物品的内容特征进行计算相似性。
内容特征
待预测的目标物品原始的内容特征。
用户历史交互序列中的item的内容特征,根据交互位置顺序进行加权计算后的兴趣向量。
- 用户兴趣向量和物品内容向量之间的内容相似性分数。
- word2vec对训练集中的用户hist item sequences进行训练,然后得到的每个物品的w2v向量。
- 每个待预测的目标物品的w2v向量和用户历史交互的item的w2v向量之间的相似性分数。
ID特征
这部分特征主要供深度学习模型DIN使用。包括:
- user id特征
- item id特征
- 用户历史行为序列中的 item id特征 (和item id 特征共享嵌入)
比较遗憾的是,本次比赛user侧的特征由于缺失值过多,我们没有花太多时间在user侧的特征提取,比如像item侧的特征一样,进行缺失值预测、补全等。
排序模型
排序模型包括了两个,1个是GBDT,这里我们采用了LightGBM [5] 中的learning to rank方法LGBMRanker进行排序。另一个是DIN,这里采用了DeepCTR [6] 库中的DIN实现版本。对于DIN,我们利用了物品的内容特征对item的嵌入进行了初始化;利用用户历史行为序列中的item的加权后的兴趣向量对user的嵌入进行了初始化。
- GBDT实现:
1 | def lgb_main(train_final_df, val_final_df=None): |
- DIN实现:
1 | def din_main(target_phase, train_final_df, val_final_df=None): |
模型集成
最后,我们将GBDT预测的分数和DIN预测的分数融合起来。具体而言,每个方法的预测概率会先进行user-wise的归一化操作;然后两个方法归一化后预测的概率值进行相加融合。最后按照融合后的分数进行排序,并产生最终的Top 50结果。在A榜的时候,lgb对召回结果对full指标的提升效果大概都在0.02+;但是融合后的LGB+DIN,提升效果可达到0.05+。对half指标的提升略微少了一些,可能原因在于模型过于关注召回得到的sim等特征,对debiasing相关的特征挖掘比较少。
1 | def norm_sim(sim_df, weight=0.0): |
总结
对本文方案的key points作一个总结:
- 召回训练集的构造,如何使用全量数据进行训练,user侧和item侧都需要防止穿越。这个提高非常显著,说明数据对于结果的影响非常大。
- CF中的改进点能够有效进行纠偏,包括,交互时间、方向、内容相似性、物品流行度、用户活跃度等。这个提高也很显著,和赛题Debiasing主题契合。
- SR-GNN基于序列推荐的图神经网络模型,完美契合本次比赛序列推荐场景,捕捉item之间的多阶相似性并兼顾用户长短期偏好。另外,我们基于SR-GNN的改进点,使用内容特征进行嵌入初始化、根据频次引入结点权重 (为了纠偏)、位置编码 (强化短期交互互影响力)、嵌入归一化、残差连接、sequence-level embedding的构建等都带来了提升。SR-GNN召回方案的提升效果达到0.05+。
- 粗排考虑了频次,提高低频商品的曝光率,以消除召回方法对高频商品的偏向性,对half指标的提升很显著。
- 排序特征的构建,包括召回特征、内容特征、历史行为相关的特征、ID特征等。
- 排序模型集成,LGB和DIN模型的融合,对最终的指标有比较高的提升。
参考文献
[1] Wu S, Tang Y, Zhu Y, et al. Session-based recommendation with graph neural networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 346-353.
[2] Gupta P, Garg D, Malhotra P, et al. NISER: Normalized Item and Session Representations with Graph Neural Networks[J]. arXiv preprint arXiv:1909.04276, 2019.
[3] Zhou T, Ren J, Medo M, et al. Bipartite network projection and personal recommendation[J]. Physical review E, 2007, 76(4): 046115.
[4] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1059-1068.
[5] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree[C]//Advances in neural information processing systems. 2017: 3146-3154.
[6] DeepCTR, Easy-to-use,Modular and Extendible package of deep-learning based CTR models, https://github.com/shenweichen/DeepCTR
[7] A simple itemCF Baseline, score:0.1169, https://tianchi.aliyun.com/forum/postDetail?postId=103530
[8] 改进青禹小生baseline,phase3线上0.2, https://tianchi.aliyun.com/forum/postDetail?postId=105787
[9] 推荐系统算法调研, http://xtf615.com/2018/05/03/recommender-system-survey/
[10] A Simple Recall Method based on Network-based Inference, score:0.18 (phase0-3), https://tianchi.aliyun.com/forum/postDetail?postId=104936
[11] A library for efficient similarity search and clustering of dense vectors, https://github.com/facebookresearch/faiss
[12] CIKM 2019 tutorial: Learning and Reasoning on Graph for Recommendation, https://next-nus.github.io/
[13] Source code and datasets for the paper “Session-based Recommendation with Graph Neural Networks” (AAAI-19), https://github.com/CRIPAC-DIG/SR-GNN
也欢迎关注我的公众号”蘑菇先生学习记“,更快更及时地获取推荐系统前沿进展!


