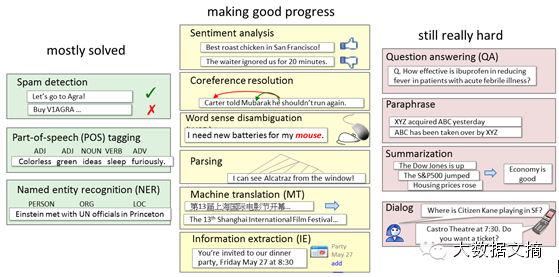
神经网络的入门知识参见神经网络(系列1)
本文主要对神经网络进行深入,探讨神经网络模型的学习。
代价函数
首先引入一些便于稍后讨论的新标记方法:
假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络层数,\(S_l\)表示每层的neuron个数(\(S_L\)表示输出层神经元个数),(\(S_L\)代表最后一层中处理单元的个数。
将神经网络的分类定义为两种情况:二类分类和多类分类:
二类分类:\(S_L=1\), y=0 or 1表示哪一类;
K类分类:\(S_L=K\), \(y_i = 1\)表示分到第i类;(K>2)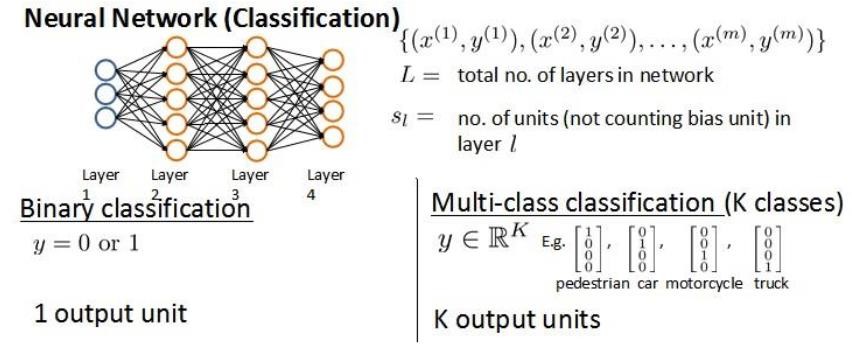
我们回顾逻辑回归问题中我们的代价函数为:
$$J(θ)=-\frac{1}{m}\sum_{i=1}^m\left(y^{(i)}log(h_θ(x^{(i)}))+(1-y^{(i)})log(1-h_θ(x^{(i)}))\right)+\frac{\lambda}{2m}\sum_{j=1}^nθ_j^2$$
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量y,但是在神经网络中,我们可以有很多输出变量,我们的\(h_θ(x)\)是一个维度为K的向量,并且训练集中的因变量也是同样维度的一个向量,因此代价函数会比逻辑回归更加复杂一些,为:
$$J(\Theta)=-\frac{1}{m}\Big[\sum_{i=1}^m\sum_{k=1}^K\left(y_k^{(i)}log((h_\Theta(x^{(i)}))_k)+(1-y_k^{(i)})log(1-(h_\Theta(x^{(i)}))_k)\right)\Big] \\\ + \frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{l+1}}(\Theta_{ji}^{(l)})^2$$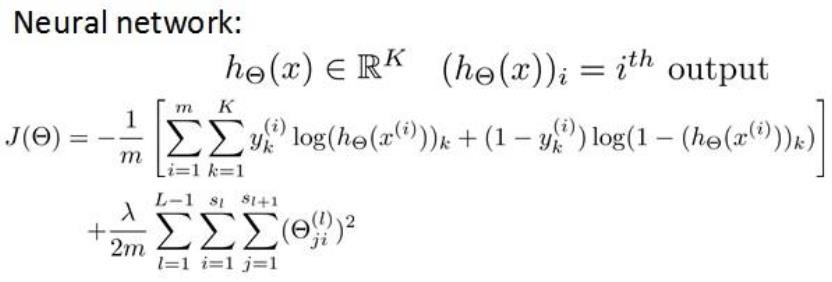
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真实情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出K个预测,基本上我们可以利用循环,对每一行特征都预测K个不同结果,然后在利用循环在K个预测中选择可能性最高的一个。
注意:j循环所有的行(由\(s_{l+1}\)层的激活单元数决定,l+1整体是下标),循环i则循环所有的列,由该层(\(s_l\)层)的激活单元数所决定。